 图 1 BERT模型与ERNIE模型不同的掩码策略
Fig.1 Different mask strategies for BERT model and ERNIE model
图 1 BERT模型与ERNIE模型不同的掩码策略
Fig.1 Different mask strategies for BERT model and ERNIE model
BI Yunshan,QIAN Yaguan,ZHANG Chaohua,et al.Research on Chinese text classification based on ERNIE model[J].Journal of Zhejiang University of Science and Technology,2021,33(06):461-468.[doi: 10.3969/j.issn.1671-8798.2021.06.005]

近年来,随着移动互联网的迅猛发展,文本数据呈爆炸式增长,而文本分类作为自然语言处理(natural language processing,NLP)中的关键技术之一,受到了越来越广泛的关注。文本分类是一种将文本进行转换并自动分类到指定的某个或某几个类别之中的技术,NLP领域中的多种应用均可划分为文本分类,如意图识别、领域识别、情感分析等。文本分类的方法包括基于规则的方法[1]、基于统计机器学习的方法[2-3]及基于深度学习的方法[4-5],其中,由于深度学习强大的表示学习的能力,被广泛应用于文本分类任务中。而随着深度学习预训练语言模型的发展,文本分类任务的性能取得了更进一步的提升。
早期的预训练语言模型有文本向量化(word to vector,word2vec)[6]、全局词向量(global vectors for word representation,GloVe)[7]等,但这些模型不能解决一词多义问题; 之后,从语言模型中获取词向量(embedding from language model,ELMo)[8]等联系上下文的词向量预训练方法被提出,解决了一词多义问题,但ELMo采用的是长短时记忆网络(long-short-term memory network,LSTM)对特征进行提取,而LSTM提取特征的能力相对较弱,不能很好地融合上下文的特征。近几年,生成性预训练(generative pre-training,GPT)模型[9]、双向编码器表征量(bidirectional encoder representation from transformers,BERT)模型[10]等被相继提出。GPT是第一个引入了转换器[11]的预训练语言模型,转换器特征提取能力强于LSTM,且转换器并行计算能力强,但GPT本质上还是一个单向语言模型,无法获得上下文相关的特征表示,无法捕捉更多的信息。BERT模型是一种基于双向转换器构建的语言模型,由谷歌公司提出后被广泛应用到自然语言处理任务中[12-13]。谌志群等[14]将BERT模型与双向(bi-directional)LSTM相结合,构建了BERT-BiLSTM模型,用其对微博评论的倾向性进行分析,与传统方法相比提高了分类的准确性。