 图 1 宽度学习更新结构示意图
Fig.1 Broad learning update structure diagram
图 1 宽度学习更新结构示意图
Fig.1 Broad learning update structure diagram
WU Yufeng,FENG Jun,QIAN Yaguan,et al.Weighted ensemble achievement prediction model based on broad learning algorithm[J].Journal of Zhejiang University of Science and Technology,2021,33(05):362-368.[doi: 10.3969/j.issn.1671-8798.2021.05.004]

教育数据挖掘(educational data mining,EDM)是一个新兴的跨学科的研究领域。它利用机器学习、统计学和数据挖掘技术对教育数据进行分析和处理,从而提高学习者的学习效率,更好地让教师了解学生及其学习环境。对学生成绩预测是教育数据挖掘领域的热门研究课题。常用的数据挖掘分类算法有决策树(decision tree,DT)[1]、神经网络(neural network,NN)[2]、朴素贝叶斯[3](naive Bayes,NB)、逻辑回归[4](logistic regression,LR)、支持向量机[5](support vector machine,SVM)等算法。Ma等[6]使用支持向量机算法和网格搜索优化的决策树算法来预测学生成绩,并利用信息增益找出对学生成绩影响较大的因素,于是可利用该模型来识别与学生成绩有关的重要特征和学生考试通过率。Rubiano等[7]利用数据挖掘工具Weka中的3种分类器J48、PART、RIPOR对932名系统工程专业学生的成绩进行预测,发现J48分类器的预测准确率较高。Costa等[8]使用决策树、支持向量机、神经网络和朴素贝叶斯等算法对学生成绩是否合格进行预测,结果表明支持向量机算法的预测结果优于其他算法结果。Yang等[9]通过建立包含成绩相关属性和非相关属性的学生属性矩阵,对学生属性进行量化,应用反向传播神经网络算法来预估学生成绩,并找出了影响学生成绩的关键因素。