 图 1 通信系统模型
Fig.1 Communication system model
图 1 通信系统模型
Fig.1 Communication system model
WANG Zhizhuo,LU Jianhong,WANG Zhongpeng.LDPC decoding algorithm based on deep residual shrinkage network[J].2022,(01):-.[doi: 10.3969/j.issn.1671-8798.2022.01.005]

为了研究瑞利衰落信道下提高低密度奇偶校验码(low density parity check,LDPC)信道译码算法纠错性能的方法,结合神经网络技术,提出一种基于深度残差收缩网络(deep residual shrinkage networks,DRSN)的归一化最小和(normalized min-sum,NMS)译码算法(简称DRSN-NMS译码算法)。首先,本译码算法使用深度残差收缩网络预测信道增益; 然后结合接收信号计算对数似然比(log likelihood ratio,LLR),将其作为译码算法的输入进行译码,DRSN通过学习接收信号中噪声的相关特征,以抑制噪声的方法使预测结果更加接近真实信道增益; 最后使用实现较简便的NMS算法进行译码。仿真试验结果表明,在高信噪比环境下,本译码算法的误码率最低时接近常规算法误码率的1/3,译码性能得到一定的提高。本研究结果可为译码算法降低误码率提供参考。
In order to explore how to improve the error correction performance of the LDPC channel decoding algorithm under the Rayleigh fading channel, a normalized minimum sum(NMS)algorithm was proposed on the basis of the deep residual shrinkage network(DRSN)decoder in combination with the knowledge of neural network. Firstly, the algorithm(abbreviated as DRSN-NMS)used the deep residual shrinkage network to predict the channel gain and then calculated the log likelihood ratio(LLR)as the input of the decoder by combining the received signal. By learning the related features of noise in the received signal to suppress the noise, the deep residual shrinkage network makes the predicted results closer to the real channel gain, and then conducted decoding with the simpler normalized minimum sum algorithm. Simulation results show that in high SNR environment the bit error rate of the proposed algorithm is at its minimum close to 1/3 of that of the conventional algorithm, with, the decoding performance improved to a certain extent. The results can provide reference for the decoding algorithm to reduce the bit error rate.
