 图 2 特征对齐方法
Fig.2 Method of feature alignment
图 2 特征对齐方法
Fig.2 Method of feature alignment
LI Junfeng,LOU Qiong,QIAN Yaguan,et al.Cross-modality person re-identification based on pixel alignment and feature alignment[J].Journal of Zhejiang University of Science and Technology,2022,(03):251-260.[doi:10.3969/j.issn.1671-8798.2022.03.007]

行人重识别是在多个不同摄像机视角下检索同一目标人物的过程[1],广泛应用于视频监控、安全防范和智能城市,因而在计算机视觉中受到越来越多的关注[2-4]。然而,在夜晚或者黑暗的环境下,可见光摄像机无法捕获有效的外观信息,行人重识别受到限制,对此大多数监控摄像机可以自动从可见光(red-green-blue,RGB)模式切换到红外(infrared,IR)模式。这有助于摄像机在夜间工作,为研究真实场景中的跨模态匹配问题提供了方便。
可见光-红外跨模态行人重识别要匹配行人在不相交摄像机下的RGB图像和IR图像,除了面对由不同的姿势、光照、视角和遮挡引起的识别困难之外,还要减少RGB和IR图像之间较大的跨模态差异。陈丹等[5]将跨模态行人重识别中现有的方法分为三类,即基于特征学习的方法、基于度量学习的方法、基于模态转换的方法。现有的大多数跨模态行人重识别方法主要还是通过特征学习和度量学习来减少RGB和IR图像之间的跨模态差异。Wu等[6]首次定义了可见光-红外跨模态行人重识别问题,并收集了一个大型跨模态数据集SYSU-MM01,还提出了一种深度零填充方法,为跨模态行人重识别的研究打开了大门。Ye等[7]指出跨模态行人重识别同时受到跨模态和模态内变化的影响,并对此提出了特征学习和度量学习的两步框架。然而,这样的两阶段训练过程需要大量的人工干预,并不实用; 于是Ye等[8]又提出了一种端到端的双流网络来同时处理跨模态和模态内变化,避免了大量的人工干预。但是上述方法存在两个问题:一是仅从特征级别增加约束,直接将不同模态的图像共享到同一特征空间中进行特征提取,这就忽略了模态差异的独特性,难以弥补两种模态之间较大的跨模态差异; 二是直接对RGB和IR图像进行全局集合级对齐,容易导致某些实例失调。针对第一个问题,有研究通过模态转换来缩小模态间的差距,如冯敏等[9]使用循环生成对抗网络和度量学习来分别减少模态差异和外观差异; Wang等[10]联合图像级和特征级网络将RGB和IR图像互相转换,以减少模态差异和外观差异; Wang等[11]还提出了基于像素级和特征级约束的对齐生成对抗网络(alignment generative adversarial network,AlignGAN),该模型不仅能够减少跨模态和模态内差异,还能保持身份一致性。针对第二个问题也有新方法提出,即通过同时执行全局集合级和细粒度实例级对齐来解决,如Wang等[12]将RGB和IR图像分解为模态特定特征和模态不变特征,通过分离模态特定特征进行集合级对齐,交换模态特定特征生成配对图像进行实例级对齐。
综上所述,现有的跨模态行人重识别方法大都是单纯依靠集合级对齐的特征对齐方法,这种方法很难弥补较大的跨模态差异,而且容易忽略实例级对齐。因此,我们提出了联合像素对齐和特征对齐的新方法,本方法包括像素对齐和特征对齐2个模块,可以同时解决上述两个问题。
1 跨模态行人重识别模型针对可见光-红外跨模态行人重识别提出的模型框架如图1所示。我们提出的方法包括像素对齐和特征对齐2个模块。在像素对齐模块中,利用AlignGAN[11]将RGB图像生成假的IR图像,这样做不仅缩小了数据间的跨模态差距,而且还增广了数据集。在特征对齐模块中,首先利用编码器和解码器分解交换模态特定特征来生成跨模态配对图像,然后使用与模态不变编码器共享权重的编码器进行集合级对齐,并通过最小化配对图像之间的距离来进一步进行实例级对齐[12]。此外,我们还将嵌入非局部块[13]的ResNet-50网络作为卷积神经网络(convolutional neural network,CNN)的骨干,用于捕获长距离依赖关系,这有效建立了图像中不同像素点之间的联系,提升了网络性能。