施佺等[10]使用聚类分析和关联方法对学生在线学习过程中的数据进行分析,使用聚类分析对学生进行分类,教师可以根据分类结果对学生采取不同形式的监管,使用关联规则了解学生学习属性和学习成绩之间的关联。在文献[11-14]中,研究者们使用从Kalboard 360 E-Learning系统收集的学业成绩数据集,利用决策树、神经网络、朴素贝叶斯等算法验证了:学生学习过程中家长参与度、学生参加课程频次和学生行为特征(举手发言、查看公告、访问课程资源和讨论)对学生成绩有很大的影响。他们使用预测学习成绩的模型评价指标值在70%~80%之间,其中,文献[14]使用集成学习构建学生成绩预测模型,然后对集成的模型进一步嵌套集成,提升了分类预测模型的性能,但也仅为79.2%。由此可见,这些模型的效果还有较大的提升空间。
通过文献分析,我们发现有很多研究者建立了学生成绩预测模型,但是大多数研究是从理论层面分析来建立学业成绩评估模型,所建立的模型预测准确率不够高,推测其可能的原因如下:一是使用的算法不同,不同的算法对学生数据的训练效果是不同的,即使使用同一份数据也可能由于研究者的偏好或模型参数的不同而导致模型的效果不同; 二是特征选择不同,选择不同的属性子集会对学生成绩预测产生不同的结果,应该尽量选择与学生成绩有关的特征,并且特征之间最好不要相互影响。针对上述研究存在的不足,本试验首先采用数据驱动的建模方法,在包含16名学生属性的数据集中以模型的预测准确率作为特征子集选择的标准,采用排列组合的方式找出影响学生成绩的因素,充分利用了学生数据的有效信息。然后,针对这些有效属性,采用宽度学习(broad learning,BL)算法进行成绩预测。该算法具有步骤少、结构简单和学习速度比较快等优点,弥补了深度学习算法由于需要计算大量隐层权值所造成的训练时间过长的缺陷,与深度神经网络算法相比容易获得全局最优解,具有良好的泛化性能[15-16]。最后,在训练好的算法上进行加权集成来构建学生成绩预测模型,以克服单个分类器性能不够稳定,对数据变化比较敏感的缺点。
1 数据来源及数据预处理1.1 数据来源和数据特征本研究使用从Kalboard 360 E-Learning系统收集的约旦大学学生成绩数据集[17]。它是通过电子管理系统收集的学习者活动数据,该数据集的属性及其类别特征见表1。
表1 学业成绩数据集的属性及其类别特征
Table 1 Attributes of academic achievement data set and its category characteristics