马强等[15]提出基于BERT与卷积神经网络(convolutional neural network,CNN)的文本分类方法,引入CNN对BERT模型提取到的句子特征进一步提取,获得了更好的分类效果。由于LSTM并行处理的能力弱,CNN虽拥有较强的并行处理能力,但无法获取长距离的文本依赖关系; 而深度卷积神经网络(deep pyramid convolutional neural networks,DPCNN)通过不断加深网络,可以提取出深层次的文本特征。如李颖[16]提出基于BERT模型与DPCNN的垃圾弹幕识别方法,与LSTM、CNN方法相比提高了分类的准确性。但是,BERT预训练模型只关注了自身的文本信息,不能全面地获取潜在的文本特征。
针对上述问题,本研究利用知识增强语义表示(enhanced representation through knowledge integration,ERNIE)模型,它在BERT模型基础上进一步优化,加入了大量语料中的词法、句法等先验语义信息,能更全面地捕捉训练语料中的潜在信息,并引入深度卷积神经网络获取长距离的文本依赖关系,对文本特征进行深层次的提取,构建ERNIE-DPCNN模型进行中文文本分类,通过提升文本语义表征的能力来增强中文文本分类的效果。
1 ERNIE模型与DPCNN网络1.1 ERNIE模型ERNIE模型[17]可以同时充分利用词法、句法和语义信息,相比BERT模型,ERNIE模型的改进主要是在掩码机制上。BERT模型与ERNIE模型不同的掩码策略如图1所示,BERT模型建模对象主要聚焦在原始语言信号上,没有充分利用训练数据当中的词法结构、句法结构及语义信息去学习建模,在训练中文文本时,BERT模型随机掩盖掉15%的词进行预测,通过这种强行掩盖的方式,把“杭”和“州”字与字之间的关系给拆散了,模糊了“杭州”和“西湖”词与词之间的联系; 而ERNIE模型采用的掩码语言模型是一种带有先验知识的掩码机制,通过对词、短语等语义信息进行建模,得出“杭州”与“西湖”的关系,学到“杭州”是“西湖”的“所在地”及“杭州”被称为“人间天堂”,从而推断出此时掩盖掉的词是“杭州”,使得模型学习到完整概念的语义表示。
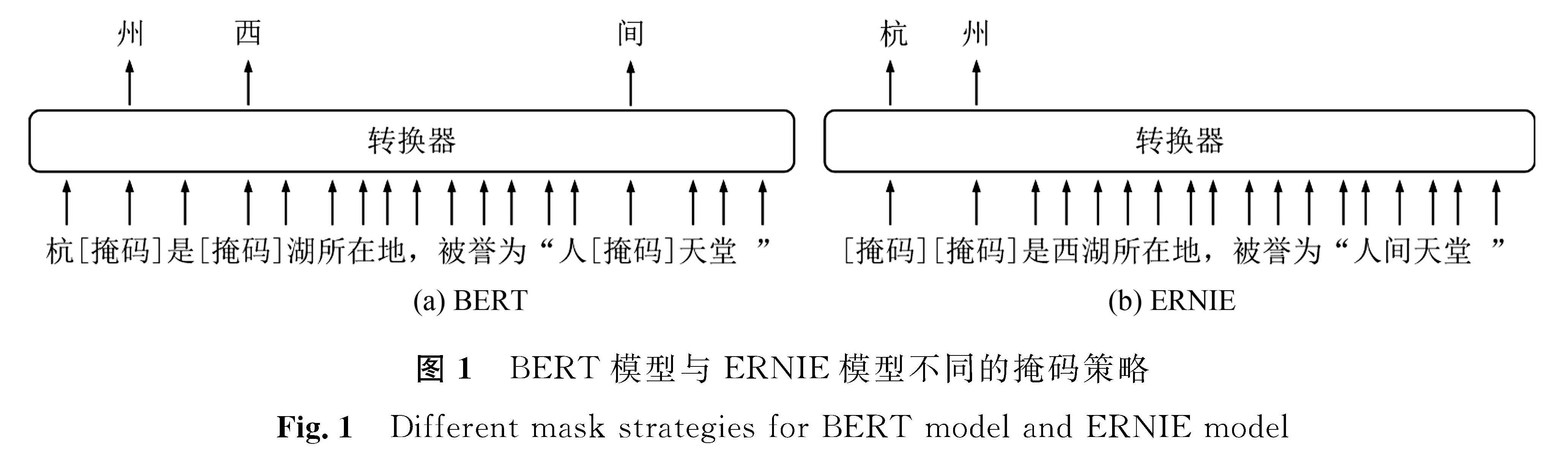
图1 BERT模型与ERNIE模型不同的掩码策略
Fig.1 Different mask strategies for BERT model and ERNIE model
1.2 DPCNN网络
深度卷积神经网络[18]是由腾讯人工智能实验室提出的,其通过不断加深网络,可以获得长距离的文本依赖关系。在DPCNN网络中卷积使用等长卷积,即输出序列的长度等于输入序列的长度; 在进行池化操作之前要固定特征图的数量,如果增加特征图的数量会大幅地增加计算时间,而精度并没有提高。在固定了特征图的数量后,每当使用一个卷积核大小为3、步长为2的池化层进行最大池化,每个卷积层的序列长度就被缩短为原始长度的一半,感知到的文本片段比之前长了一倍,计算时间减半,从而形成一个金字塔结构,进一步提取了有效特征。