图1 跨模态行人重识别模型框架
Fig.1 Framework of RGB-IR re-ID model
图1中:Xrgb为真实的RGB图像; Xir为真实的IR图像; Gp为像素生成器; X'ir为Xrgb通过Gp生成的假IR图像; Gf为特征生成器; Mir为真实的IR特征; M'ir为假的IR特征;(Xir,Mir)表示真实的红外图像特征对;(X'ir,M'ir)表示假的红外图像特征对; Dj为联合判别器; Esrgb为RGB模态特定编码器; Ei为模态不变编码器; Esir为IR模态特定编码器; Msrgb为RGB模态特定特征; Mirgb为RGB模态不变特征; Msir为IR模态特定特征; Miir为IR模态不变特征; Drgb为RGB解码器; Dir为IR解码器; Xrgb2ir为通过Drgb解码生成的新的IR图像,它与Xrgb组成跨模态配对图像; Xir2rgb为通过Dir解码生成的新的RGB图像,它与Xir组成跨模态配对图像; Esl为集合级编码器; Eil为实例级编码器。
1.1 像素对齐模块在这一模块中,我们的目的是将SYSU-MM01数据集中的所有RGB图像通过AlignGAN转换生成假IR图像X'ir,并将其与SYSU-MM01数据集组成的新数据集作为整个框架的输入图像,从数据集源头缩小跨模态差距。AlignGAN由像素生成器、特征生成器和联合判别器3个部分组成。像素生成器将真实的RGB图像Xrgb转换成假的IR图像X'ir,以此来缩小跨模态差距,生成的假IR图像X'ir在拥有IR风格的同时原有的RGB身份信息还能保持不变。特征生成器将真实的红外图像Xir和假的红外图像X'ir编码到共享空间中,以此来减少由不同姿势、视角、照明等引起的模态内变化。联合判别器可以鉴别输入图像的真伪,同时保持身份的一致性。
1.1.1 像素生成器为了减少RGB和IR图像之间较大的跨模态差异,引入了一个像素生成器Gp,其生成的假红外图像X'ir可用于弥合RGB和IR图像之间的差距。像素生成器和判别器之间的生成对抗作用[14]可以使X'ir更加真实,其产生的对抗损失

式(1)中:X为图像; M为图像特征; (X,M)为图像特征对;(X'ir,Mir)为假红外图像和真红外特征的图像特征对。
虽然Lpixgan使生成的假红外图像X'ir更加真实,但无法保证X'ir与对应的RGB图像Xrgb保持相同的内容,如姿势。为此采取了3个措施:首先,引入了一个循环一致损失[15],将RGB(IR)图像映射到IR(RGB)图像,然后重现原始RGB(IR)图像。循环一致损失
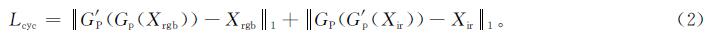
式(2)中:=·=1为L1距离; Gp为从RGB图像到IR图像的映射; G'p为从IR图像到RGB图像的映射。
其次,引入了一个分类损失,促使X'ir与对应的Xrgb身份保持一致。分类损失

式(3)中:p(·)为输入真实身份的预测概率。假红外图像X'ir的真实身份的预测概率与相应的原始RGB图像Xrgb相同。
最后,引入了一个像素级三重态函数。普通三重态损失及像素级三重态损失的定义分别为
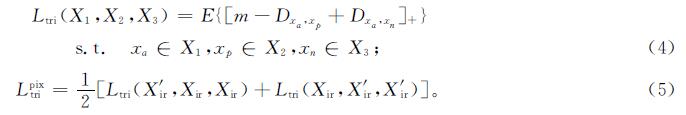
式(4)中:[x]+=max(0,x); m为一个边际系数,通常设置为1.0; Dx1,x2为x1和x2之间的余弦距离; xa和xp为属于同一身份的正对; xa和xn为属于不同身份的负对。
综上所述,像素对齐模块的总损失
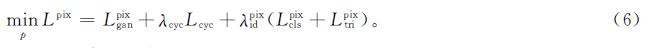
式(6)中:λcyc和λpixid为权重,λcyc设为10,λpixid通过交叉验证设为1.0。