低密度奇偶校验码[1](low density parity check,LDPC)及置信传播[2](belief propagation,BP)算法因其性能优异被广泛应用到各种数据传输信道中。然而面对复杂的信道环境[3],BP译码算法还存在一定的不足,如当该算法面对较复杂的衰落信道时,算法的性能很大程度上取决于对数似然比(log likelihood ratio,LLR)的值。近年来,伴随硬件性能的提升及相关算法的飞速发展,人工智能(artificial intelligence,AI)技术也得到了进一步发展。深度学习作为AI技术的分支,在诸多领域中表现出优异的性能,这启发人们采用深度学习来解决传统通信问题。一些研究者基于分类的思路,利用神经网络进行译码,例如,李杰等[4-6]使用神经网络对接收码字进行分类译码,发现在码长较短时译码算法比传统算法在性能上有所提高,但随着码长的增加,算法的性能反而会下降。另一些研究者则采用预测的思路,辅助译码算法进行译码,例如,Liang[7]通过训练卷积神经网络(convolutional neural networks,CNN)学习残余噪声而后将其从接收码字中减去,可以明显降低译码所需迭代次数,并且提高算法的译码性能; Li[8]使用CNN网络预测相干信道的信道增益,重定义计算LLR后进行译码,随着信道相干性的提高,译码性能也随之提高。基于预测的思路可以在一定程度上避免受到码长的限制,但由于接收信号中通常含有大量的噪声,在从高噪声信道接收的信号中提取特征时,神经网络的特征学习能力下降,进而导致译码性能无法提高。因此,本研究利用深度残差收缩网络[9](deep residual shrinkage networks,DRSN),在抑制信道噪声的同时从接收信号中预测信道增益,计算LLR之后进行归一化最小和[10](normalized min-sum,NMS)算法译码。
1 系统模型
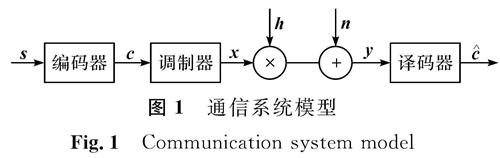
图1 通信系统模型
Fig.1 Communication system model
图1为瑞利衰落信道下的通信系统模型。图1中信息序列s经过LDPC编码后获得码字c,经二进制相移键控(binary phase shift keying,BPSK)调制后得到传输信号x,信道增益h符合瑞利分布,信道噪声n的均值为0,方差为σ2,获得接收信号y后经译码器获得码字(^overc)。
1.1 系统简介长度为k的信息序列s=[s0,s1,…,sk-1]经LDPC编码得n个比特码字c=[c0,c1,…,cn-1]。编码公式如下:
c=s G (1)
式(1)中:c为信息序列s与生成矩阵G相乘得到的编码序列; G为一个k×n的生成矩阵。编码序列c经过BPSK调制后获得的传输信号
x=1-2c (2)
传输信号x在经过无线传输信道后成为接收信号y=[y0,y1,…,yn-1]。信号向量的表达式为
y=hx+n (3)
式(3)中:n为高斯白噪声; 信道增益h=[h0,h1,…,hn-1],符合瑞利分布,h中的元素hi可表示为

式(4)中:a、b为独立同分布的高斯变量。
1.2 BP译码算法BP译码算法是软判决译码,因此需要通过接收码字y计算出对应LLR值后送入译码器译码。LLR的计算公式如下:
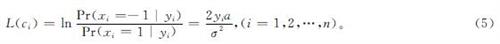
式(5)中:L(ci)为第i位接收信号的LLR; xi、yi分别为第i位传输码字和第i位接收信号; α为常数,其值为0.886 2; σ2为加性高斯白噪声的方差。
BP译码算法的实质为LLR在变量节点和校验节点之间迭代更新。对符号进行定义:L(ci)表示第i位接收码字的LLR,L(Qi)表示第i位译码判决的概率信息。L(qij)是从变量节点vi到校验节点cj的信息,该步骤称为变量节点更新; 反之,L(rji)更新表示校验节点的更新。校验节点与变量节点更新的公式如下:
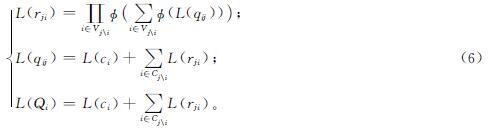
式(6)中:
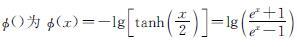
Vj为与节点j相连的所有变量节点集合; Vj\i为除了与i相连的其他点的集合; ci为与节点i相连的所有校验节点集合; Cj\i为除了与j相连的其他点的集合。BP译码流程如图2所示。