2 ERNIE-DPCNN模型我们提出的ERNIE-DPCNN模型主要分为输入层、ERNIE层、DPCNN层和文本分类输出层,模型结构如图2所示。
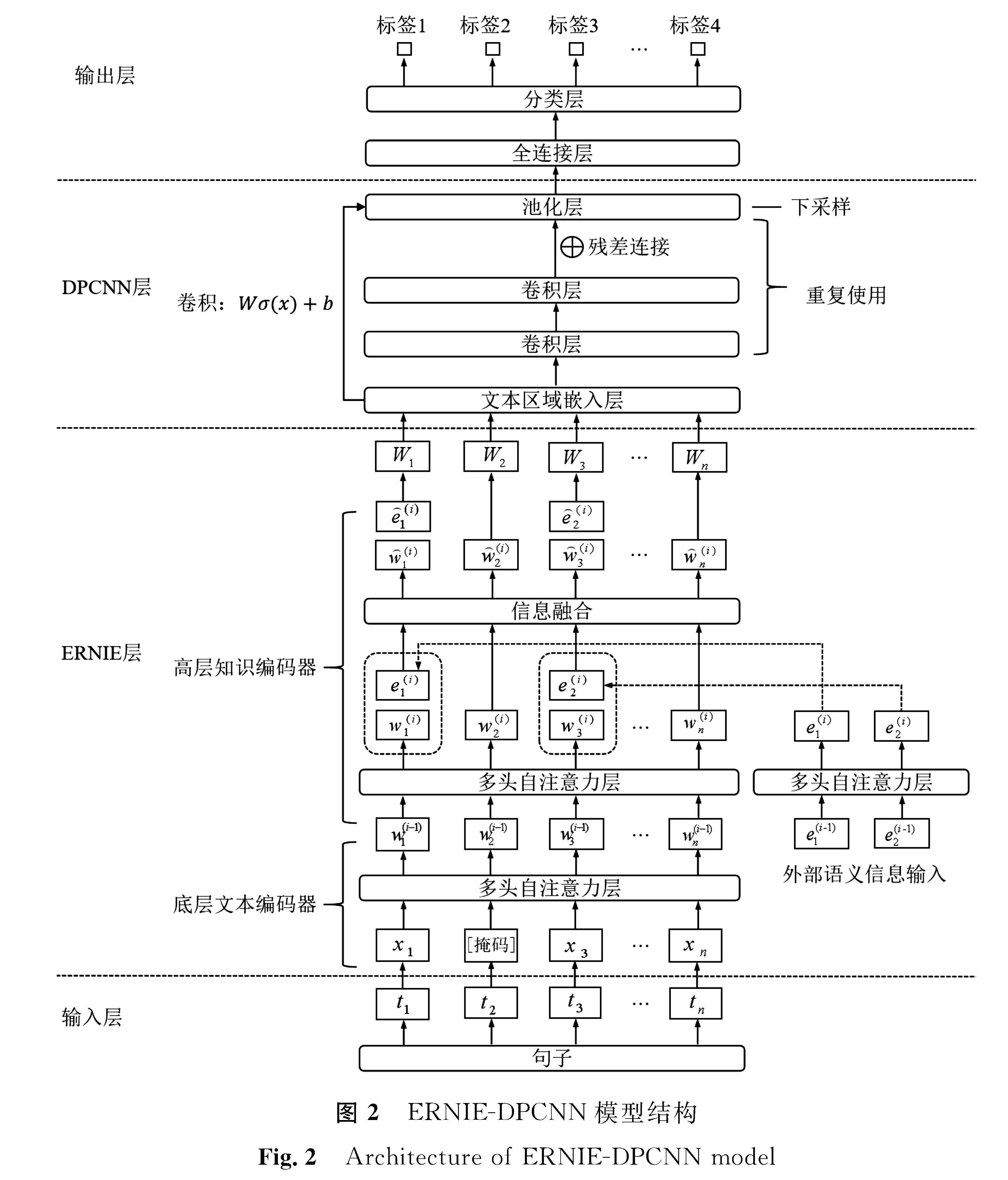
图2 ERNIE-DPCNN模型结构
Fig.2 Architecture of ERNIE-DPCNN model
2.1 输入层
将原始的句子转化为大小为(batch_size,padding_size)的词嵌入表示{t1,t2,t3,…,tn},其中,batch_size为每批次训练样本大小,padding_size为句子最大序列长度。
2.2 ERNIE层
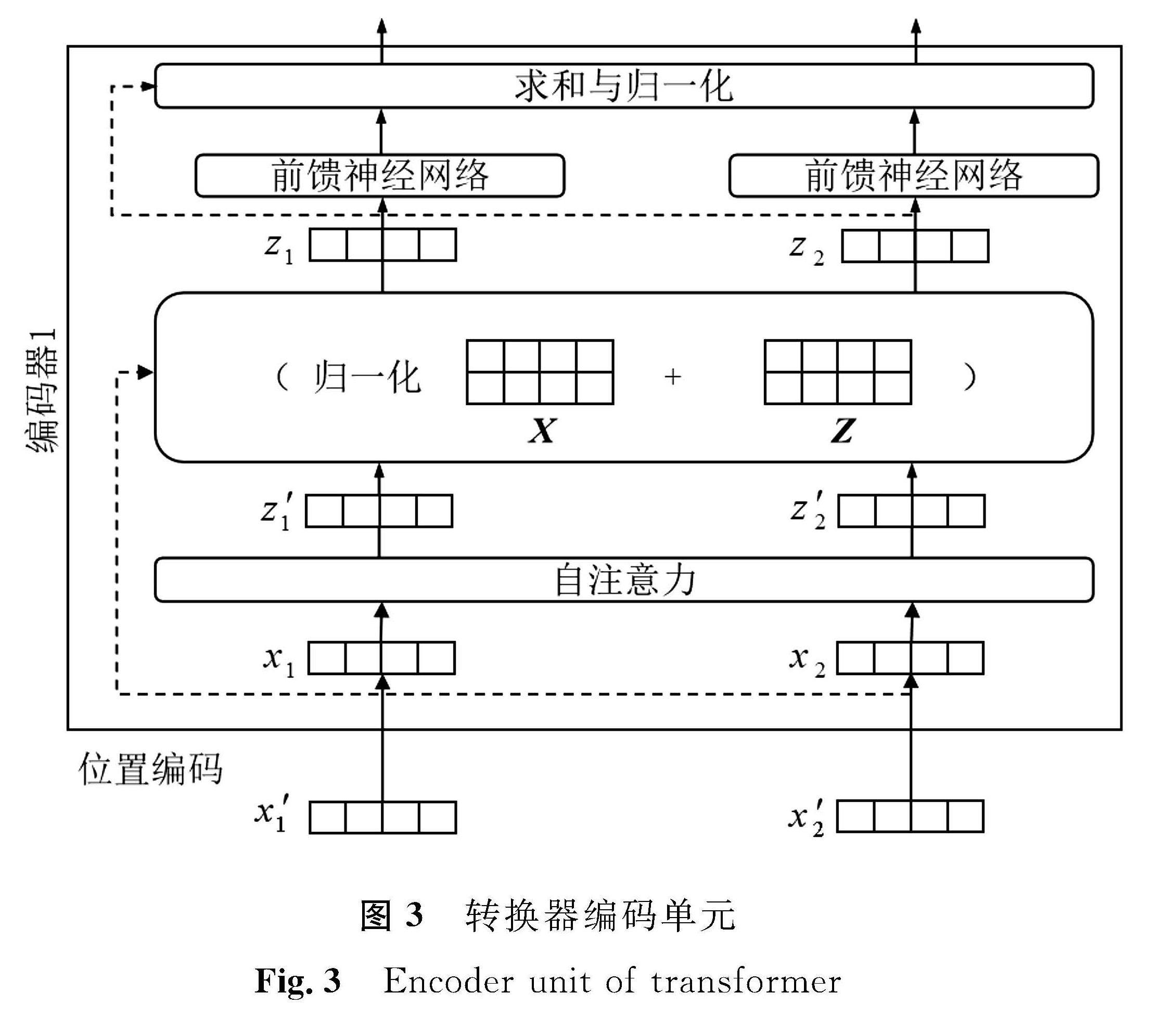
图3 转换器编码单元
Fig.3 Encoder unit of transformer
ERNIE层利用多层转换器的自注意力双向建模性能,主要采用了转换器的编码器部分。转换器通过矩阵间的计算来获得人们所关注的信息,抑制其他无用的信息,获得每个词新的表征,从而实现自注意力机制。转换器编码单元如图3所示,首先将输入向量矩阵T通过位置编码后得到矩阵X,与各自权重矩阵Wq、Wk、Wv相乘,用于获得词语之间的相互关联程度,得到查询矩阵Q、键矩阵K和值矩阵V:
Q=XWq; (1)
K=XWk; (2)
V=XWv。 (3)
然后将查询矩阵与键矩阵相乘,将乘积的结果除以键矩阵的秩d的算术平方根d1/2,以保证训练过程具有更稳定的梯度,从而获得新的关联度。之后经过分类器(soft maximum,softmax)归一化后对值矩阵V加权求和,将关联程度与语义相结合,最终得到自注意力层输出

ERNIE层由底层文本编码器和高层知识编码器堆叠组成。底层编码器是一个多头双向的转换器,用于获取输入的基础词汇和语义信息,底层采用BERT的掩码策略,对获取的语义信息进行初步的掩码。高层知识编码器负责将外部的知识信息整合融入模型中,多头注意力层对底层文本编码器的输出{w(i-1)1,w(i-1)2,w(i-1)3,…,w(i-1)n}与外部语义信息输入e(i)1、e(i)2分别进行处理,经信息融合后得到新的语义信息输出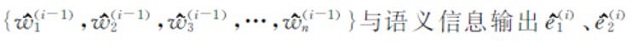 。ERNIE层输出的维度为(batch_size,hidden_size),其中hidden_size为ERNIE隐藏层的层数。
。ERNIE层输出的维度为(batch_size,hidden_size),其中hidden_size为ERNIE隐藏层的层数。
将ERNIE层最后一层的输出作为DPCNN层的特征输入,DPCNN层底层是文本区域嵌入层,对一个文本区域或者片段进行一组卷积操作后嵌入模型中; 采用2个等长卷积生成特征,在每层卷积层中加入线性修正单元(rectified linear unit,ReLU)[19]作为激活函数,增强神经网络模型的非线性,减少参数的相互依存关系,同时加快网络训练速度,防止梯度消失,缓解模型过拟合的问题; 卷积层与池化层之间采用残差连接[20],在每2层中增加一个捷径,构成1个残差块,增加了多尺度信息,极大地缓解了梯度弥散的问题。2层等长卷积和1个池化下采样组成1个模块,DPCNN层重复使用这种模块就能够抽取文本的长距离依赖关系,进一步提取文本特征。最后的池化层将整个文本表示为1个向量V。