1.1.2 特征生成器为了减少由不同姿势、照明、视角、遮挡等引起的模态内变化,引入一个特征生成器Gf。特征生成器和判别器的对抗损失
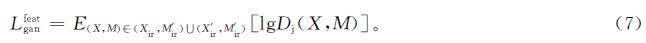
式(7)中:(Xir,M'ir)为真红外图像和假红外特征的图像特征对。
特征生成器通过最小化基于身份的分类损失[16]和三重态损失[17]来达到学习更加真实的身份特征的目的。分类损失和三重态损失分别为
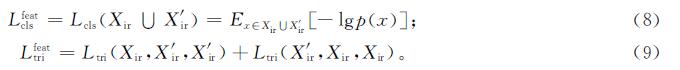
式(8)~(9)中:(Xir∪X'ir)表示特征生成器以Xir和X'ir作为输入。
因此,特征对齐模块的总损失

式(10)中:λfeatgan通过交叉验证后设为0.1。
1.1.3 联合判别器为了学习身份一致性特征,引入一个联合判别器Dj。联合判别器以图像特征对(X,M)作为输入,以0或1作为输出,其中0表示假,1表示真。目标函数
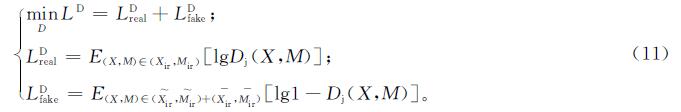
式(11)中:(Xir~,M~ir)表示图像和特征是同一身份但至少有一个是假的;(Xir-,M-ir)表示图像和特征属于不同的身份但都是真实的。
1.2 特征对齐模块传统特征对齐方法通过缩小RGB和IR图像集合之间的距离进行集合级对齐,这种做法忽略了模态差异的独特性,可能会导致某些实例难以匹配。而本文的特征对齐方法是首先将模态特定特征和模态不变特征进行分离,在模态不变的特征空间中进行集合级对齐,然后通过交换模态特定特征生成跨模态配对图像,进行实例级对齐。具体的特征对齐方法如图2所示。
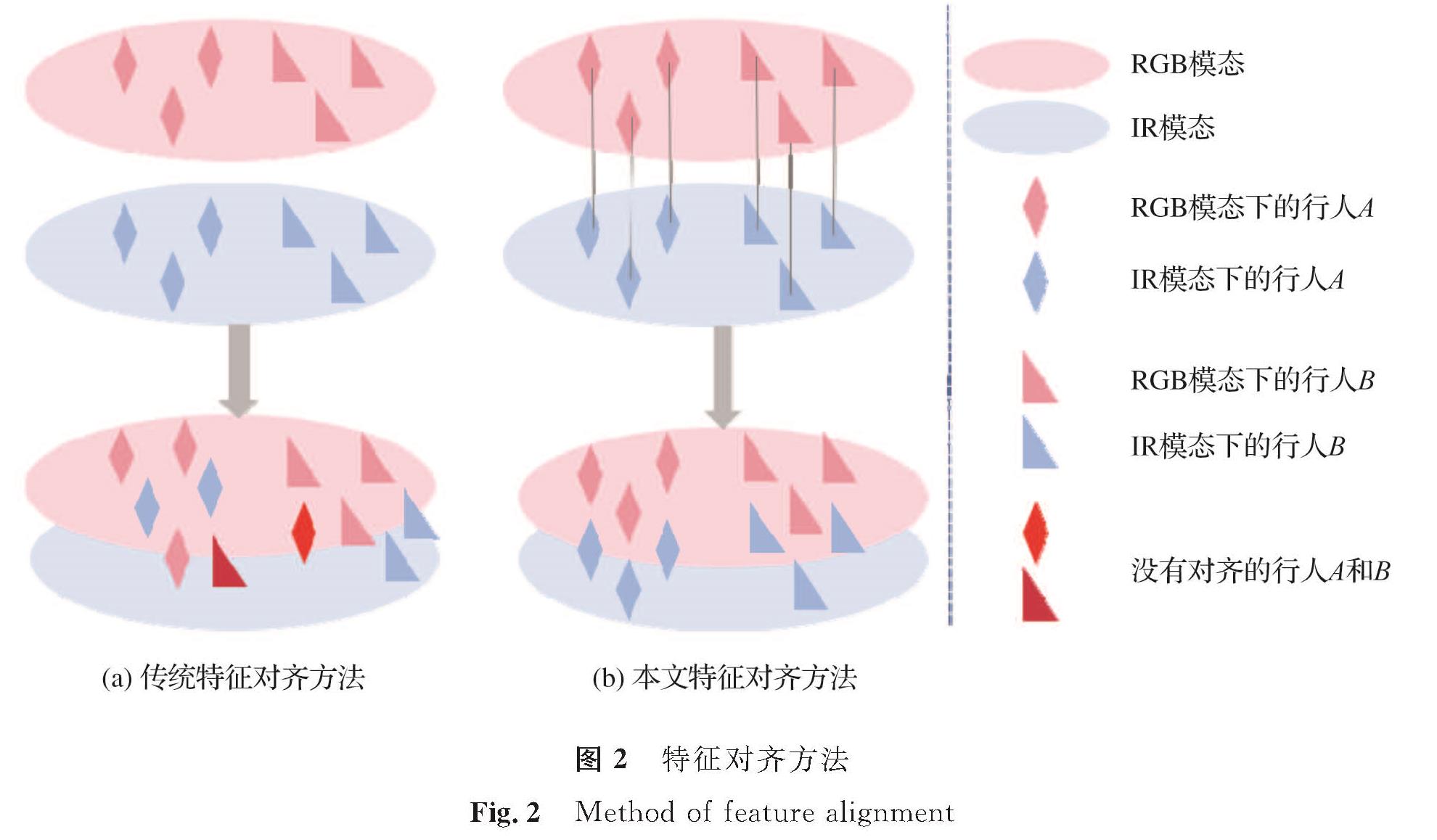
图2 特征对齐方法
Fig.2 Method of feature alignment
1.2.1 跨模态配对图像生成
将图像分解为模态特定特征和模态不变特征,通过交换未配对图像的模态特定特征生成配对图像,2个配对图像之间具有相同的模态不变特征,如姿势,但具有不同的模态特定特征,如衣服颜色。跨模态配对图像生成模块由3个编码器Ei、Esrgb、Esir和2个解码器Drgb、Dir组成。
编码器负责分解RGB和IR图像的特征。具体而言,模态不变编码器Ei负责学习RGB和IR图像的模态不变特征,模态特定编码器Esrgb和Esir分别负责学习RGB和IR图像的模态特定特征。模态特定特征Msrgb、Msir及模态不变特征Mirgb、Miir分别如下:
Msrgb=Esrgb(Xrgb),Msir=Esir(Xir) (12)
Mirgb=Ei(Xrgb),Miir=Ei(Xir) (13)
解码器负责通过交换模态特定特征生成配对图像。具体而言,使用RGB图像的模态不变特征Mirgb和IR图像的模态特定特征Msir来生成新的IR图像Xrgb2ir,它既包含来自RGB图像的模态不变信息,还包括来自IR图像的模态特定信息,并与RGB图像Xrgb配对。同样也可以生成RGB图像Xir2rgb与IR图像Xir配对。具体过程如下:
Xir2rgb=Dir(Miir,Msrgb),Xrgb2ir=Drgb(Mirgb,Msir) (14)
为了生成更加真实的配对图像,需完成以下3步:首先,构建一个重建损失,使分离的特征重建为原始图像,
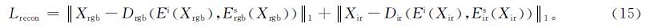
其次,引入一个循环一致损失,以保证生成的图像可以保持原有的模态不变特征,并能被翻译回原始版本。循环一致损失

式(16)中:Xir2rgb2ir和Xrgb2ir2rgb为循环重建的图像。
最后,由于重建损失和循环一致损失的引入会导致图像模糊,因此应用了对抗性损失,使图像更加真实。运用判别项Disrgb和Disir来区分RGB和IR模态上的真实图像和生成图像,而运用编码器和解码器使真实图像和生成图像无法区分,以此来达到使生成的图像更加真实的目的。生成对抗网络(generative adversarial network,GAN)损失
