 图 1 差异性蒸馏集成训练流程
Fig.1 Differential distillation ensemble training process
图 1 差异性蒸馏集成训练流程
Fig.1 Differential distillation ensemble training process
ZHANG Ximin,QIAN Yaguan,MA Danfeng,et al.Differential deep ensemble learning based on knowledge distillation[J].Journal of Zhejiang University of Science and Technology,2021,33(03):220-226.[doi: 10.3969/j.issn.1671-8798.2021.03.007]

随着深度学习的兴起,深度神经网络模型在很多领域得到了应用,如图像识别[1-3]、语音识别[4]、自然语言处理[5-6]等。借助残差连接[2,7]及批处理归一化[8]等新兴算法来配合云计算中心强大的图形处理器(graphic processing unit,GPU),训练出的深度神经网络模型的层级可以达到数千层。模型规模的扩大虽然能够带来运算性能上的提升,但是难以训练,需要占用大量的数据和计算资源。计算量的大幅度提升意味着对硬件计算能力、内存带宽及数据存储的要求更高。这给深度神经网络模型在边缘智能设备上的部署带来了极大的挑战,使得深度神经网络模型难以应用到嵌入式设备中(如人脸识别系统[9]、自动驾驶汽车[10]等)。为了适应移动计算、边缘计算,缩小模型规模,研究人员开始研究模型的压缩方法与策略。
Hinton等[11]提出了知识蒸馏方法,通过将结构复杂的深度学习模型(教师模型)知识,迁移到结构简单的深度学习模型(学生模型)上,以实现深度学习模型的压缩。但是,学生模型的分类准确率低于教师模型,这意味着模型压缩以模型的分类性能为代价。如何在缩小模型规模的同时保持模型泛化能力成为一个具有挑战性的问题。为了解决这个问题,笔者提出一种基于知识蒸馏的差异性深度集成学习,将知识蒸馏与差异性集成相结合,在知识蒸馏压缩模型的基础上,使用集成来提高模型的分类性能。由于集成性能取决于成员模型间的差异性[12],故从模型层面提出新的集成训练方法,构造新的损失函数,即添加余弦相似度作为衡量模型差异性的正则化项。此外,在模型集成的过程中,通过最小化损失函数来增强成员模型间的预测差异性。