2.4 输出层将最终提取的特征向量输入全连接层采用softmax分类器进行分类,从而得到模型最终预测的文本分类结果
N=softmax(w0V+b0)。 (5)
式(5)中:w0为权重系数矩阵; b0为偏置项; N为最终输出的文本分类标签。
3 试验与分析3.1 试验设置
表1 数据集详情
Table 1 Data set details
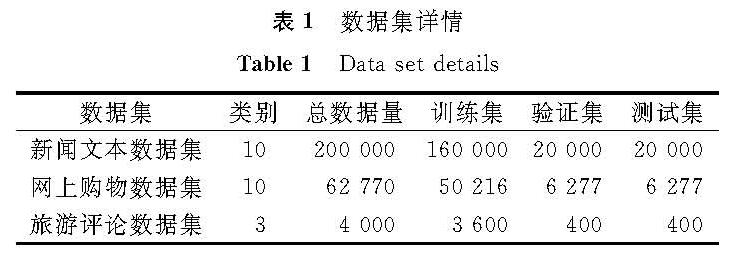
选取3个中文数据集作为试验语料,数据集详情见表1。
新闻文本数据集[21]共有金融、房产、股票、教育等10个分类,包含160 000条训练数据,20 000条验证数据,20 000条测试数据。
网上购物数据集[22]共有书籍、平板、手机等10类评论数据,包含50 216条训练数据,6 277条验证数据,6 277条测试数据。
第四届全国应用统计专业学位研究生案例大赛的旅游评论数据集[23]中,涉及正面、中性及负面评论,包含3 600条训练数据,400条验证数据,由于数据集较小,测试数据等同于验证数据。
ERNIE-DPCNN模型最大序列长度设置为128,每批次处理的数据量大小设置为64,迭代次数设置为3,学习率设置为0.000 02,使用自适应矩估计优化器(adaptive moment estimation,Adam)更新网络参数。预训练模型使用了百度发布的预训练好的“ERNIE 1.0 Base中文”模型,以中文维基百科、百度百科、百度新闻、百度贴吧等数据集为训练语料,本模型采用了12层的转换器,隐藏层层数为768,多头注意力机制参数设置为12,模型总参数大小为110 MB。
3.2 评价指标为了评估ERNIE-DPCNN模型在中文文本分类问题上的可行性,本研究采用准确率(A)、损失值(L)、精度(P)、召回率(R)及F1值作为评价指标。准确率用以衡量分类器预测结果与真实结果之间的差异; 损失值为分类器预测错误的概率; 精度指在被所有预测为正的样本中实际为正样本的概率; 召回率指在实际为正的样本中被预测为正样本的概率。F1值定义如下:
F1=(2PR)/(P+R)。 (6)
如式(6)所示,F1值是精度与召回率的调和平均,在给定阈值下,F1值越接近1,模型的性能越好。对于多分类的文本分类问题,在计算各项评价指标时,若选定其中一类为正类,则其余的类别作为负类,从而将多分类问题转换为二分类问题进行处理。
3.3 对比试验设置为了验证ERNIE-DPCNN模型在文本分类任务中的有效性,将我们提出的分类模型与下列性能较高的分类模型进行对比试验,对比模型如下。
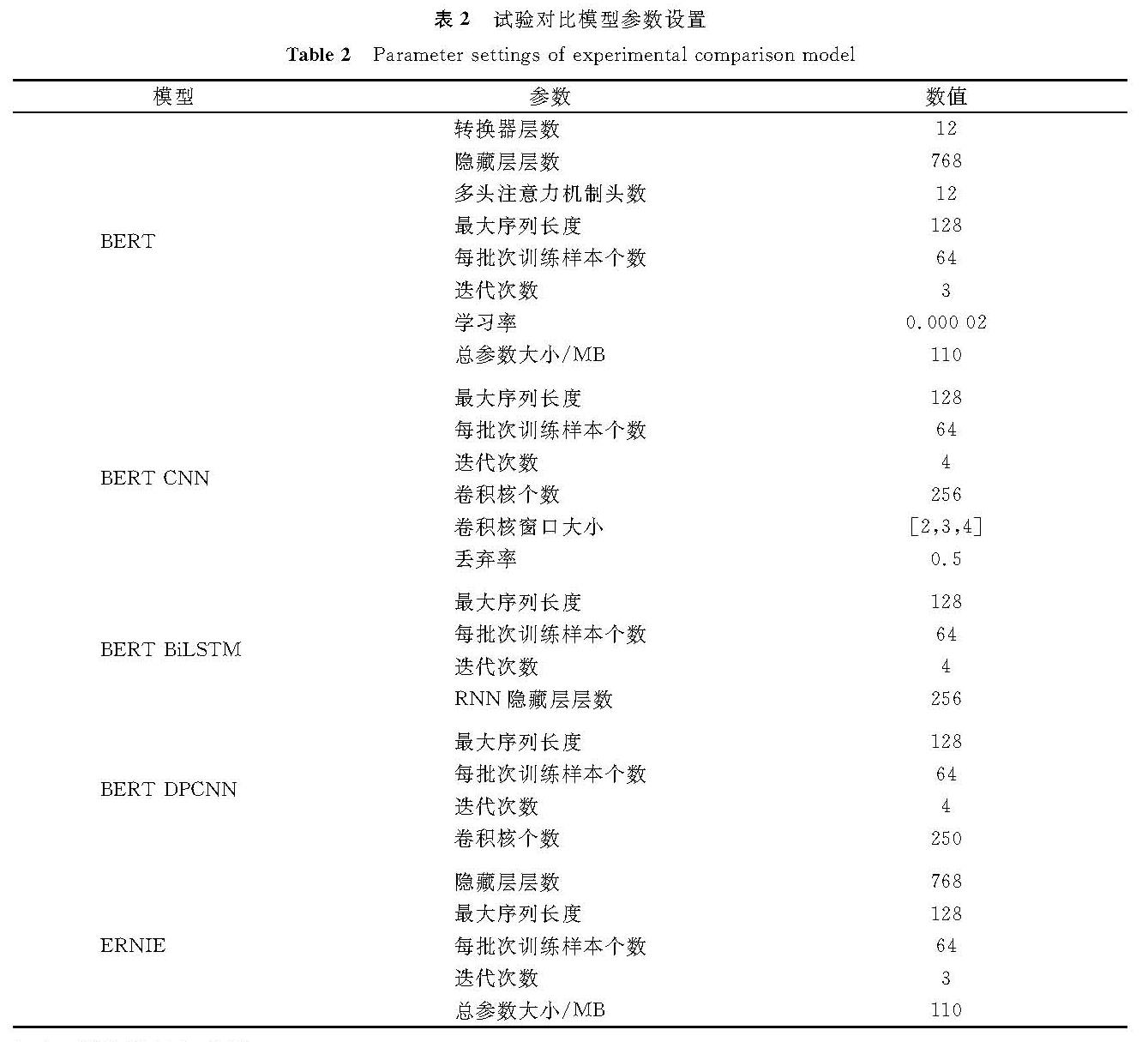
1)BERT模型:经中文预训练BERT模型得到文本特征后,通过全连接层输入到分类器中实现文本分类。
2)BERT-CNN模型:在模型1)的基础上,将预训练得到的文本特征表示输入到卷积神经网络中,做进一步的特征提取[15],通过全连接层输入分类器中实现文本分类。