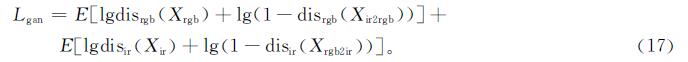
在跨模态配对图像生成模块中,模态不变编码器被训练以消除模态特定特征。而集合级编码器Esl的权重与模态不变编码器Ei共享,因此它可以将消除过模态特定特征的RGB和IR图像映射到共享的特征空间中,以减少集合级之间的模态差异。
实例级编码器Eil将配对前图像两两对齐,解决实例失调的问题。实例级编码器Eil将集合级对齐特征M映射到一个新的特征空间T中; 然后,通过最小化它们的KL散度(Kullback-Leibler divergence,KLD),对跨模态配对图像进行对齐。实例级特征对齐损失
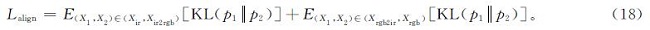
式(18)中:p1=C(t1)和p2=C(t2)分别为x1和x2在所有恒等式上的预测概率; t1和t2分别为特征空间T中x1和x2的特征; C为用完全连接层实现的分类器。
再加上一个身份识别特征学习,包括分类损失和三重态损失,以克服模态内差异,
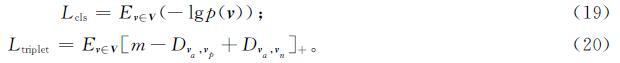
式(19)~(20)中:v为特征向量,v=Eil(Esl(X)); V为图像的特征向量集; p(·)为分类器C预测的输入特征向量正确的预测概率; va和vp为属于同一人的正对特征向量,va和vn为属于不同人的负对特征向量; m为边缘参数; [x]+=max(0,x)。
总损失
L=λcycLcyc+λganLgan+λalignLalign+λreid(Lcls+Ltriplet) (21)
式(21)中:λcyc=10; λgan=1; λreid=1; λalign由网格搜索决定。
1.3 网络模块捕捉长距离依赖关系即图像中非相邻像素点之间的关系,有利于对视觉场景的全局理解。传统的卷积神经网络一般通过重复堆叠卷积层来获取长距离依赖关系,随着层数的加深,感受野也逐渐加大,最终捕获全局感受野。然而,这种方式存在以下弊端:一是计算效率低,层的加深意味着参数量的增加; 二是优化过程困难,需要花更多精力在优化过程中; 三是建模困难,尤其是对于那些需要在不同距离位置传递信息的多级依赖项。
为了解决上述问题,非局部网络通过自注意力机制[18]聚集来自其他位置的信息,进而构建长距离依赖关系。首先,计算查询位置和所有位置之间的成对关系形成关注图; 然后,基于关注图定义的权重,通过加权和来聚集所有位置的特征; 最后,聚集的特征最终被添加到每个查询位置的特征上以形成输出。使用非局部运算有如下优点:非局部运算可以通过计算任意两个位置之间的相互作用,直接得到长距离相关性; 由于非局部操作输入输出大小保持不变,因此很容易与其他操作进行结合。
一般非局部运算[19]定义为

式(22)中:i为查询位置; j为其他位置; x为输入图像特征,y为输出图像特征,x与y大小相同; g(xj)为位置j处的输入特征,为简便起见,只考虑线性嵌入形式即g(xj)=wgxj,其中wg为要学习的权重矩阵(例如1×1卷积); f(xi,xj)表示位置i和j之间的关系,默认使用嵌入式高斯版本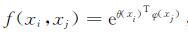 ,因为它的softmax在[0,1]范围内,所以易于可视化,其中θ(xi)=wθxi和φ(xj)=wfxj为两个嵌入; C(x)表示归一化因子,设
,因为它的softmax在[0,1]范围内,所以易于可视化,其中θ(xi)=wθxi和φ(xj)=wfxj为两个嵌入; C(x)表示归一化因子,设 。
。
将非局部操作集成为非局部模块,这样做可以方便集成到许多网络结构中。非局部块定义为
zi=wzyi+xi (23)
式(23)中:“+xi”表示残差连接[20]。嵌入式高斯版本的非局部块[13]如图3所示,其中X为输入的图像,它的大小为H×W×1 024,H为图像的长,W为图像的宽,1 024为图像的通道数; θ、φ、g的输入均为H×W×512的图像,通道数为512; Z为式(23)中描述的非局部块,它的大小同为H×W×1 024,这样便于非局部块嵌入到其他网络中。