1.2 数据预处理
数据预处理是研究过程的重要步骤,通过预处理可以提高数据集的质量。数据预处理包含数据清理、数据集成、数据规约和数据变换。数据清理主要处理数据的各种异常情况,包括删除重复信息与纠正错误信息。数据集最初收集了500条数据,在删除重复数据和缺失数据并清理异常数据后,数据变成了480条。数据归约是通过精简数据尽可能多地保留原数据中的有效信息,即对数据进行特征选择,其理想方法是将数据集中所有可能的属性子集作为算法的输入,然后选择能使算法预测准确率最高的子集作为特征选择的结果[14]。本试验对数据属性所有可能的子集进行遍历,分别使用决策树、多层感知机神经网络和宽度学习算法等模型进行训练,每种模型经过训练得到3个效果最好的基分类器。其中,以宽度学习算法训练得到的3个基分类器属性子集标号分别为:①②③⑤⑧⑨⑩B11B13B15,①②⑤⑥⑩B11B13B14,①②③⑤⑥⑩B11B12B14B15B16。数据变换是通过改变数据的特征以方便计算和发现新的信息,主要是对数据进行标准化和离散化。标准化处理的是连续型变量,使处理后的数据在[0,1]区间,服从正态分布。对非数值型数据进行标准化是指对分类型特征进行编码,即对不连续的数值进行编码,如将教育水平属性值小学、初中、高中分别标准化为1、2、3。离散化主要是根据学生的分数,将学生成绩分为3个等级:低级(L),0~69; 中级(M),70~89; 高级(H),90~100。通过数据预处理得到了标准化的数据,然后利用处理好的数据进行训练。
2 预测算法与试验设计2.1 预测算法本研究主要根据学生成绩数据集对学生学期结束时的成绩进行预测,通过标记的类别数据对处理好的数据集进行训练,并将宽度学习算法和集成学习算法相结合,建立了学生成绩预测模型。
2.1.1 宽度学习算法宽度学习算法[18]最开始是作为深度学习算法的替代方法提出的,是一种基于随机向量函数的算法。宽度学习算法首先将输入数据映射成特征节点矩阵,经过增强变换形成增强节点矩阵,由特征映射节点和增强节点共同作为隐含层的输入,利用伪逆求解隐含层与输出层之间的权重矩阵。当特征映射节点和增强节点的数目无法满足任务需求时,宽度学习算法使用增量学习的方式动态调整网络结构,实现快速重新训练。假设算法的训练集输入为X,包含A个训练样本,每个样本有B个属性,训练集的标签类别为M种,则算法的具体过程如下:
首先,将输入数据X映射成特征节点矩阵。训练集X经过第i组特征映射得到第i组特征节点矩阵
Zi=φi(XABWei+βei)。 (1)
式(1)中:Wei为第i组特征映射权重矩阵; βei为第i组特征映射偏置矩阵。
然后,根据特征节点矩阵得到增强节点矩阵。前i组特征节点矩阵Zi经过第j组增强映射得到第j组增强节点矩阵
Hj=ξj(ZiWhj+βhj)。 (2)
式(2)中:Whj为第j组增强映射权重矩阵; βhj为第j组增强映射偏置矩阵; Zi=[Z1,Z2,…,Zi]表示前i组特征节点矩阵的连接; Wei、βei、Whj、βhj均为随机初始矩阵,且当Whj中的j取不同值时Whj相互正交。
于是,宽度学习算法可表示为:
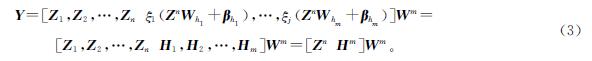
式(3)中:Wm为特征节点和增强节点到输出层的权重矩阵,即我们要求的权值矩阵,它是由[Zn|Hm]的伪逆推导出来的,即Wm=[Zn|Hm]+Y,其中[Zn|Hm]+可以使用伪逆岭回归近似算法求得:

式(4)中:λ是常规的L2范数正则化; I为单位矩阵。训练好Wm之后,测试集的测试值可由式(5)得到:
Y=[Zn|Hm]Wm。 (5)
由于初始设计的模型拟合能力不足,需要增加增强节点数量来减小损失函数。我们把增加一组增强节点之后的特征节点和增强节点到输出层的权重矩阵记为Wm+1,令Am=[Zn|Hm],新的权重可通过式(6)计算得到:
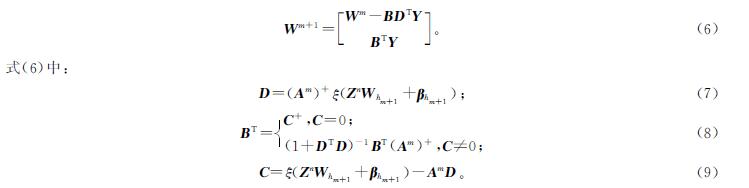
由式(6)可以看出,宽度学习算法在增加节点时,仅通过计算相应节点的伪逆就可以求出新的输出权重; 换言之,即只需计算新插入的增强节点的伪逆即可,如此可实现快速增量学习。宽度学习算法的更新结构如图1所示。
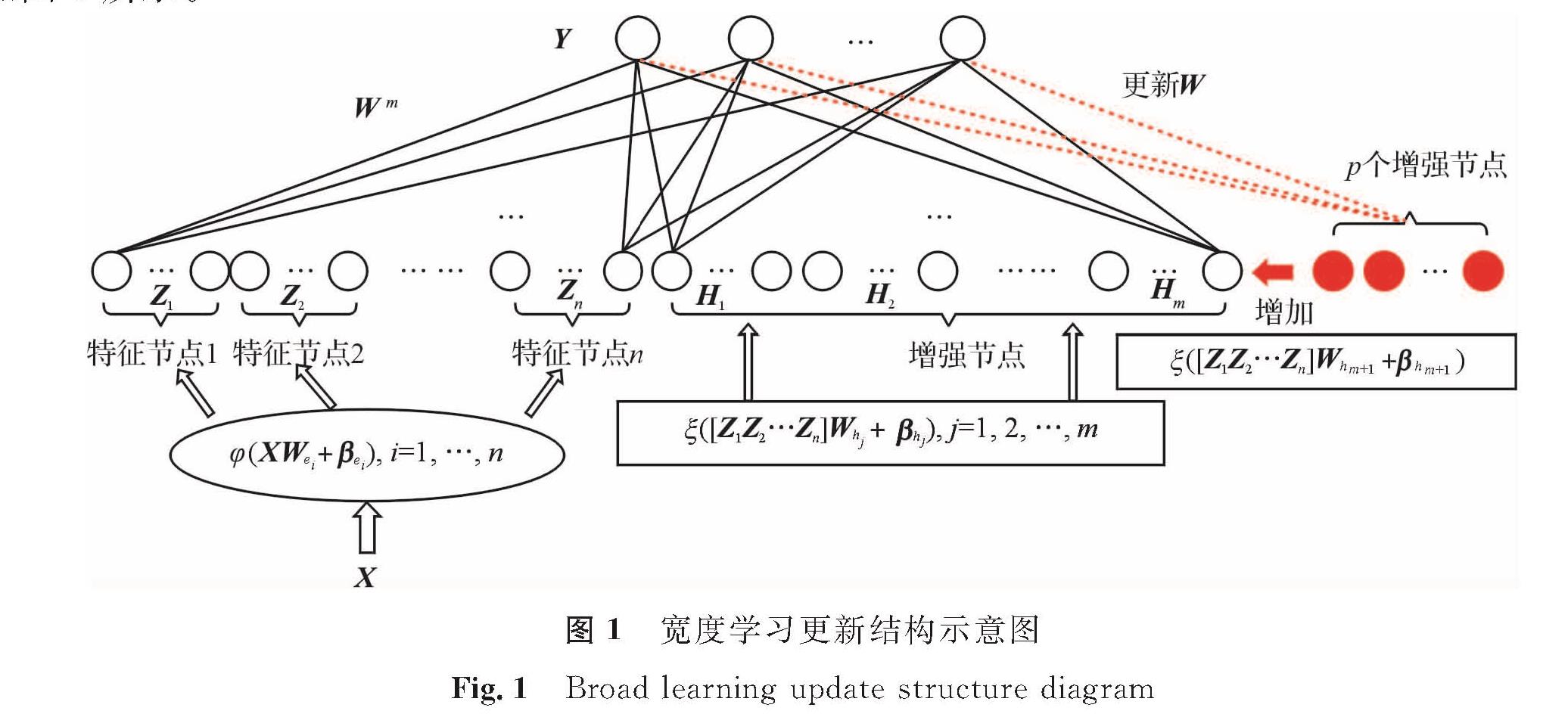
图1 宽度学习更新结构示意图
Fig.1 Broad learning update structure diagram
由宽度学习理论可知,宽度学习算法比神经网络结构更简单,可直接通过增加增强节点的方式提升模型性能,不需要重新训练网络。将其引入教育数据挖掘中,有助于在教育大数据提取中获得有意义的规律与模式[19]。