1 蒸馏集成相关知识1.1 知识蒸馏深度神经网络模型是一种模仿人脑神经网络结构的深层学习模型,模型的输出可用f(x,θ)表示。x是输入变量,θ是模型参数。f(x,θ)∈Rm是一个m维概率向量,表示m个类的置信度。模型的最后一层采用Softmax层,定义为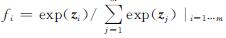 ,其中z是最后一个隐藏层的输出向量。模型最后的预测标签
,其中z是最后一个隐藏层的输出向量。模型最后的预测标签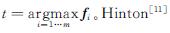 认为模型获得的知识不仅存储于K个模型的模型参数集{θi}i∈K中,还表现在模型的输出概率分布(f1,f2,…,fm)中。基于这个观点,蒸馏就是从教师模型中提取类之间的概率结构,生成软标签,通过训练迁移知识到学生模型中。
认为模型获得的知识不仅存储于K个模型的模型参数集{θi}i∈K中,还表现在模型的输出概率分布(f1,f2,…,fm)中。基于这个观点,蒸馏就是从教师模型中提取类之间的概率结构,生成软标签,通过训练迁移知识到学生模型中。
知识蒸馏使用温度T调节x在教师模型f1(x,θ)上的输出概率向量ysoft,称为x的软标签:

式(1)中: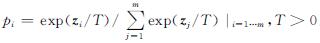 。利用x的硬标签y与软标签ysoft同时对学生模型f2(x,θ)进行蒸馏训练:
。利用x的硬标签y与软标签ysoft同时对学生模型f2(x,θ)进行蒸馏训练:
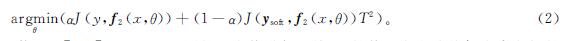
式(2)中:J(·)为代价函数; α∈[0,1]。可设置不同的温度值进行训练,T的值越大意味着每个类之间的概率差异性越小。
1.2 模型集成在单个模型的泛化能力提升有限的情况下,把多个弱模型集成起来。由于多个局部极小值的存在,多个不同的模型会实现不同的概率分布,因此将单独训练的模型输出组合起来可提高性能,更好地泛化数据[13],可获得比单个模型性能更强的分类模型[14]。常见的模型集成方法有简单平均法和带权平均法。简单平均法中的集成模型

带权平均法中的集成模型

式(3)~(4)中:f(i)(x)为成员模型; K为成员模型个数; wi∈[0,1]。
参考文献[15-16]的研究结果,本研究采用简单平均法进行集成。
2 基于知识蒸馏的神经网络模型集成2.1 直接蒸馏集成知识蒸馏作为典型的模型压缩方法,其最终目的是缩小模型规模,从而减少对计算资源的需求。但由于学生模型的规模变小,与教师模型相比分类性能更低,这意味着模型压缩以减弱模型的分类性能为代价。为了解决这个问题,考虑将多个学生模型进行直接集成,以更好地泛化数据。一方面,由于集成性能取决于成员模型间的差异性,成员模型间的差异性大就能获得比单个成员模型性能更强的分类模型[17]; 另一方面,蒸馏后的学生模型会减小成员模型间的差异性[15]。可见,提升单个学生模型的蒸馏效果与提升直接蒸馏集成模型的泛化性能之间产生了矛盾[13]。对此,我们提出一种基于差异性蒸馏集成的训练方法,通过进一步增加模型间的预测差异性来实现更好的蒸馏模型集成效果。