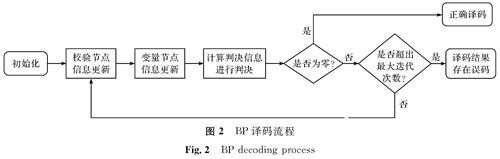
图2 BP译码流程
Fig.2 BP decoding process
1.3 NMS译码算法
BP译码算法虽性能优越,但在校验节点更新这一步骤上,由于计算复杂度极高且不利于硬件实现,因而降低了算法的可行性。为了降低译码时的计算复杂度,提出以牺牲一部分译码性能为代价,简化计算的最小和[11](minimum sum,MS)译码算法。简化算法的公式如下:

为弥补MS算法在性能上的损失,在MS算法中加入修正因子以提高算法的可靠性,提出归一化最小和[10](NMS)译码算法。优化后的公式如下:
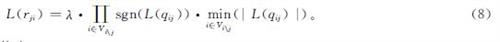
式(8)中:λ为修正因子,其值小于1。
表1为不同译码算法校验节点更新的算法复杂度,表中dc表示校验矩阵中的行重。图3显示了码长为3 872、码率为3/4的LDPC码3种译码算法的性能比较结果,其中NMS算法中使用的修正因子λ=0.797。从图3中可以看出,由于算法被简化,MS算法的性能相比BP译码算法有了不小的损失,然而NMS对算法进行了补偿,进而使得译码的性能接近BP译码算法。

表1 不同译码算法校验节点更新的算法复杂度
Table 1 Algorithm complexity of update check nodes with different decoding algorithms
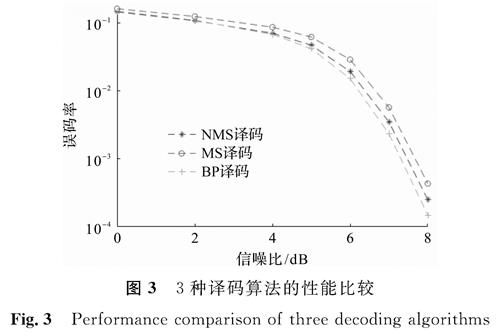
图3 3种译码算法的性能比较
Fig.3 Performance comparison of three decoding algorithms
2 基于DRSN的译码算法的提出2.1 译码模型
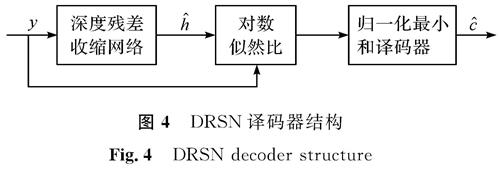
图4 DRSN译码器结构
Fig.4 DRSN decoder structure
DRSN译码器结构如图4所示,接收码字y通过深度残差收缩网络预测信道增益(^overh)后,将参数代入式(9)中计算LLR,最后经译码器输出码字(^overc)。
结合预测信道增益,LLR的计算公式如下:
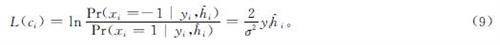
式(9)中:(^overh)i为第i个信道增益。
2.2 DRSN工作原理DRSN是深度残差网络[12](deep residual network,ResNet)的改进网络,它集成深度残差网络、注意力机制[13]和软阈值函数[14]。DRSN的工作原理可以总结为:通过注意力机制关注不重要的特征,并通过软阈值函数将该特征置零; 如此反过来便将有用特征保留下来,进而加强神经网络从含噪声信号中提取有用特征的能力。
2.2.1 软阈值函数软阈值函数在许多信号去噪算法中被视为关键性步骤。其基本工作原理是:先将原信号转换到一个可以将信息按照是否重要来分开的领域中,然后通过设置阈值将不重要的特征置零。完成这样的任务关键是找到一类能够将任务信息与噪声信息分开,并且能将噪声信息置零的滤波器。从整体上来看,大部分滤波器只能针对特定场景进行处理,而神经网络以其强大的学习能力可以通过软阈值函数来适应复杂信道环境。软阈值函数的表达式如下:

式(10)中:x为输入特征; y为输出特征; τ为阈值。软阈值函数不是将负特征设置为零,而是将接近零的特征设置为零,这样可以有效保留有用的负特征,降低噪声对算法结果精确度的影响。而软阈值函数输出对输入的导数是1或0,这样可以有效降低梯度爆炸和梯度消失的风险。
2.2.2 注意力机制在计算机视觉领域中,注意力机制的原理是在快速扫描全区域后,将注意力重点放在感兴趣的区域,为不同重要程度的区域赋予不同比例的权重,越重要的区域占据的权重越大。故本研究通过训练一个小神经网络,将获取的权重应用到各通道中以降低无用信息占据的比重,从而提高预测的准确率。