2.1.2 集成学习集成学习通过将多个分类器组合来完成学习任务。加权集成学习是一种集成学习方法,本研究中加权集成学习首先使用单个分类器决策树算法、多层感知机神经网络算法和宽度学习算法来建立模型,然后将每种分类器进行训练后得到3个模型,最后对3个模型的结果进行投票得出模型最终的判定类别。这种投票的方式能够获得比单一分类模型泛化性能更强的模型。
2.2 试验设计我们将数据分为两部分,其中,70%的数据作为训练集,30%的数据作为测试集。数据预处理过程结束之后,分别使用决策树、多层感知机神经网络、宽度学习算法训练模型,并且对模型进行调优,得到具有较高预测准确率的模型; 然后分别对选出的模型使用加权集成学习构建成绩预测模型。试验环境如下:处理器为Intel(R)Core(TM)i7-9700,处理器主频为3.00 GHz,内存为16.0 GB。试验的软件环境为Python3.7。在基于宽度学习算法的加权集成模型中,设每个窗口的特征节点数为20,特征节点窗口数为20,增强节点数为300,正则化系数C取值分别为32、32、256。
3 试验结果与对比分析3.1 单一分类模型之间及其与集成模型之间的性能比较

图2 模型预测准确率对比
Fig.2 Comparison of model prediction accuracy
试验使用决策树、多层感知机神经网络和宽度学习算法,经过特征选择和参数调整得到了3种分类器,采用加权集成方法对3种分类器分别进行训练和测试,得到模型的预测准确率如图2所示。为了评估学生成绩预测模型的性能,本研究使用了3个评价指标:准确率P、召回率R、F1值。
由图2可知,经过数据预处理和模型调优,决策树算法预测准确率为76.6%; 多层感知机神经网络算法的预测准确率较高,为85.8%; 宽度学习算法的预测准确率最高,达到了89.1%。加权集成学习之后,模型的预测准确率有所提升,其中,决策树模型的性能提升最明显,预测准确率提高了10个百分点; 多层感知机神经网络模型的预测准确率没有提高,其原因可能是训练的多层感知机神经网络模型具有相似性; 宽度学习模型的预测准确率提高了2.5个百分点,达到了91.6%。因此,我们可以看出加权集成学习可以有效提高模型的性能。之后,本试验使用加权集成学习对成绩类别为H、M、L的数据分别进行训练,得到的模型效果如图3所示。
使用加权集成学习之后对学生成绩各个类别进行测试,得到宽度学习算法集成之后的F1最高,分别为88.5%、90.3%、96.9%,表明基于宽度学习算法的加权集成成绩预测模型效果较好,而且该模型对学生成绩类别为低的学生精确率、召回率、F1值最高,均为96.9%。这符合模型的设计初衷,即找出哪些学生最可能不及格,从而对这类学生进行学习预警,并采取有针对性的措施来帮助学业成绩差的学生提高考试通过率。