2.2 差异性蒸馏集成模型集成的性能主要取决于成员模型之间的差异性[12]。因此,增大成员模型之间的差异性是提高模型集成性能的有效方法。本文提出差异性蒸馏集成方法,保持单个模型蒸馏效果的同时,提高集成效果。为了保持模型的准确性,每个成员模型必须得到正确的输出。
使用余弦相似度来度量成员模型之间的差异性。假设f(i)=(f(i)j)mj=1为第i个成员模型的输出概率分布,f(i)=(f(i)j)mj=1,j≠t为f(i)除正确类t以外的概率分布。梯度Δxf(i)为f(i)对输入变量x的预测方向。如果Δxf(1)与Δxf(2)的方向一致,那么成员模型f(1)与f(2)会以相似的方式变化,即f(1)与f(2)对x有相似的预测。显然f(1)与f(2)之间是一种低效集成。为了增强成员模型之间的差异性,需增大Δxf(1)与Δxf(2)间的差异性。
对于两个成员模型,使用余弦相似度来度量两者的差异性:
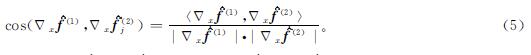
式(5)中:cos(·)∈[-1,1]。若cos(Δxf(1),Δxf(2))=-1,则Δxf(1)与Δxf(2)完全不一致,f(1)与f(2)对除正确类t以外的预测差异性达到最大。对于多个成员模型,可以取最大的余弦相似度:

最大化M({Δxf(i)}Ki=1)能够增大成员模型对不同类别的预测差异性。然而,式(6)是一个非光滑函数,无法使用一阶优化方法,因此我们对式(6)采用LogSumExp函数进行光滑逼近:
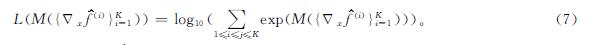
如果K个成员模型的L(M({Δxf(i)}Ki=1))较小,那么成员模型对不同类别的预测差异性就较大,所集成训练的模型F(x)则具有更强的泛化能力。为了使集成模型具有较小的L(M({Δxf(i)}Ki=1)),将L(M({Δxf(i)}Ki=1))作为正则化项加入集成模型的交叉熵损失函数中:
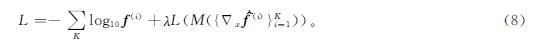
式(8)中:λ为超参数控制在训练过程中L(M({Δxf(i)}Ki=1))的权重,λ值越大,{fi}i∈K的差异性就越大。因此,差异性集成训练转化为如下优化过程:

式(9)中:θ={θk}k∈K为所有成员模型的参数。差异性蒸馏集成训练流程如图1所示。