3)BERT-BiLSTM模型:经模型1)中的预训练模型得到文本表示后,利用BiLSTM模型提取句子中各个词的上下文信息[14],通过全连接层输入分类器中实现文本分类。
4)BERT-DPCNN模型:经模型1)中的预训练模型得到文本表示后,利用深度卷积神经网络提取文本特征[16],并在神经网络中引入非线性ReLU激活函数,通过全连接层输入分类器中实现文本分类。
5)ERNIE模型:预训练采用“ERNIE 1.0 Base中文”模型,直接连接全连接层实现文本分类。
在模型参数设置过程中,尽量保持设置上的一致性; 由于模型结构的差异而无法达到一致时,采取最优的参数设置。试验对比模型参数设置见表2。
表2 试验对比模型参数设置
Table 2 Parameter settings of experimental comparison model
3.4 试验结果与分析3.4.1 试验结果
表3 新闻文本分类数据集的试验结果
Table 3 Test results on news-text data set%
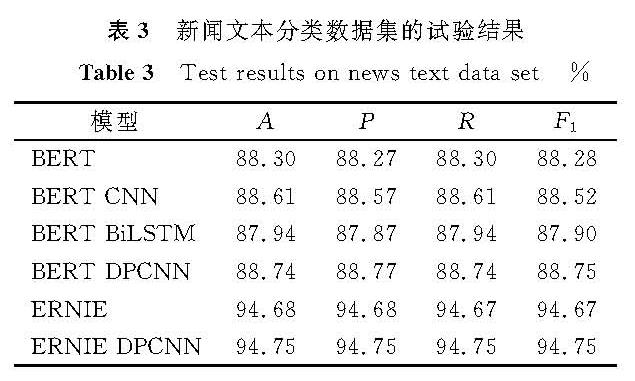
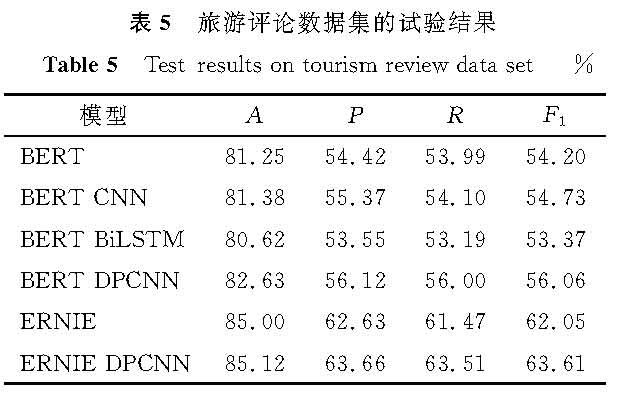
基于ERNIE的文本分类模型与基准模型各项评价指标的试验结果见表3~5。由表3~5可知,在3个数据集上的各项评价指标的值均有不同程度的提升,ERNIE-DPCNN模型在新闻文本、网上购物及旅游评论数据集上分类结果的F1值分别达到了94.75%、87.56%、63.61%,表明采用ERNIE-DPCNN模型进行文本分类的可行性和有效性。
BERT-CNN、BERT-DPCNN模型均属于CNN类别模型,BERT-BiLSTM模型属于RNN类别模型,CNN类别模型在中文文本分类任务上的各项评价指标的值都要高于RNN类别模型,说明了在中文文本分类中更注重词的提取,而RNN类别模型更注重于联系上下文的信息,并没有展现出更好的性能。同时,BERT-DPCNN模型在新闻文本、网上购物及旅游评论数据集上分类结果的准确率分别为88.74%、85.02%、82.63%,而ERNIE-DPCNN模型分类结果的准确率分别达到了94.75%、89.79%、85.12%,说明ERNIE模型比BERT模型特征提取能力更强。
此外,在新闻文本数据集上各模型分类结果的各项指标的值最高,文本分类性能最好,在旅游评论数据集上各模型分类结果的各项评价指标的值较低,可能是由于数据集数据量小、分类数据不均衡。
表4 网上购物数据集的试验结果
Table 4 Test results on online-shopping data set%
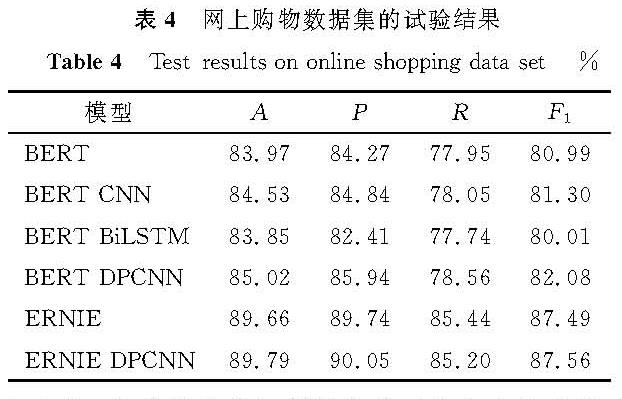
表5 旅游评论数据集的试验结果
Table 5 Test results on tourism-review data set%
3.4.2 多头注意力机制的参数对文本分类的影响
表6 多头注意力机制头数对分类结果的影响