深度神经网络的核心问题在于捕捉长距离依赖关系。非局部块不仅可以高效地捕捉长距离依赖关系,而且可以灵活地与深度神经网络结合,它的出现有助于解决深度神经网络的核心问题。将非局部块嵌入深度神经网络中,可以更有效地捕捉长距离依赖关系,同时将非局部信息和局部信息结合起来,可以更好地捕捉图像的全局理解。鉴于以上原因,我们将嵌入非局部块的ResNet-50作为整体框架的骨干网络,从而更直接且高效地获得对跨模态行人重识别图像的全局理解。
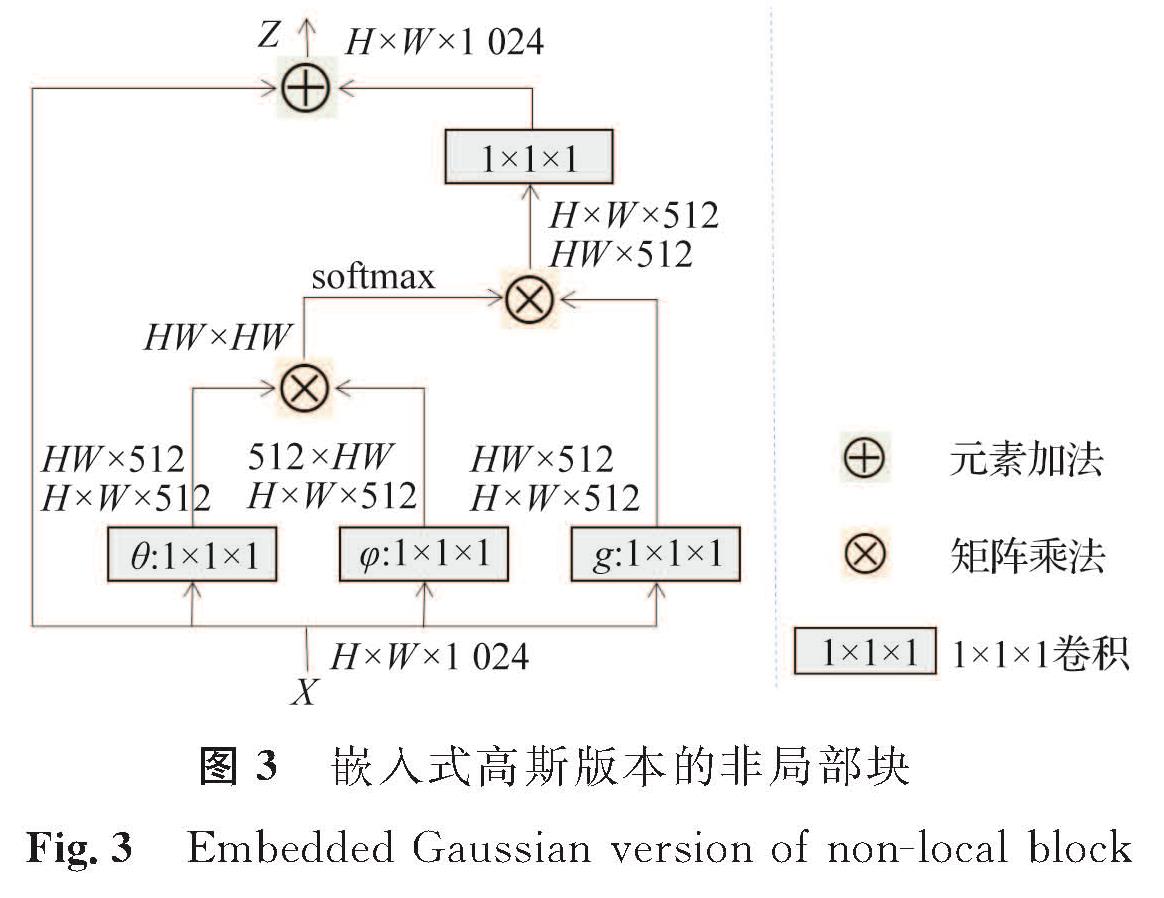
图3 嵌入式高斯版本的非局部块
Fig.3 Embedded Gaussian version of non-local block
2 试验结果及分析2.1 数据集
SYSU-MM01[6]是一个大型的跨模态行人重识别数据集,它包括来自4个可见光摄像机和2个红外摄像机所拍摄的491个不同行人的图像。训练集包括395人的19 659张RGB图像和12 792张IR图像,另外96人的图像用于测试。测试模式有全搜索模式和室内搜索模式两种。对于全搜索模式,使用所有摄像机拍摄的图像; 对于室内搜索模式,仅使用来自1、2、3、6摄像机的室内图像。两种模式下都分别采用单镜头和多镜头设置,其中单镜头设置是随机选择一个人的1张图像来形成训练集,而多镜头设置是随机选择一个人的10张图像来形成训练集。这两种模式都使用IR图像作为测试集,RGB图像作为训练集。
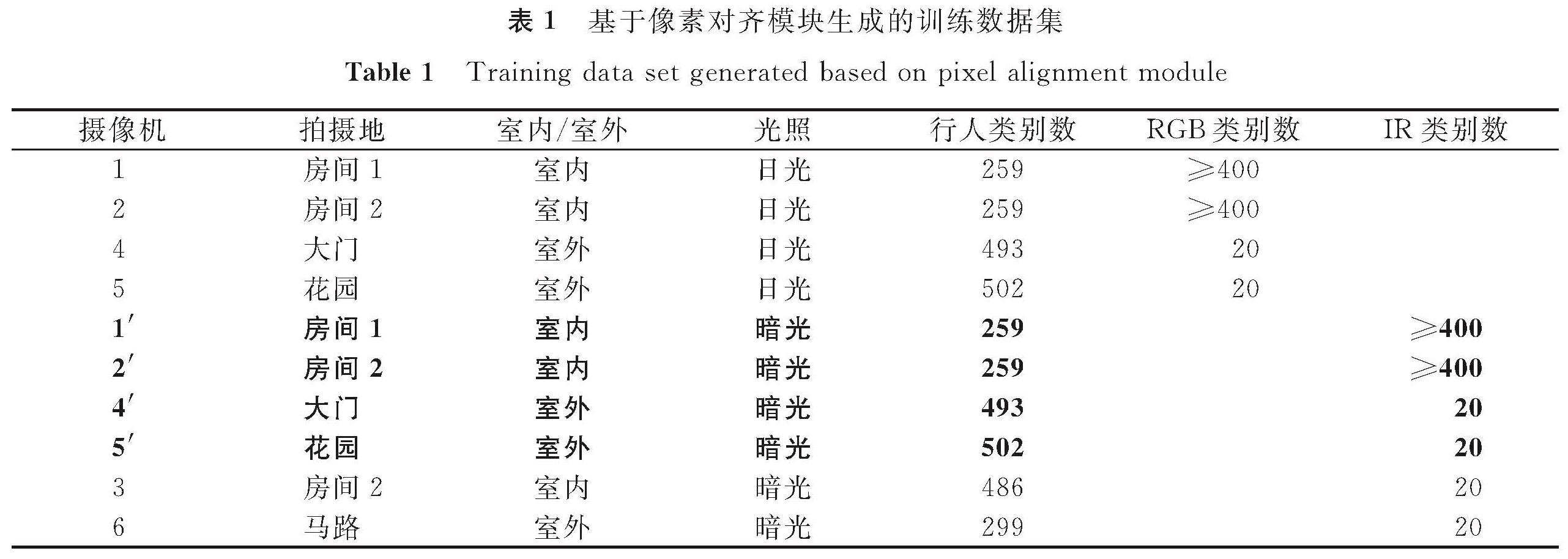
基于像素对齐模块生成的训练数据集见表1,训练所使用的数据集由两部分组成,包括通过AlignGAN将SYSU-MM01数据集中的1、2、4、5这四个可见光摄像机拍摄的RGB图像转换而成的IR图像(表1中字体加粗部分),以及SYSU-MM01数据集中的所有图像(表1中其他部分),其中1'、2'、4'、5'摄像机可理解为与1、2、4、5摄像机相对应的虚拟摄像机。为了公平比较,测试在大型公开数据集SYSU-MM01上进行。
表1 基于像素对齐模块生成的训练数据集
Table 1 Training data set generated based on pixel alignment module
2.2 评价标准
评价指标采用累计匹配特性(cumulative match characteristics,CMC)和均值平均精度(mean average precision,mAP)。CMC曲线,一般又称为排名(rank)曲线,它根据返回结果列表计算正确识别概率,但是它只适用于2个摄像头之间的识别; 而mAP适用于跨多个摄像头之间的识别任务,因此mAP的应用也越来越广泛。SYSU-MM01的结果用官方代码进行评估,该代码基于10次重复随机分割的训练和测试的平均值。
2.3 试验参数设置与实施细节在特征学习模块中,采用嵌入非局部块的ResNet-50作为CNN骨干,将网络的前两层作为集合级编码器,其余层作为实例级编码器。嵌入非局部块的方式是在ResNet-50中一个阶段的最后一个残差块之前添加的。在非局部块添加个数试验中我们做两种尝试,一种是添加5个非局部块到第3和第4阶段,其中2个非局部块在第3阶段,3个非局部块在第4阶段,方式为每隔一个残差块嵌入一个非局部块; 另一种是添加10个非局部块到第3和第4阶段,其中5个非局部块在第3阶段,5个非局部块在第4阶段,方式为每个残差块都添加。试验证明两种方式区别不大,为了减少计算量和参数量,我们选择了第一种嵌入方法。
本模型基于pytorch深度学习框架来实现。GAN的输入图像大小设置为[128,64],re-ID的输入图像大小设置为[256,128]。应用随机水平翻转进行数据增强。整个训练过程设置为650个迭代,GAN的PK采样参数设置为p=3和k=3,re-ID的PK采样参数设置为p=16和k=4。优化采用超参数为GAN的β=[0.5,0.999],权重衰减率为0.000 1,re-ID的β=[0.9,0.999],权重衰减率为0.000 5的Adam优化器。跨模态配对图像的生成模块中,学习率设置为0.000 1,特征对齐模块中,学习率设置为0.000 45。