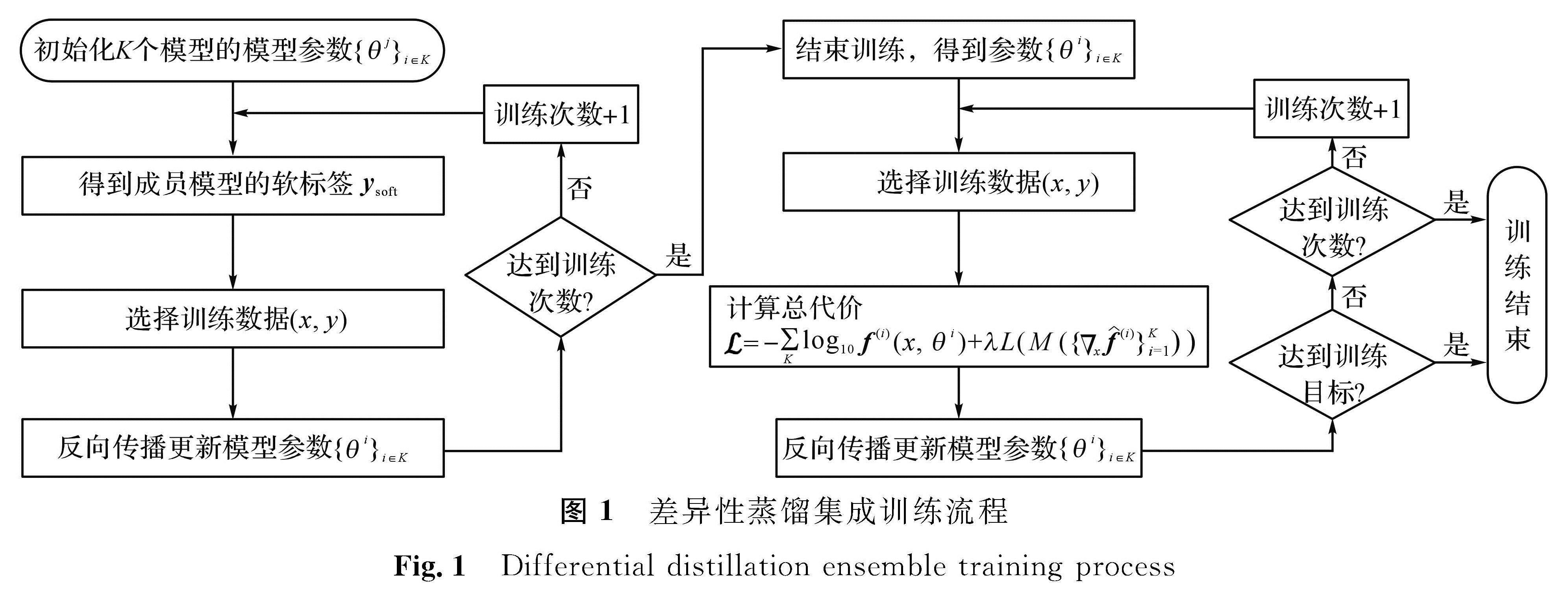
图1 差异性蒸馏集成训练流程
Fig.1 Differential distillation ensemble training process
3 试验结果3.1 数据集与网络结构
本文试验数据集采用MNIST(Mixed National Institute of Standards and Technology)[18]和CIFAR10(Canadian Institute for Advanced Research)[19]。MNIST是一个被广泛应用于机器学习性能测试的手写体数据集,由从数字0到9的10个类组成,共计70 000张手写数字图像,包括60 000张图像作为训练数据及10 000张图像作为测试数据,每个图像为2 828像素的单通道灰度图像。CIFAR10数据集由10个类60 000张大小为3 232像素的三通道彩色图像组成,包括50 000张训练图像和10 000张测试图像。
在MNIST数据集上训练LeNet[20]教师模型,设置最小批次大小为128,经过50个批次的训练后,达到98.79%的分类准确率。在CIFAR-10数据集上训练AlexNet[21]教师模型,设置最小批次大小为40,经过70个批次的训练后达到76.97%的分类准确率。教师模型和学生模型的LeNet和AlexNet网络结构分别见表1和表2。另外,两个模型使用RMSProp(root mean aquare prop)优化算法[22]训练网络,初始学习率η设置为0.000 1,迭代次数设置为3 000次。
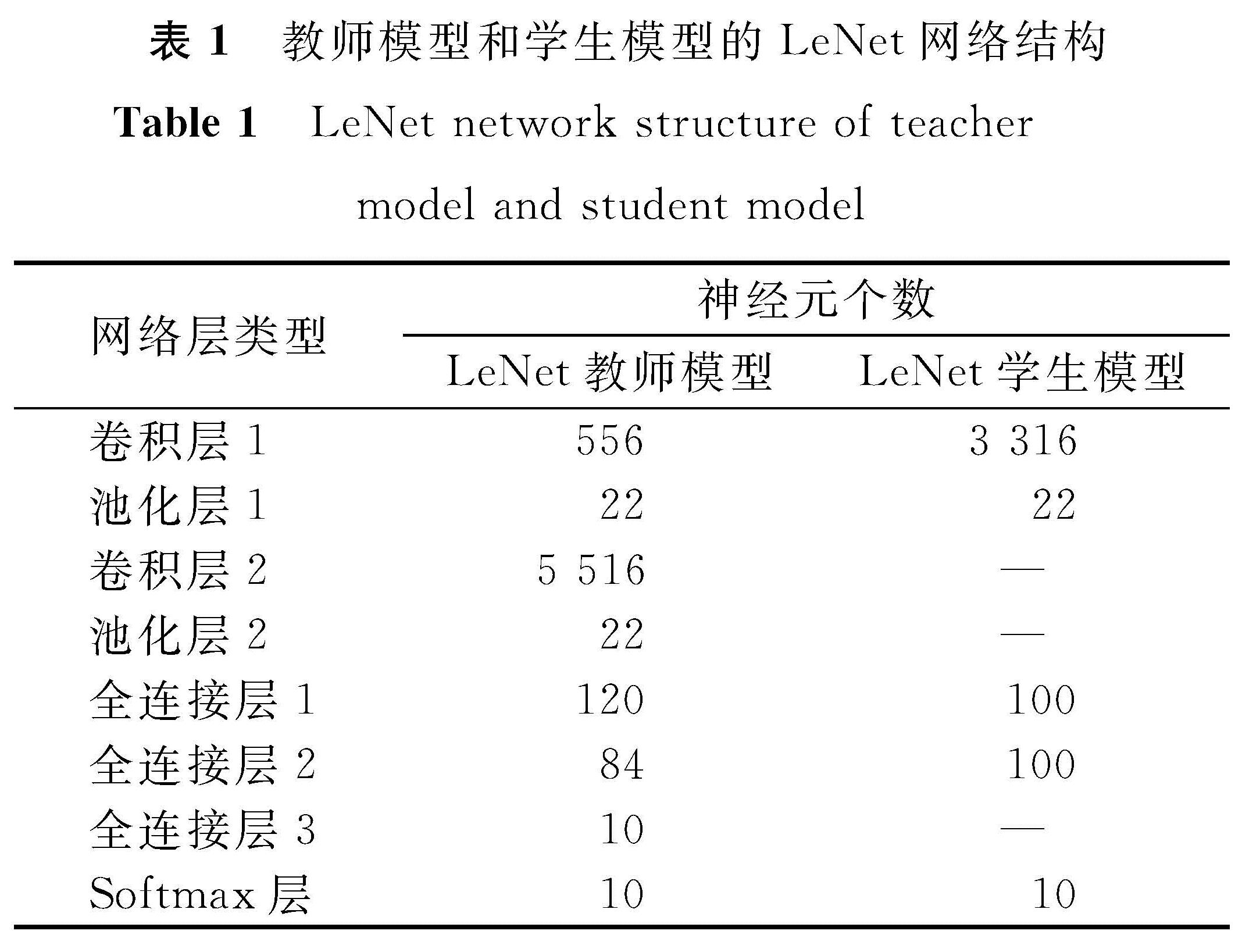
表1 教师模型和学生模型的LeNet网络结构
Table 1 LeNet network structure of teacher model and student model
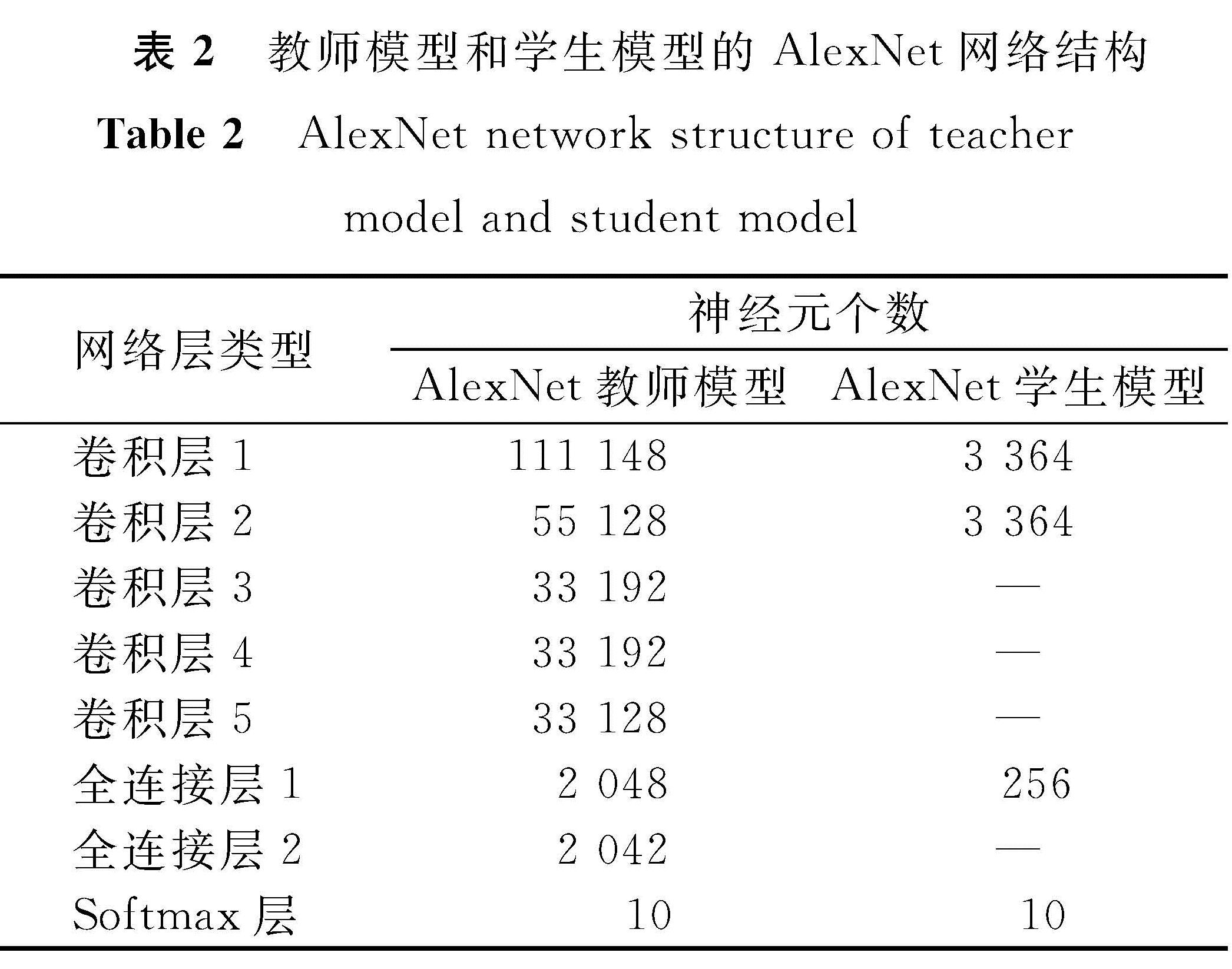
表2 教师模型和学生模型的AlexNet网络结构
Table 2 AlexNet network structure of teacher model and student model
3.2 试验对比
3.
2.1 直接蒸馏集成训练的有效性
首先蒸馏训练不同温度下的单个LeNet学生模型和AlexNet学生模型。图2为LeNet学生模型和AlexNet学生模型的不同温度下直接蒸馏集成训练效果。在不同温度下蒸馏出10个学生模型,记录10个分类准确率的最高值、最低值及平均值。温度为0时为正常训练的学生模型。