2.2.3 ResNetResNet是在经典CNN的基础上衍生出来的,其引入残差块[12](residual building units,RBUs)概念,残差块结构如图5所示。图5中的x是输入特征图,F()是残差部分,由卷积层组成。该ResNet解决神经网络随着层数的增加而精度下降的问题,并且由于需训练的参数较少,减少了运算成本。卷积操作如图6所示,卷积核在输入向量上滑动提取特征,卷积运算公式为

式(11)中:yi,j为第i层第j个通道的输出特征映射; ki,j为第i层第j个卷积核; bi,j为对应层特征偏置项。relu为激活函数,作为神经网络的基本组成部分用于非线性变换,其公式为
y=max(x,0) (12)
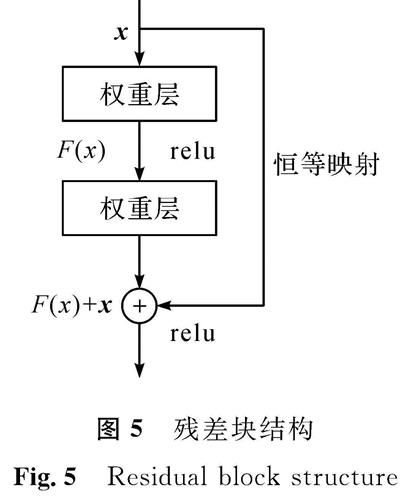
图5 残差块结构
Fig.5 Residual block structure
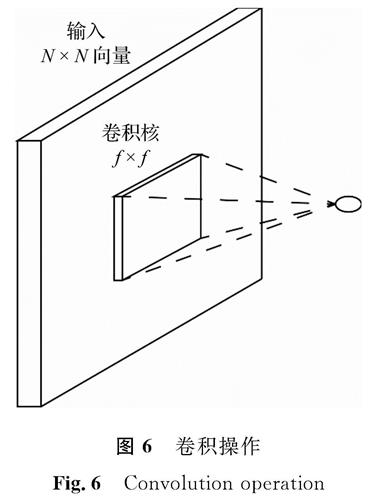
图6 卷积操作
Fig.6 Convolution operation
2.2.4 DRSN
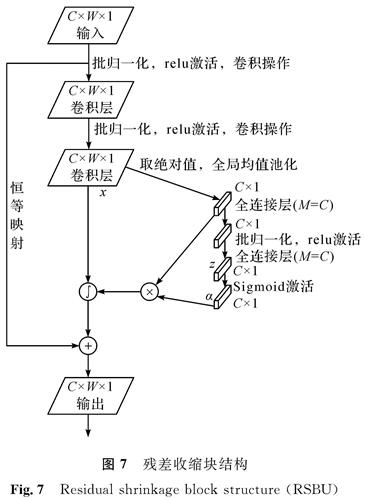
图7 残差收缩块结构
Fig.7 Residual shrinkage block structure(RSBU)
DRSN在提取特征的过程中,会通过抑制无关噪声来提高特征提取的准确率。它的核心思想是神经网络在学习的过程中,在残差块结构中添加一个小型的子网络用于自适应阈值设置,以去除与当前任务无关的特征信息,提高神经网络预测的准确率。在残差块的基础上加入子网络,用于清除冗余信息,新结构即残差收缩块,其结构如图7所示。图7中,C为通道数目; W为特征宽度; M为子网络神经元个数; ∫表示对权值进行分配; Sigmoid为激活函数,将神经元输出范围限制在(0,1)中。
2.3 DRSN-NMS译码算法本研究提出的译码算法由DRSN和NMS算法相结合,而为了使DRSN能够有效地工作,需要依次完成以下3个任务。
1)获得训练数据集。通过通信仿真程序获得接收信号y的数据。按本文1.1节中的方法生成数据,将对应的信道增益h作为接收信号y的数据标签。所有的数据集使用不同的信噪比(signal noise ratios,SNRs){0,2,4,6,7,8},每个SNR生成5 000组数据。各信噪比的比例相同,以保证神经网络对各噪声功率的泛化能力。
2)搭建神经网络。神经网络结构的搭建需要结合数据特征来进行。本研究用的是一维数据,故按照图7搭建一维DRSN网络结构,卷积核也是一维。
3)为训练神经网络设置合适的超参数。本研究所使用的DRSN网络主要结构为1D-CNN[15],整个神经网络由一维卷积和2个小型全连接层组成。为了保持每层的大小相同,我们采用零填充操作,在每层上进行卷积操作后,对下一层的边缘进行零填充。DRSN的网络结构参数参考文献[8],具体参数见表2。表2中,输出大小为每层经过卷积计算后输出的张量大小,而网络结构括号中的内容分别代表卷积核长度及特征图通道数。通过一系列的试验,我们确定了适合神经网络训练的超参数,见表3。
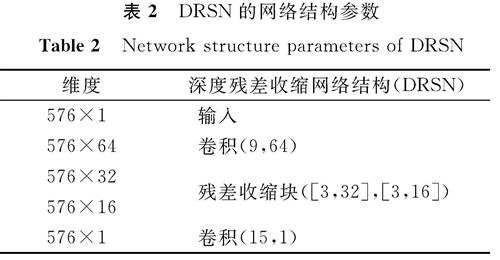
表2 DRSN的网络结构参数
Table 2 Network structure parameters of DRSN
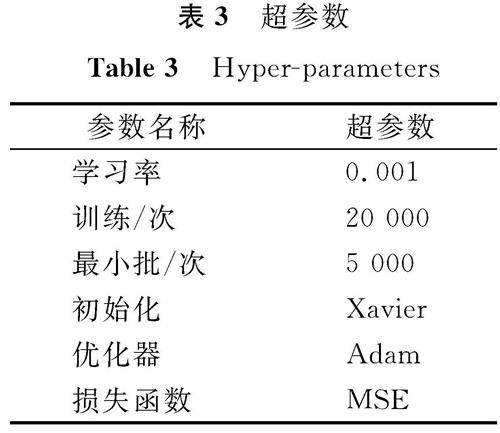
表3 超参数
Table 3 Hyper-parameters
本研究使用的优化算法为自适应矩估计(adaptive moment estimation,Adam)[16],这是一种可以替代传统随机梯度下降的优化算法。该算法通过计算梯度一阶矩和二阶矩给不同的权重设置自适应学习率,加快神经网络的训练,从而尽快获得结果。使用Xavier初始化方法是因为Xavier比随机化初始化方法性能更好[8]。均方误差(mean square error,MSE)是一种常用的损失函数,用于衡量预测值和真实值之间的差距,其值越小代表网络预测结果越接近真实值,计算公式如下:
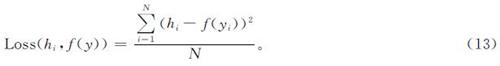
式(13)中:N为输入码字的长度; f(yi)为神经网络的输出值即特征提取值(^overh)。