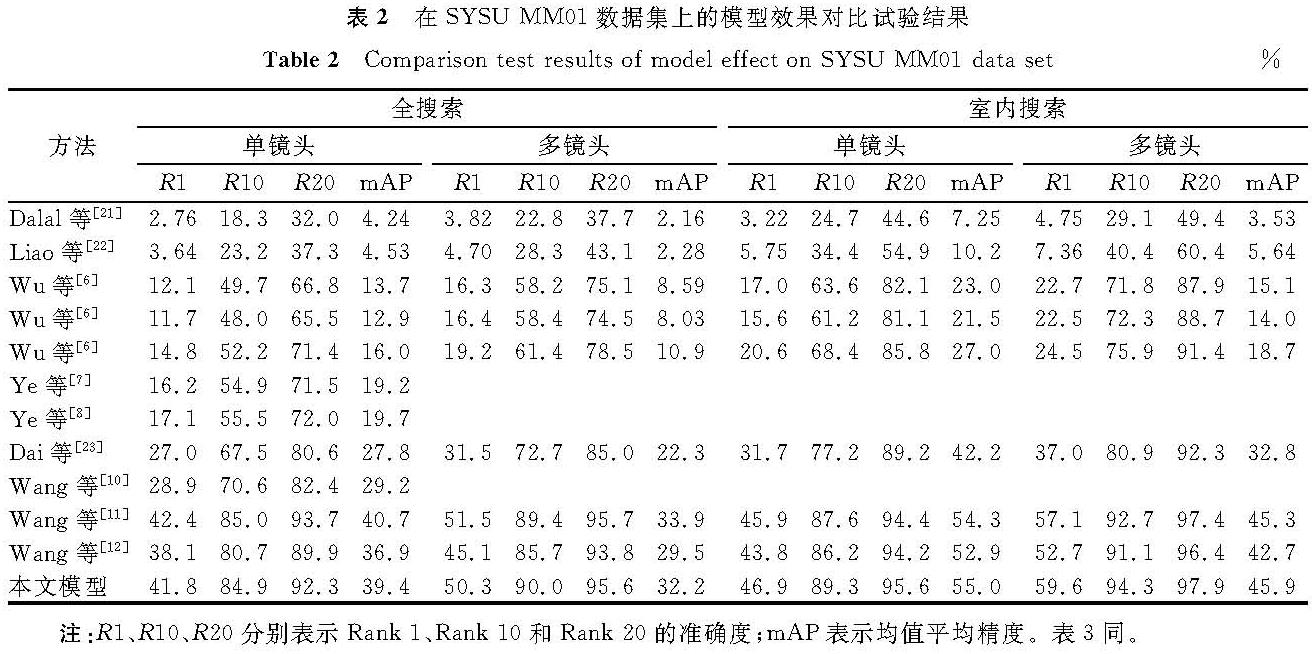
2.4 与同类方法的比较为了证明本方法的有效性,将其与大多数相关方法进行了比较,在SYSU-MM01数据集上的模型效果对比试验结果见表2,由表可知我们的方法明显优于现有大多数方法。在SYSU-MM01数据集上,本文方法的Rank-1为41.8%,mAP为39.4%,与Wang等[12]提出的模型相比,分别提高3.7%和2.5%。这证明了我们的方法对于跨模态行人重识别任务的有效性。
表2 在SYSU-MM01数据集上的模型效果对比试验结果
Table 2 Comparison test results of model effect on SYSU-MM01 data set %
2.5 模型分析
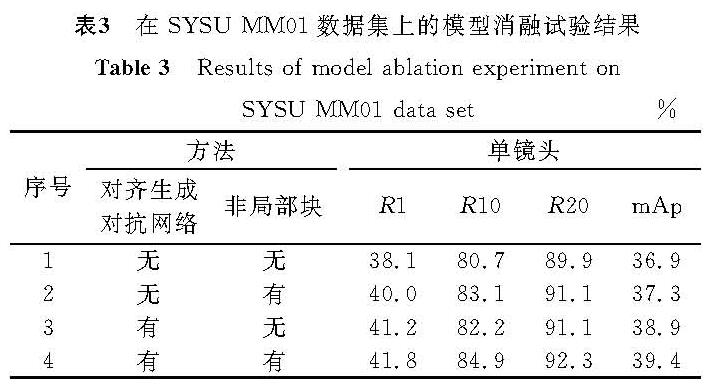
为了进一步分析本方法的有效性,我们进行了消融试验,结果见表3。试验结果表明在跨模态行人重识别的研究中,不论是通过AlignGAN对数据进行预处理,还是在ResNet-50中嵌入非局部块,都能取得很好的效果,而且二者结合效果更佳,这说明了本方法的有效性。
表3 在SYSU-MM01数据集上的模型消融试验结果
Table 3 Results of model ablation experiment on SYSU-MM01 data set %
2.6 图像可视化
为了更好地展示像素对齐和跨模态配对图像生成的效果,对其进行了可视化。图4为像素对齐和跨模态配对图像的生成效果图,从图中可以看到,通过像素对齐生成的假红外图像X'ir在具有红外风格的同时还保持了对应的真实RGB图像的模态不变特征(如视图、姿势等); 当给出来自一个人的跨模态未配对图像时,不论它是真实的RGB和IR图像,还是生成的假红外图像X'ir,我们的方法都可以稳定地生成相应跨模态配对图像。此外,除了在简单场景中的测试,我们还进行了复杂场景中的试验,都得到了相对较好的效果。例如,在跨模态配对图像生成试验中,当红外图像Xir和假红外图像X'ir分别生成可见光图像Xir2rgb和Xir'2rgb时,行人B和行人D就处在复杂的场景中(行人B面前有椅子,即遮挡; 行人D身后有台阶,即背景复杂),当可见光图像Xrgb生成红外图像Xrgb2ir时,行人B和行人C就处在复杂的场景中(行人B身边有汽车,即背景复杂; 行人C的身后有椅子和树木,即背景复杂)。
但是客观而论,生成的图像还不够清晰,有些部位很模糊,例如行人B在背景中有汽车的情况下生成的Xrgb2ir图像,腿部是非常模糊的,这可能是裤子与汽车轮胎颜色相近导致的识别不清和边界模糊。这也说明了在跨模态行人重识别领域的研究中,除了需要解决不同模态间较大的跨模态差异,传统行人重识别所面临的遮挡、视角变化、复杂背景等问题还亟待解决。

图4 像素对齐和跨模态配对图像的生成效果图
Fig.4 Generated renderings of pixel alignment and cross-modality paired images
3 结 语
可见光-红外跨模态行人重识别因具有很强的现实意义,近年来得到了广泛的关注和研究,然而,如何减少不同模态间巨大的跨模态差异较为困难。本研究针对这个难题提出了一种联合像素对齐和特征对齐的方法,本方法不仅能有效减少跨模态差异,还可以同时执行集合级对齐和实例级对齐。除此之外,嵌入非局部块的ResNet-50网络在跨模态行人重识别的研究中,也取得了一定的突破。在SYSU-MM01数据集上得到了Rank-1为41.8%,mAP为39.4%的结果,实现了Rank-1上提升3.7%和mAP上提升2.5%的目标,试验结果证明了本方法的有效性。
- [1] GONG S, CRISTANI M, YAN S, et al. Personre-identification[J].Advances in Computer Vision & Pattern Recognition,2014,42(7):301.