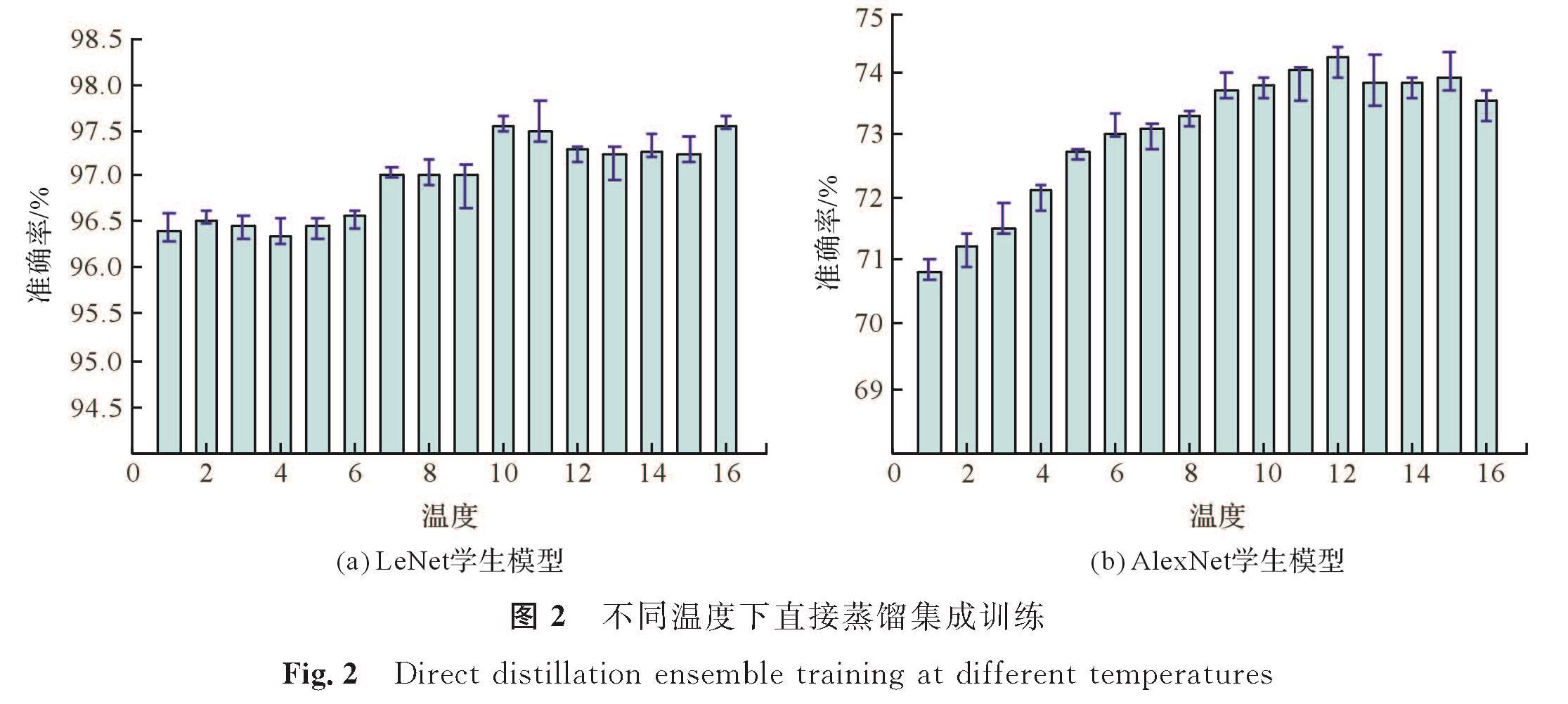
图2 不同温度下直接蒸馏集成训练
Fig.2 Direct distillation ensemble training at different temperatures
已知LeNet教师模型的分类准确率为98.79%,AlexNet教师模型的分类准确率为76.97%。由图2可知,在不同的温度下,LeNet学生模型与AlexNet学生模型的分类准确率都低于各自对应的教师模型,其原因是学生模型网络结构更简单,表达能力弱于教师模型,无法容纳教师模型迁移过来的全部知识。因此,需考虑集成多个学生模型以提升分类准确率。
在AlexNet模型上采用不同蒸馏设置进行集成,将集成分为四类:1)未蒸馏集成,对多个教师模型进行集成; 2)同源同温集成,对同一教师模型蒸馏的学生模型进行集成(T=22); 3)同源异温集成,对同一教师模型蒸馏的学生模型进行集成(T=1,20,…,100); 4)异源同温集成,对不同教师模型蒸馏的学生模型进行集成(T=22)。
在AlexNet上进行的不同蒸馏设置的直接蒸馏集成试验结果如图3所示。由图3可知,随着模型个数的增加,未蒸馏的模型集成的分类准确率持续上升,其原因是未蒸馏的模型集成由容量更大的教师模型集成得到。与此相比,随着模型个数的增加,直接蒸馏集成模型的分类准确率虽有提高,但始终低于未蒸馏的集成模型。
为了解直接蒸馏集成模型分类准确率不高的原因,需从学生模型差异性角度进行研究。将T=1、20、30蒸馏得到的3个AlexNet学生模型作为观测对象,以CIFAR-10中的一张图片为例,记录其在不同学生模型中的输出。图4为CIFAR10数据集上不同学生模型的概率输出。试验结果表明,随着温度的升高,蒸馏得到的学生模型的概率分布变平滑,学生模型间的差异性被减弱。可见,模型之间的差异性影响了模型集成的效果,直接蒸馏集成训练无法提高分类准确率。对此,我们提出差异性蒸馏集成训练来增强学生模型间的差异性,以增强集成性能。

图3 AlexNet不同蒸馏设置的直接蒸馏集成训练试验结果
Fig.3 Results of direct distillation ensemble training with AlexNet different distillation settings
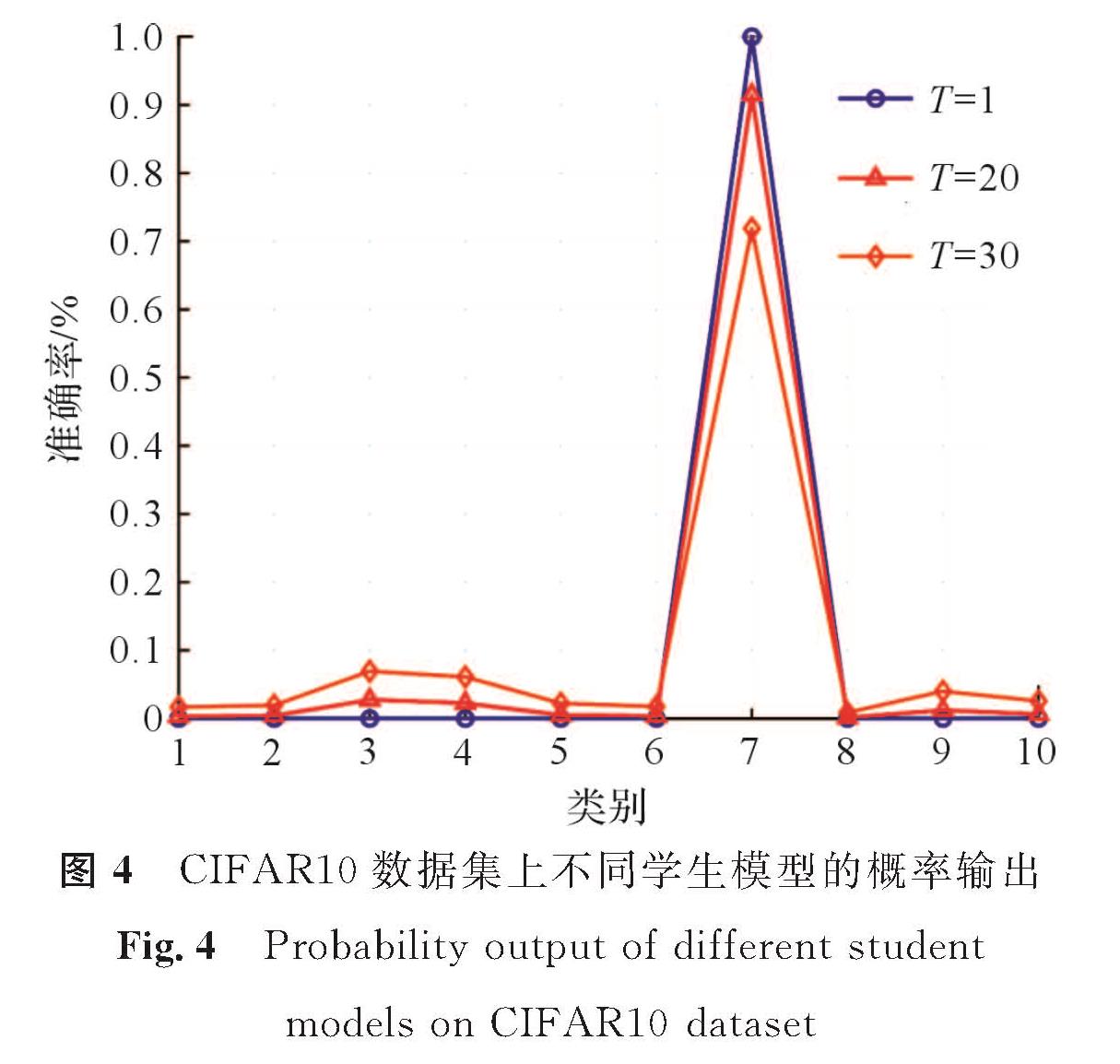
图4 CIFAR10数据集上不同学生模型的概率输出
Fig.4 Probability output of different student models on CIFAR10 dataset
3.