Table 6 Impact of multi-attention heads on classification results%
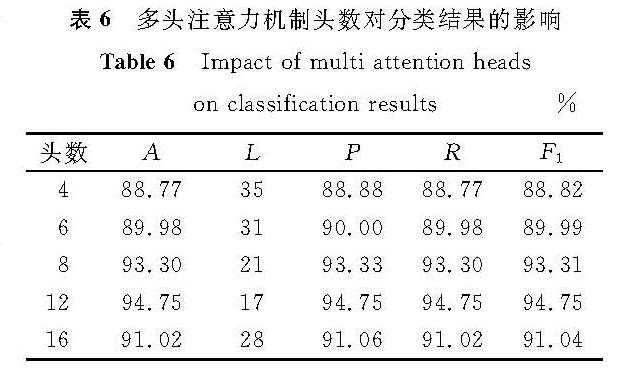
为了探究改变多头注意力机制的头数对ERNIE-DPCNN模型进行中文文本分类的影响,选择最具有代表性的新闻文本数据集进行试验,结果见表6。
从表6中可以发现,随着混合模型多头注意力机制头数的增加,文本分类的效果总体上呈逐渐提升的趋势。当多头注意力机制头数为12时,ERNIE-DPCNN模型分类效果最好,此时损失最低,损失率为17%,F1值为94.75%; 当多头注意力机制头数达到16时,文本分类效果减弱,准确率、F1值降低,损失升高。试验结果表明,适当增加多头注意力机制的头数,使得模型捕获到更多层面的语义特征,能提高ERNIE-DPCNN模型进行文本分类的性能。
3.4.3 激活函数对文本分类的影响
表7 激活函数对分类结果的影响
Table 7 Impact of activation function on classification results%
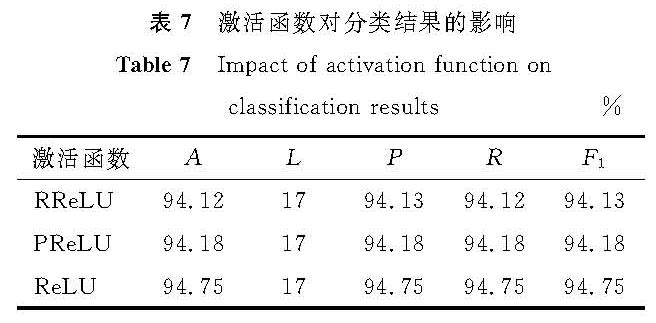
为了探究改变激活函数对ERNIE-DPCNN模型进行中文文本分类的影响,选取随机线性修正单元(randomized leaky rectified linear unit,RReLU)[19]和参数化线性修正单元(parametric rectified linear unit,PReLU)[19]作为激活函数,与ReLU激活函数进行了试验对比,选择最具有代表性的新闻文本数据集进行试验,结果见表7。
从表7可以看出,ERNIE-DPCNN模型采用这3个激活函数进行文本分类造成的损失值相同,均为17%,其中,采用ReLU激活函数进行文本分类的结果各项评价指标的值最高,分类试验效果最好,证明了ReLU激活函数对解决深度卷积网络中梯度弥散问题的有效性,在一定程度上提升了ERNIE-DPCNN模型进行文本分类的性能。
3.4.4 学习率对文本分类的影响
表8 学习率对分类结果的影响
Table 8 Impact of learning rate on classification results%
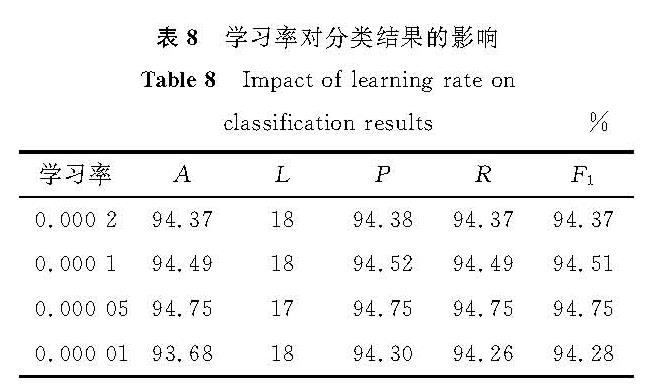
为了探究学习率对ERNIE-DPCNN模型进行中文文本分类的影响,选择最具有代表性的新闻文本数据集进行试验,结果见表8。
从表8可以看出,在一定范围内,设置小的学习率,文本分类结果的准确率、F1值会适当地提高; 当学习率设为0.000 05时,ERNIE-DPCNN模型进行文本分类的效果最好,此时损失率最低,超过了这个范围,降低学习率会使文本分类结果的准确率、F1值下降,损失率提高。
4 结 语本研究将ERNIE和深度卷积神经网络相结合,建立中文文本分类模型。为了证明模型的有效性,我们将提出的模型与其他主流中文文本分类方法进行试验对比,准确率和F1值平均分别提升了6.34%、4.82%,结果表明ERNIE-DPCNN模型能有效提高中文文本分类的性能。但是,本研究还存在一些不足之处,模型对分类数据不平衡的数据集,是否能通过加入条件随机场模型等方法来提高这类数据集分类的精度; 另外,模型在词向量表示和特征提取等方面还有一定的提升空间,这都是下一阶段工作的研究方向。