3 性能分析与仿真比较本研究仿真试验使用的软件平台为Pycharm,神经网络工具是TensorFlow1.6。通过修改基于文献[7]的源码github.com/liangfei-info/Iterative-BP-CNN,参考源码github.com/Leo-Chu/Deep-learning-for-LDPC-decoding进行仿真。仿真使用LDPC码,其码块长度为576,码率为0.75。将文献[8]中所使用的网络结构与本研究所使用的网络损失值做比较,CNN对应的损失值为0.104 477,而DRSN所对应的损失值为0.096 94,从中可以看出,DRSN网络经过训练后相比CNN的损失值降低了0.047 83,网络预测准确率提高。
![图8 文献[8]中译码算法仿真<br/>Fig.8 Simulation of decoding algorithm mentioned in literature [8]](2022年01期/pic52.jpg)
图8 文献[8]中译码算法仿真
Fig.8 Simulation of decoding algorithm mentioned in literature [8]
将译码算法的迭代次数均设置为25。图8为用文献[8]中译码算法进行的仿真,图中3条曲线分别是使用标准BP译码后的误码率; 使用真实信道增益计算LLR,经BP译码后的误码率; 以及使用CNN神经网络预测信道增益计算LLR,经BP译码算法后的误码率。由图8可知,使用真实信道增益计算LLR的译码算法(RG-BP译码)误码率远低于其他2种算法,可见当神经网络预测的信道增益越接近真实信道增益时,译码算法的误码率越低。
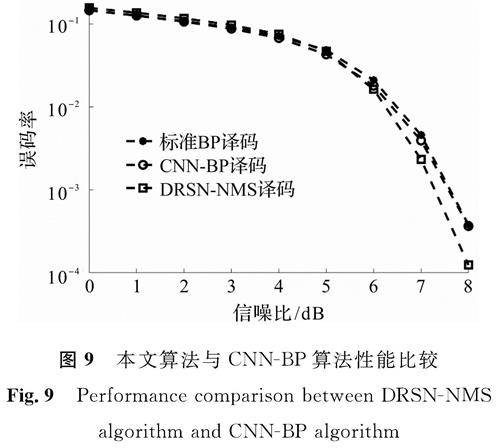
图9 本文算法与CNN-BP算法性能比较
Fig.9 Performance comparison between DRSN-NMS algorithm and CNN-BP algorithm
将文献[8]中提出的CNN-BP译码算法与本文使用的算法进行比较,结果如图9所示。从图9可以看出,在SNR∈(0,4)阶段,本研究使用的DRSN-NMS译码算法的误码率曲线和文献[8]中所提出的CNN-BP译码算法的误码率曲线,均逼近标准BP译码算法的误码率曲线; 而在SNR∈(4,8)阶段,DRSN-NMS算法的误码率开始低于其他2种算法。DRSN-NMS误码率曲线低于CNN-BP的误码率曲线,以及DRSN的损失值低于CNN的损失值可以表明:预测的信道增益越接近真实信道增益,译码算法的译码性能越好,有一定的可信度。因为神经网络预测中存在对当前任务造成干扰的无用特征,借助DRSN将这些干扰特征尽可能地去除,可以使神经网络预测信道增益更加准确,而凭借更准确的预测增益,可以进一步提高译码性能。与CNN相比,DRSN在本文应用中增加的计算复杂度存在于恒等映射的一次加法与子网络中的全连接层计算中,但相比整个神经网络的计算复杂度极小。利用神经网络预测信道增益方法辅助译码,是一种以增加计算复杂度为代价的算法。因此为了降低计算复杂度,选择NMS算法进行译码,尽管其性能逊色于BP算法,但由于该算法计算复杂度低于BP算法,在降低算法复杂度上较有利。仿真试验结果表明,DRSN-NMS算法的译码性能在高信噪比情况下超过标准BP译码算法。
4 结 语本研究提出基于深度残差收缩网络的归一化最小和译码算法,借助DRSN网络抑制噪声的干扰,从而提高神经网络的预测准确率。从含有噪声的接收信息中获得更接近真实值的信道增益,并将其用于计算对数似然比,然后经易于实现的归一化最小和译码算法进行译码操作。试验结果表明,本研究提出的算法在信噪比高的信道环境下优于传统BP译码算法,这进一步验证了本算法的有效性。
- [1] GALLAGER R G. Low-density parity-check codes[J].IRE Transactions on Information Theory,1962,18(1):21.
- [2] URBANKE R L, RICHARDSON T J. The capacity of low-density parity-check codes under message -passing decoding[J].IEEE Transactions on Information Theory,2001,47(2):599.