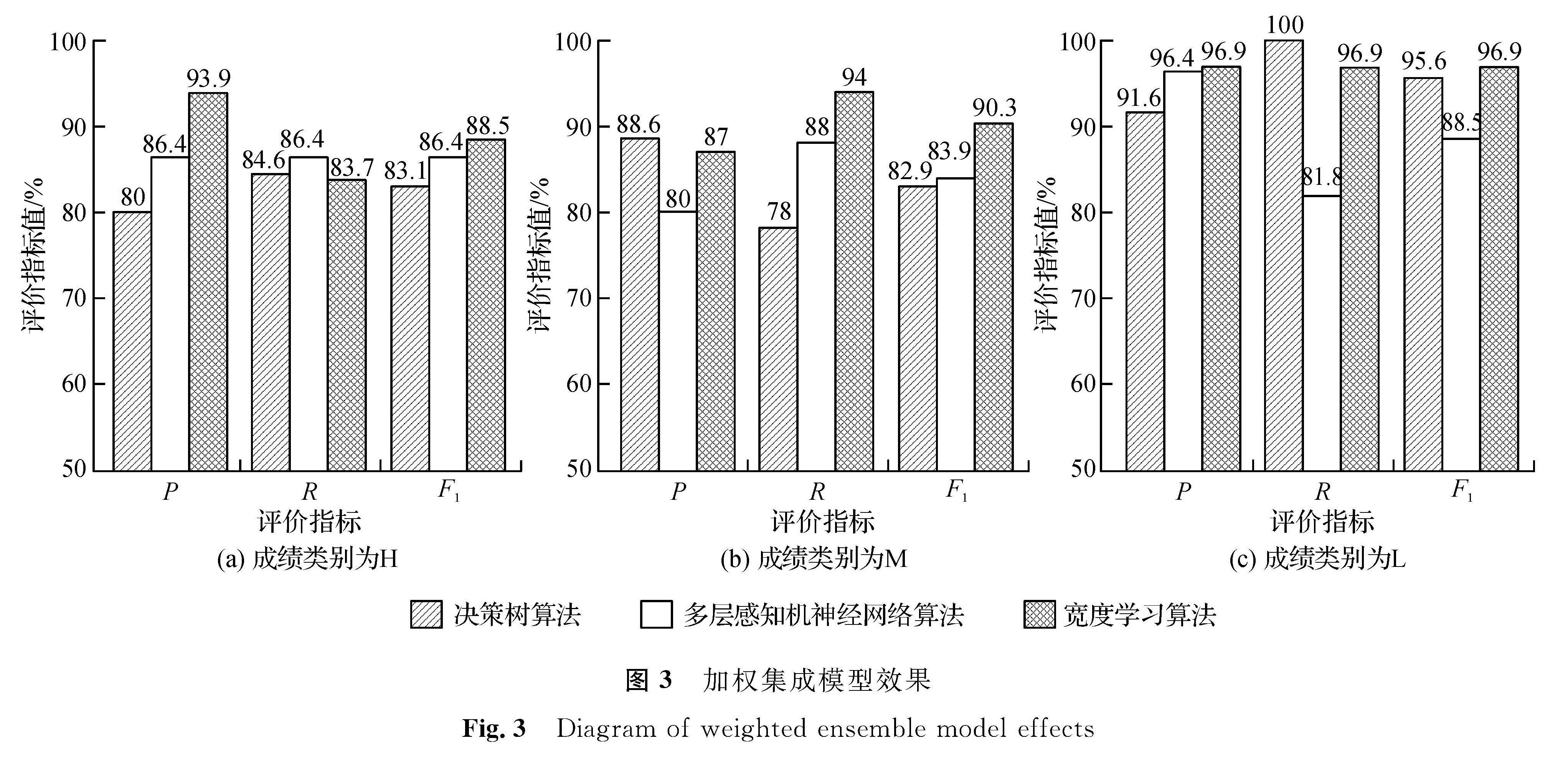
图3 加权集成模型效果
Fig.3 Diagram of weighted ensemble model effects
3.2 与前人研究性能对比
表2 模型效果对比
Table 2 Comparison of model effects%
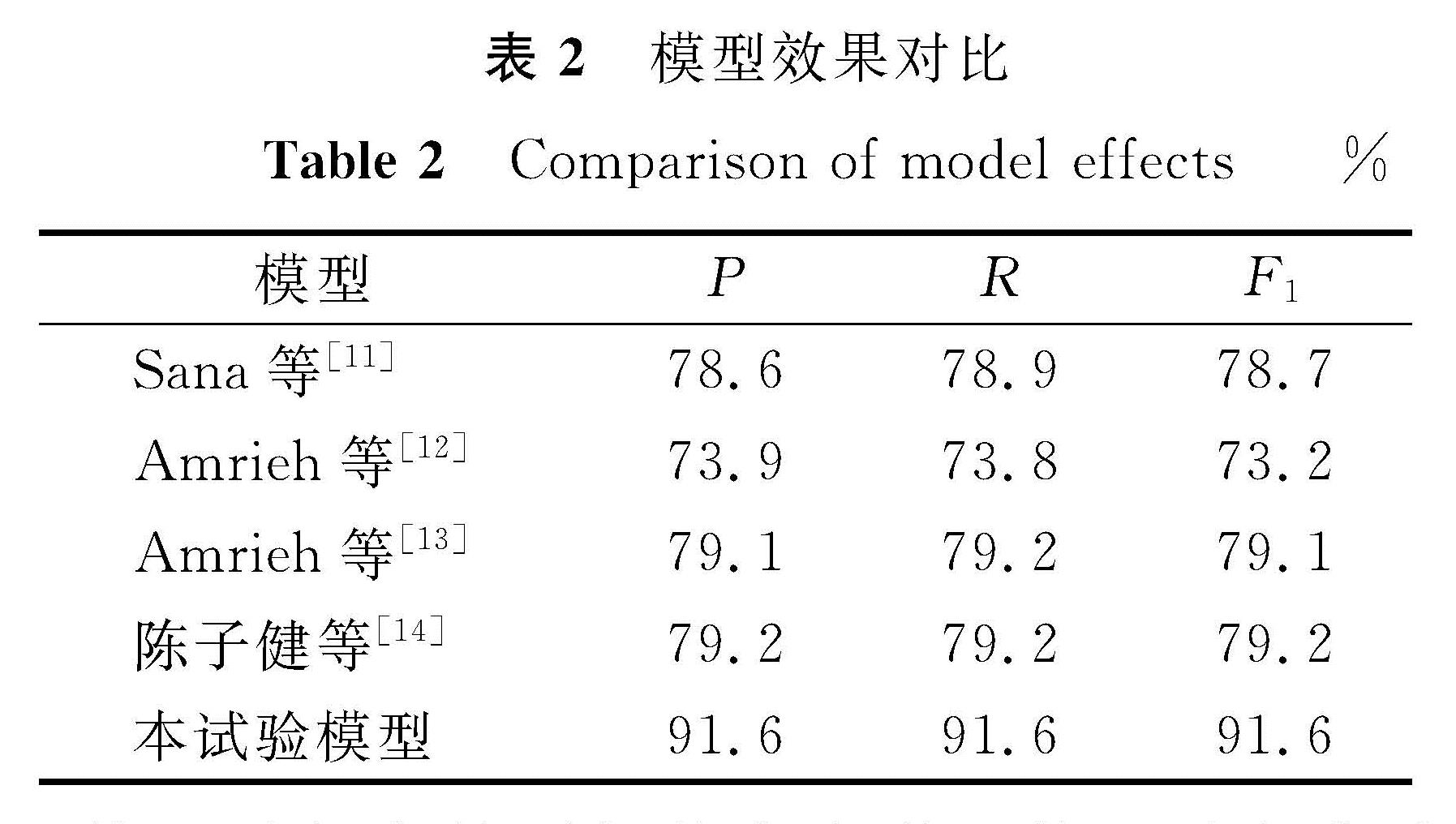
我们从准确率P、召回率R、F1值三方面与其他研究者的试验结果进行对比,结果见表2。
从表2可以很明显地看出,在使用同一份学生数据集的情况下,本研究建立的模型预测效果比之前其他研究者的模型高出十几个百分点。之前研究者采用传统的机器学习算法或集成学习的方法,模型的评价指标值大致在70%~80%之间。本试验由于采用数据驱动的方法,在挑出最优属性子集的前提下,使用具有网络结构且善于进行参数更新的宽度学习算法进行集成学习,预测准确率达到了91.6%,这验证了模型的有效性。
4 结 语本研究将宽度学习算法和集成学习算法相结合,建立了学生成绩预测模型。为了验证模型的有效性,我们采用两种对比方式,一方面使用同样的数据处理方式建立了基于决策树、神经网络、宽度学习算法的集成学习算法,试验结果表明后者效果最好; 另一方面,在使用相同数据集和相同模型的情况下,本文建立的模型预测效果也比之前研究者的模型效果好。这表明本研究提出的基于宽度学习算法的加权投票成绩预测模型,能够有效逼近学生特征属性与学生成绩之间的非线性关系。本研究可供教育工作者利用这一模型了解学生,以帮助学生改善学习过程,降低学习失败率,同时也可以帮助管理者提高管理效率。
- [1] KEORGIOS G, LIPITAKIS A D, KOTSIANTIS S, et al. Predicting student performance in distance higher education using active learning[C]//International Conference on Engineering Applications of Neural Networks. Cham: Springer,2017:75.