- [2] LI W, ZHU X, GONG S. Harmonious attention network for person re-identification[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2018:2285.
- [3] WANG Z, HU R, CHEN C, et al. Person reidentification via discrepancy matrix and matrix metric[J].IEEE Transactions on Cybernetics,2018,48(10):3006.
- [4] WEI L, ZHANG S, GAO W, et al. Person transfer GAN to bridge domain gap for person reidentification[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2018:79.
- [5] 陈丹,李永忠,于沛泽,等.跨模态行人重识别研究与展望[J].计算机系统应用,2020,29(10):20.
- [6] WU A, ZHENG W S, YU H X, et al. Rgb-infrared cross-modality person re-identification[C]//IEEE International Conference on Computer Vision. Piscataway:IEEE,2017:5390.
- [7] YE M, LAN X, LI J, et al. Hierarchical discriminative learning for visible thermal person re-identification[C]//AAAI Conference on Artificial Intelligence. Palo Alto:AAAI,2018:7501.
- [8] YE M, WANG Z, LAN X, et al. Visible thermal person re-identification via dual-constrained Top-ranking[C]//International Joint Conference on Artificial Intelligence. San Francisco:Morgan Kaufmann,2018:1092.
- [9] 冯敏,张智成,吕进,等.基于生成对抗网络的跨模态行人重识别研究[J].现代信息科技,2020,4(4):107.
- [10] WANG Z, WANG Z, ZHENG Y, et al. Learning to reduce dual-level discrepancy for infrared-visible person reidentification[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2019:618.
- [11] WANG G, ZHANG T, CHENG J, et al. Rgb-infrared cross-modality person re-identification via joint pixel and feature alignment[C]//IEEE International Conference on Computer Vision. Piscataway:IEEE,2019:3623.
- [12] WANG G, YANG Y, ZHANG T, et al. Cross-modality paired-images generation and augmentation for RGB-infrared person re-identification[J].Neural Networks,2020,128:294.