- [3] PHAM T L, NGUYEN T, THIEU M D, et al. An artificial intelligence-based error correction for optical camera communication[C]//2019 Eleventh International Conference on Ubiquitous and Future Networks. Zagreb, Croatia: IEEE,2019.
- [4] 李杰.基于深度学习的LDPC译码算法研究[D].广州:华南理工大学,2016.
- [5] 汪智开.LDPC码的深度神经网络译码研究[D].广州:华南理工大学,2019.
- [6] 薛飞.基于神经网络的LDPC译码算法研究[D].成都:电子科技大学,2013.
- [7] LIANG F, SHEN C, WU F. An iterative BP-CNN architecture for channel decoding[J].IEEE Journal of Selected Topics in Signal Processing,2018,12(1):144.
- [8] LI J, ZHAO X, FAN J, et al. A double -CNN BP decoder on fast fading channels using correlation information[C]//2019 IEEE/CIC International Conference on Communications in China(ICCC). Changchun: IEEE,2019.
- [9] ZHAO M, ZHONG S, FU X, et al. Deep residual shrinkage networks for fault diagnosis[J].IEEE Transactions on Industrial Informatics,2020,16(7):4681.
- [10] WU X, SONG Y, JIANG M, et al. Adaptive-normalized/offset min-sum algorithm[J].IEEE Communications Letters,2010,14(7):667.
- [11] FOSSORIER M P C, MIHALJEVIC M, IMAI H. Reduced complexity iterative decoding of low-density parity check codes based on belief propagation[J].IEEE Transactions on Communications,1999,47(5):673.
- [12] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE,2016:770.
- [13] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2011.
- [14] PENG Y H. De-noising by modified soft-thresholding[C]//IEEE Asia-pacific Conference on Circuits & Systems. Tianjin: IEEE,2002:760.
- [15] ZHAO M, KANG M, TANG B, et al. Deep residual networks with dynamically weighted wavelet coefficients for fault diagnosis of planetary gearboxes[J].IEEE Transactions on Industrial Electronics,2018,65(5):4290.
- [16] 伊恩·古德费洛,约书亚·本吉奥,亚伦·库维尔.深度学习[M].赵申剑,译.北京:人民邮电出版社,2017.