- [1] 史东辉,蔡庆生,倪志伟,等.基于规则的分类数据离群挖掘方法研究[J].计算机研究与发展,2000,37(9):1094.
- [2] 张孝飞,黄河燕.一种采用聚类技术改进的KNN文本分类方法[J].模式识别与人工智能,2009,22(6):936.
- [3] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848.
- [4] 韩众和,夏战国,杨婷.CNN-ELM混合短文本分类模型[J].计算机应用研究,2019,36(3):663.
- [5] 孟先艳,崔荣一,赵亚慧,等.基于双向长短时记忆单元和卷积神经网络的多语种文本分类方法[J].计算机应用研究,2020,37(9):2669.
- [6] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[C]//Proceedings of International Conference on Intelligent Text Processing and Computational Linguistics. Cham: Springer,2013:430.
- [7] PENNINGTON J, SOCHER R, MANNING C. GloVe: global vectors for word representation[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL Press,2014:1532.
- [8] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]//Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans: NAACL Press,2018:2227.
- [9] RADFORD A, NARASIMHAN K, SALMANS T, et al. Improving language understanding by generative pre-training[EB/OL].(2018-06-12)[2020-08-23].https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf.
- [10] DEVLIN J, CHANG M, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis: NA ACL Press,2019:4171.
- [11] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL].(2017-06-12)[2020-08-23].https://arxiv.org/pdf/1706.03762.pdf.