2.2 差异性蒸馏集成训练的有效性
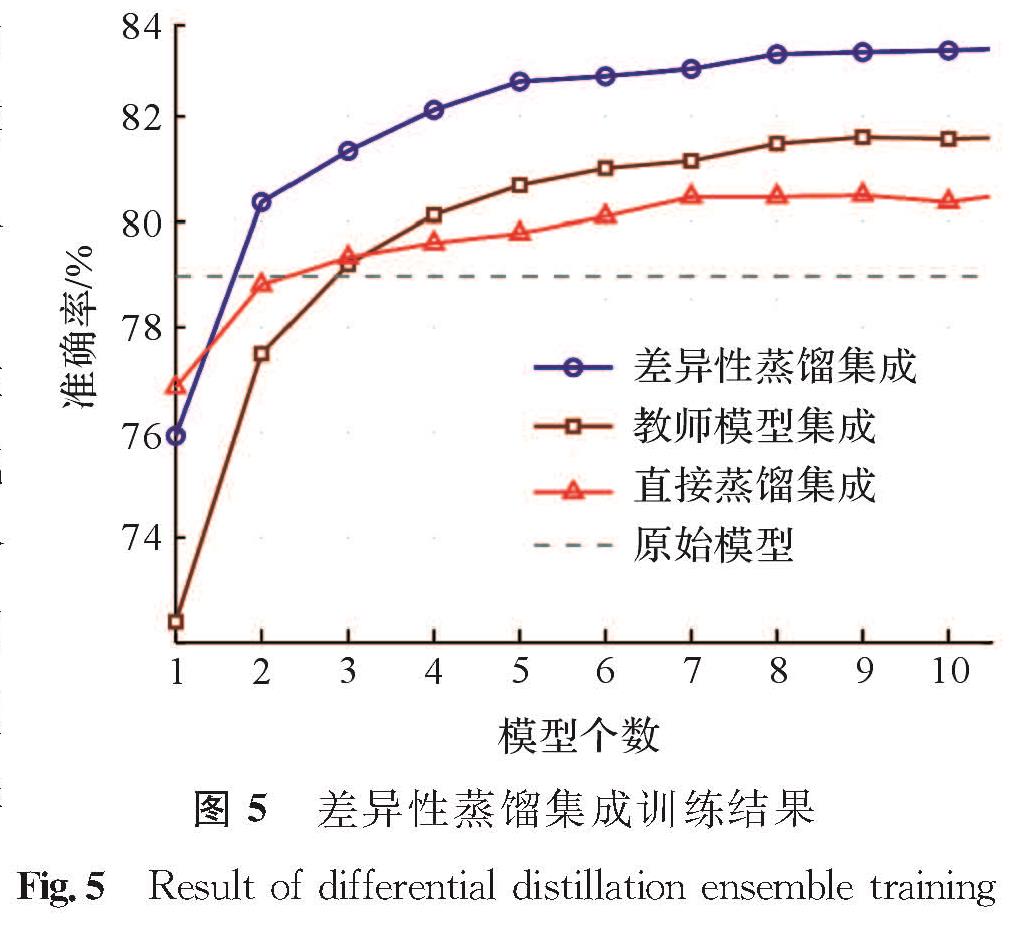
图5 差异性蒸馏集成训练结果
Fig.5 Result of differential distillation ensemble training
通过试验验证差异性蒸馏集成训练的有效性,图5为3种情况的差异性蒸馏集成训练结果。由图5可知,差异性蒸馏集成训练可以有效增强模型的泛化性能。随着模型个数的增加,直接蒸馏集成的分类准确率趋于平稳且低于教师模型集成,而差异性蒸馏集成的分类准确率则不断上升且显著高于教师模型集成和直接蒸馏集成。这说明差异性蒸馏集成不但能缩小模型规模,而且能提升模型的泛化性能。考虑到成员模型的分类准确率和成员模型间的差异性决定集成性能[12],我们对成员模型的集成准确率A和集成差异性D进行量化。集成准确率定义为被所有成员模型分类正确的样本占样本总量的比例。模型间集成差异性采用Lu等[22]提出的双误差(double fault,DF)作为衡量成员模型间差异性的指标,定义为所有成员模型分类错误的样本占样本总量的比例。A和D的定义分别如下:

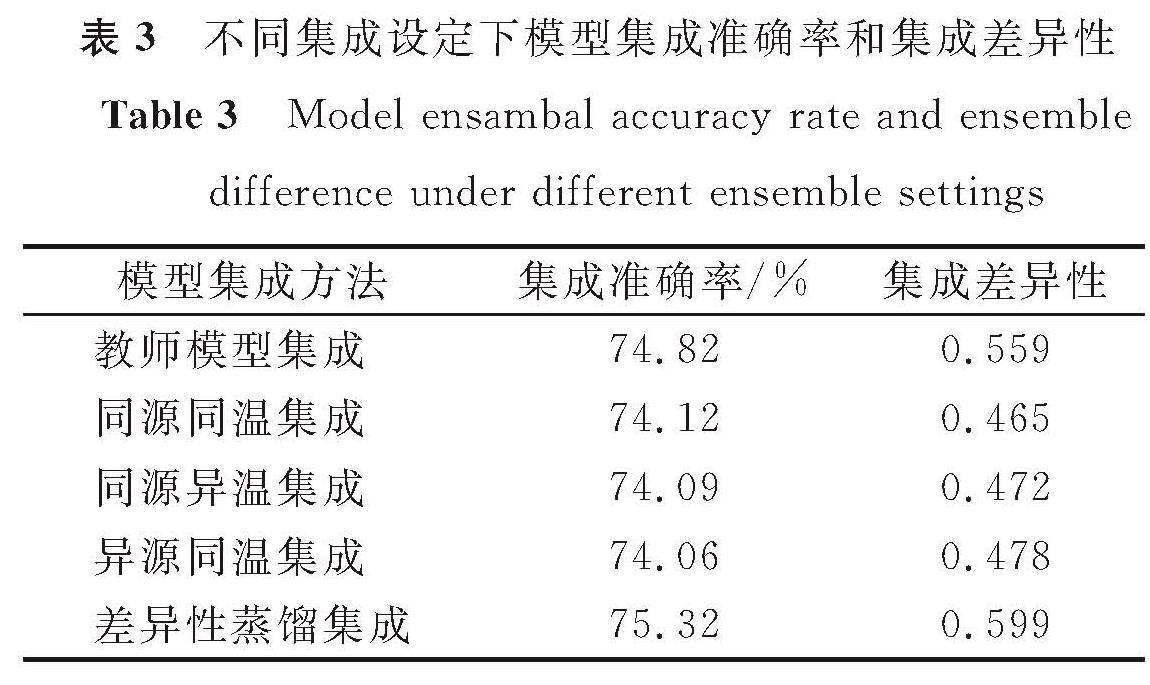
表3 不同集成设定下模型集成准确率和集成差异性
Table 3 Model ensambal accuracy rate and ensemble difference under different ensemble settings
式(10)和式(11)中:a为所有成员模型分类正确的样本数量; b为所有成员模型分类错误的样本数量; N为样本总量。不同集成设定下模型集成准确率和集成差异性见表3。其中,同源同温集成、同源异温集成、异源同温集成都属于直接蒸馏集成。以教师模型的分类准确率为基线可以发现,差异性蒸馏集成的分类准确率及集成差异性都高于教师模型集成和直接蒸馏集成。因此,我们可以得出结论,差异性蒸馏集成可以在缩小模型规模的同时提升集成准确率。
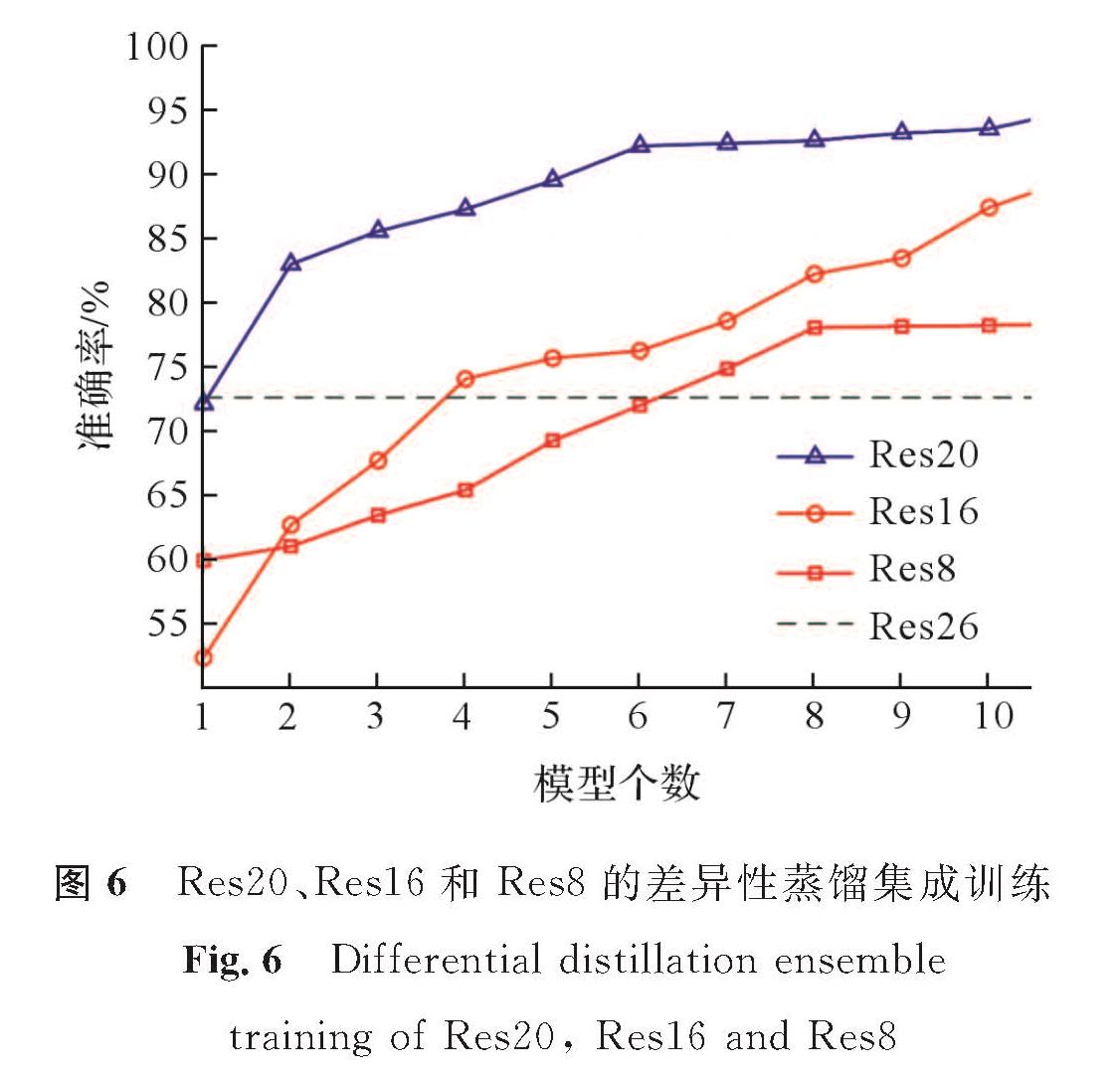
图6 Res20、Res16和Res8的差异性蒸馏集成训练
Fig.6 Differential distillation ensemble training of Res20, Res16 and Res8
上述试验都建立在相同规模的模型上。进一步地,我们在不同规模的模型上验证差异性蒸馏集成训练的有效性:采用的模型为不同层数的ResNet,设置通道大小为16、32、64; 教师模型使用Res26,学生模型使用Res20、Res16、Res8; 最小批次都设置为256。教师模型在CIFAR-10数据集上训练80个批次,学习率设置为0.01,动量为0.9,权重衰减为0.000 1。在此基础上对批次进行调整,教师模型在CIFAR-10数据集上训练60个批次,学习率设置为0.01,动量为0.9,权重衰减为0.000 1。图6为Res20、Res16和Res8的差异性蒸馏集成训练结果。试验发现,随着学生模型个数的增多,3种学生模型的差异性蒸馏集成准确率逐渐升高,规模越大的模型分辨准确率越高,并且都高于原始教师模型。由此可以得出结论,差异性蒸馏集成训练模型不受模型规模的约束,能在小规模学生网络的情况下得到优于教师网络的集成模型。