- [2] KAUR P, SINGH M, JOSAN G S. Classification and prediction based data mining algorithms to predict slow learners in education sector[J].Procedia Computer Science,2015,57:500.
- [3] HAN J, KAMBER M. Data mining: concepts and techniques[M].Netherlands: Elsevier,2011.
- [4] NG A Y, JORDAN M I. On discriminative vs. generative classifiers: a comparison of logistic regression and naive bayes[C]//Advances in Neural Information Processing Systems. San Mateo, CA: Morgan Kaufmann Publishers Inc,2002:841.
- [5] SUYKENS J, VANDEWALLE J. Least squares support vector machine classifiers[M].Netherlands: Kluwer Academic Publishers,1999.
- [6] MA X F, ZHOU Z R. Student pass rates prediction using optimized support vector machine and decision tree[C]//2018 IEEE 8th Annual Computing and Communication Workshop and Conference(CCWC). Nevada: IEEE,2018:209.
- [7] RUBIANO S, GARCIA J. Analysis of data mining techniques for constructing a predictive model for academic performance[J].IEEE Latin America Transactions,2016,14(6):2783.
- [8] COSTA E, FONSECA B, SANTANA M, et al. Evaluating the effectiveness of educational data mining techniques for early prediction of students' academic failure in introductory programming courses[J].Computers in Human Behavior,2017,73:247.
- [9] YANG F, LI F W B. Study on student performance estimation, student progress analysis, and student potential prediction based on data mining[J].Computers and Education,2018,123:97.
- [10] 施佺,钱源,孙玲.基于教育数据挖掘的网络学习过程监管研究[J].现代教育技术,2016,26(6):87.
- [11] SANA B, SIDDIQUI I F, ARAIN Q A. Analyzing students' academic performance through educational data mining[J].Open Journal Systems,2019:402.
- [12] AMRIEH E A, HAMTINI T, ALJARAH I. Preprocessing and analyzing educational data set using X-API for improving student's performance[C]//2015 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies(AEECT). Amman: IEEE,2015:1.
- [13] AMRIEH E A, HAMTINI T, ALJARAH I. Mining educational data to predict student's academic performance using ensemble methods[J].International Journal of Database Theory and Application,2016,9(8):119.
- [14] 陈子健,朱晓亮.基于教育数据挖掘的在线学习者学业成绩预测建模研究[J].中国电化教育,2017(12):75.
- [15] 郑云飞,陈霸东.基于最小p -范数的宽度学习系统[J].模式识别与人工智能,2019,32(1):51.
- [16] CHEN C L P, LIU Z L. Broad learning system: an effective and efficient incremental learning system without the need for deep architecture[J].IEEE Transactions on Neural Networks and Learning Systems,2017,29(1):10.
- [17] IBRAHIM A. Kalboard360-E-learning system[EB/OL].(2016-02-28)[2021-09-27].https://www.kaggle.com/aljarah.
- [18] CHEN C L P, LIU Z L. Broad learning system: structural extensions on single-layer and multi-layer neural networks[C]//2017 International Conference on Security, Pattern Analysis, and Cybernetics(SPAC). New York: IEEE,2018.
- [19] 袁利平,陈川南.宽度学习的教育价值及其意义[J].中国电化教育,2019(5):34.
- [18] 颜康康,淮明生.灰色GM(1,1)模型在我国医疗费用预测研究中的应用[J].医学与社会,2018,31(8):37.
- [19] 刘思峰,党耀国,方志耕,等.灰色系统理论及其应用[M].3版.北京:科学出版社,2004.
- [20] 高洪洋,胡小平,王彦方.中国农村居民医疗保健支出的影响因素[J].财经科学,2016(2):82.
- [21] 郑焱.我国城镇居民医疗保健支出的影响因素分析[J].现代经济信息,2019(9):10.
- [22] 唐齐鸣,项乐.中国居民医疗保健支出的影响因素及区域差异性研究[J].金融研究,2014(1):85.
- [23] 饶晓辉,栾佳蓉.老龄化形势下我国农民医疗保健支出的影响因素研究[J].江西社会科学,2015,35(2):197.
- [24] 阜阳市统计局.统计年鉴[EB/OL].[2020-09-17].http://tjj.fy.gov.cn/content/channel/5c37f7bdc9a5286c0a89697c/.