- [12] 张冬瑜,崔紫娟,李映夏,等.基于Transformer和BERT的名词隐喻识别[J].数据分析与知识发现,2020(4):104.
- [13] 杨玉亭,冯林,代磊超,等.面向上下文注意力联合学习网络的方面级情感分类模型[J].模式识别与人工智能,2020,33(8):753.
- [14] 谌志群,鞠婷.基于BERT和双向LSTM的微博评论倾向性分析研究[J].情报理论与实践,2020,43(8):173.
- [15] 马强,赵鸣博,孔维健,等.一种基于BERT与CNN层级连接的中文文本分类方法:CN111177376A[P].2020-05-19.
- [16] 李颖.基于BERT-DPCNN的垃圾弹幕识别改进及应用[D].上海:上海师范大学,2020.
- [17] SUN Y, WANG S H, LI Y K, et al. ERNIE: enhanced representation through knowledge integration[EB/OL].(2019-04-19)[2020-08-23].https://arxiv.org/pdf/1904.09223.pdf.
- [18] JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categorization[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: ACL Press,2017:562.
- [19] XU B, WANG N, CHEN T, et al. Empirical evaluation of rectified activations in convolutional network[EB/OL].(2015-05-05)[2020-08-23].https://arxiv.org/pdf/1505.00853.pdf.
- [20] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society,2016:770.
- [21] LI J, SUN M S. Scalable term selection for text categorization[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning(EMNLP-CoNLL). Prague: Czech Republic,2007:774.
- [22] GitHub. ChineseNlpCorpus[DB/OL].(2018-03-26)[2020-10-06].https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets.
- [23] 全国应用统计专业学位研究生教育指导委员会.案例D:旅游行业游客满意度分析[DB/OL].(2020-05-11)[2020-09-15].http://mas.ruc.edu.cn/syxwlm/tzgg/5068c3fd6e3c49919c79900d0bf3902c.htm.