4 结 语本文提出的基于知识蒸馏的差异性深度集成学习,通过在集成过程中利用余弦距离增大成员模型的预测差异性,在缩小模型规模的同时提升了成员模型集成后的分类准确率。在集成训练过程中,我们使用新的损失函数在同一个数据集上同时交互式地训练所有的成员模型。在MNIST和CIFAR10数据集上的试验结果表明,本文提出的基于知识蒸馏的差异性深度集成学习优于将教师模型直接集成或将学生模型直接蒸馏集成。可见,基于知识蒸馏的差异性深度集成学习更适用于计算资源有限的边缘计算环境,有助于边缘智能系统的应用推广。未来的工作中,我们将进一步探索模型压缩对泛化性能的影响,以提升集成模型的泛化能力。
- [1] LI Y C, ZHOU R G, XU R Q, et al. A quantum deep convolutional neural network for image recognition[J].Quantum Science and Technology,2020,5(4):4375.
- [2] 孙佳佳,吕飞,雷晨曦,等.基于图像识别的有害生物检疫鉴定探索研究[J].植物检疫,2020,34(5):42.
- [3] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL].(2014-09-04)[2020-08-20].https://arxiv.org/abs/1409.1556.
- [4] HÜLSMEIER D, WARZYBOK A, KOLLMEIER B, et al. Simulations with FADE of the effect of impaired hearing on speech recognition performance cast doubt on the role of spectral resolution[J].Hearing Research,2020,39(15):107995.
- [5] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks[C]//Advances in Neural Information Processing Systems. Montreal: NIPS,2014:3104.
- [6] WANG Z W, SHE Q, SMEATON A F, et al. Synthetic-neuroscore: using a neuro-AI interface for evaluating generative adversarial networks[J].Neurocomputing,2020,405(10):26.
- [7] 翟翔宇,杨风暴,吉琳娜,等.标准化全连接残差网络空战目标威胁评估[J].火力与指挥控制,2020,45(6):39.
- [8] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[EB/OL].(2015-02-11)[2020-08-20].https://arxiv.org/abs/1502.03(6).
- [9] 强宇佶,申双琴.智能家居嵌入式人脸识别门禁系统的设计与实现[J].科学技术创新,2020(26):112.
- [10] 张施皛,唐天宇,张志明,等.基于CNN-PID的竞赛机器人赛道识别与自主驾驶[J].试验技术与管理,2020,37(9):39.
- [11] HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[J].Computer Science,2015,14(7):38.
- [12] HANSEN L K, SALAMON P. Neural network ensembles[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1990,12(10):993.