- [13] WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2018:1.
- [14] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generativeadversarial nets[C]//Advances in Neural Information Processing Systems(NIPS). Massachusetts:MIT Press,2014:2672.
- [15] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//2017 IEEE International Conference on Computer Vision. Piscataway:IEEE,2017:2242.
- [16] ZHENG L, YANG Y, HAUPTMANN A G. Person re-identification:past, present and future[EB/OL].(2016-10-10)[2021-05-10].https://arxiv.org/abs/1610.02984.
- [17] HERMANS A, BEYER L, LEIBE B. In defense of the triplet loss for person re-identification[EB/OL].(2017-03-22)[2021-05-10].https://arxiv.org/abs/1703.07737.
- [18] KRHENBÜHL P, KOLTUN V. Efficient inference in fully connected crfs with gaussian edge potentials[J].Neural Information Processing Systems(NIPS). Massachusetts:MIT Press,2011:2.
- [19] BUADES A, COLL B, MOREL J M. A non-local algorithm for image denoising[C]//IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2005:1.
- [20] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//IEEE International Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2016:770.
- [21] DALAL N, RIGGS B. Histograms of oriented gradients for human detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2005:886.
- [22] LIAO S, HU Y, ZHU X, et al. Person reidentification by local maximal occurrence representation and metric learning[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2015:2197.
- [23] DAI P, JI R, WANG H, et al. Cross-modality person re-identification with generative adversarial training[C]//International Joint Conference on Artificial Intelligence. San Francisco:Morgan Kaufmann,2018:677.