- [13] ISLAM M M, YAO X, MURASE K. A constructive algorithm for training cooperative neural network ensembles[J].IEEE Transactions on Neural Networks,2003,14(4):820.
- [14] TRAME`R F, KURAKIN A, PAPERNOT N, et al. Ensemble adversarial training: attacks and defenses[EB/OL].(2020-05-19)[2020-08-20].https://arxiv.org/abs/1705.07204.
- [15] FURLANELLO T, LIPTON Z C, TSCHANNEN M, et al. Born again neural networks[C]//Proceedings of Machine Learning Research. Stockholm: PMLR,2018:1607.
- [16] DONG Y P, LIAO F Z, PANG T Y, et al. Boosting adversarial attacks with momentum[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR,2018:9185.
- [17] PANG T Y, XU K, DU C, et al, Improving adversarial robustness via promoting ensemble diversity[EB/OL].(2020-05-29)[2020-08-20].https://arxiv.org/pdf/1901.08846.
- [18] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278.
- [19] KRIZHEVSKY A. Learning multiple layers of features from tiny images[J].Handbook of Systemic Autoimmune Diseases,2009,1(4):13.
- [20] MUKKAMALA M C, HEIN M. Variants of RMSProp and adagrad with logarithmic regret bounds[C]//Proceedings of Machine Learning Research. Sydney: PMLR,2017:2545.
- [21] ZHU X H, NI Z W, NI L P, et al. Spread binary artificial fish swarm algorithm combined with double-fault measure for ensemble pruning[J].Journal of Intelligent and Fuzzy Systems,2019,36(5):4375.
- [22] LU H J, AN C L, ZHENG E H, LU Y. An adaptive and momental bound method for stochastic learning[J].Neurocomputing,2014,128:22.