 图 1 图 注意力机制模型
Fig.1 Graph attention mechanism model
图 1 图 注意力机制模型
Fig.1 Graph attention mechanism model
SHAO Ai,XU Caie,WAN Jian,et al.Deep learning network model for multi-hop problems in question answering[J].Journal of Zhejiang University of Science and Technology,2022,(05):419-425.[doi:10.3969/j.issn.1671-8798.2022.05.005]

自然语言处理是人工智能的重要分支,自动问答系统为评估自然语言处理能力提供了一种可以量化的客观方法,可以用来测试人工智能系统的推理能力[1-2],这正逐渐成为一种人与机器进行自然交互的新趋势。问答系统能够更准确地理解以自然语言描述的用户问题,并依据用户的真实意图返回给用户更精准的答案,它将成为下一代搜索引擎的新形态。近年来,深度学习模型的发展使得机器问答取得了长足的进步,针对机器问答的深度学习模型层出不穷,机器问答的研究进入了一个全新的阶段。然而当前大多数问答工作都集中在从单一段落中寻找问题和答案[3-4],很少测试底层模型的深层推理能力,且单段问答模型在与问题匹配的句子中寻找答案,不涉及复杂的推理,因此多跳问答模型成为下一个需要攻克的前沿课题。近年来研究者们提出了一些专门用于评估问答模型多跳推理能力的数据集,如WikiHop[5]、ComplexWebQuestions[6]和HotpotQA[7]等。在此基础之上,越来越多的研究者根据多个句子或段落中的实体之间的共现关系来构建图网络结构。Song等[8]设计了一个DAG(database availability group,数据实体组)样式的递归层来对实体之间的关系进行建模,有效提升了实体级信息传递能力。Dhingra等[9]使用GCN(graph convolutional network,图神经网络)处理实体图,将神经网络[10]引入图中实体后极大提升了节点间的信息互联。Xiao等[11]提出了一种基于GFN(dynamic fusion entity graph,动态实体图)的多跳问答模型,通过实体信息动态传递的方式进行问答的推理和预测,提升了问答的准确率。Tu等[12]通过引入文档节点和查询节点将实体图扩展为异构图,提升了图中节点信息查询的速度,为图神经网络提供了新模式。但是这些基于深度学习神经网络模型的问答系统在进行文本的特征提取时无法保证其质量,同时在推理计算相似度层面的运算能力不足,所以在面对复杂问句及长难问句时仍然存在问句解析难度大,实体级别模型推理能力弱,问答匹配准确率较低等问题。
基于上述研究,本研究提出了AGTNet(albert graph attention network,轻量双向编码图注意力网络)模型,本模型包含了表征提取、推理计算、结果预测3个模块。模型在表征抽取层的神经网络隐藏部分使用参数共享和矩阵分解技术来降低模型的空间复杂度,同时使用点积计算方式的图注意力机制进行答案预测,从而提升了字词级别的表征提取质量,提高了模型实体级推理能力和问答匹配的准确率。
1 神经网络注意力机制算法1.1 预训练模型BERT(bidirectional encoder representation from transformers,双向表示编码器)是谷歌团队于2018年发布的预训练模型,在实际应用中往往受到硬件内存的限制,而增加模型的隐藏层大小也会导致性能下降。2019年ALBERT(a lite bidirectional encoder representation from transformers,轻量双向表示编码器)预训练模型的发布改善了BERT参数大、资源消耗多的缺点。BERT的隐藏层单元数为2 048,相比ALBERT翻了一倍; 然而,该模型在RACE(reading comprehension dataset collected from english examinations,英语测验阅读理解数据集)上的准确率却较低,而ALBERT不但参数量比BERT少得多,而且准确率与BERT相比较高,达到70.2%。
1.2 图神经网络
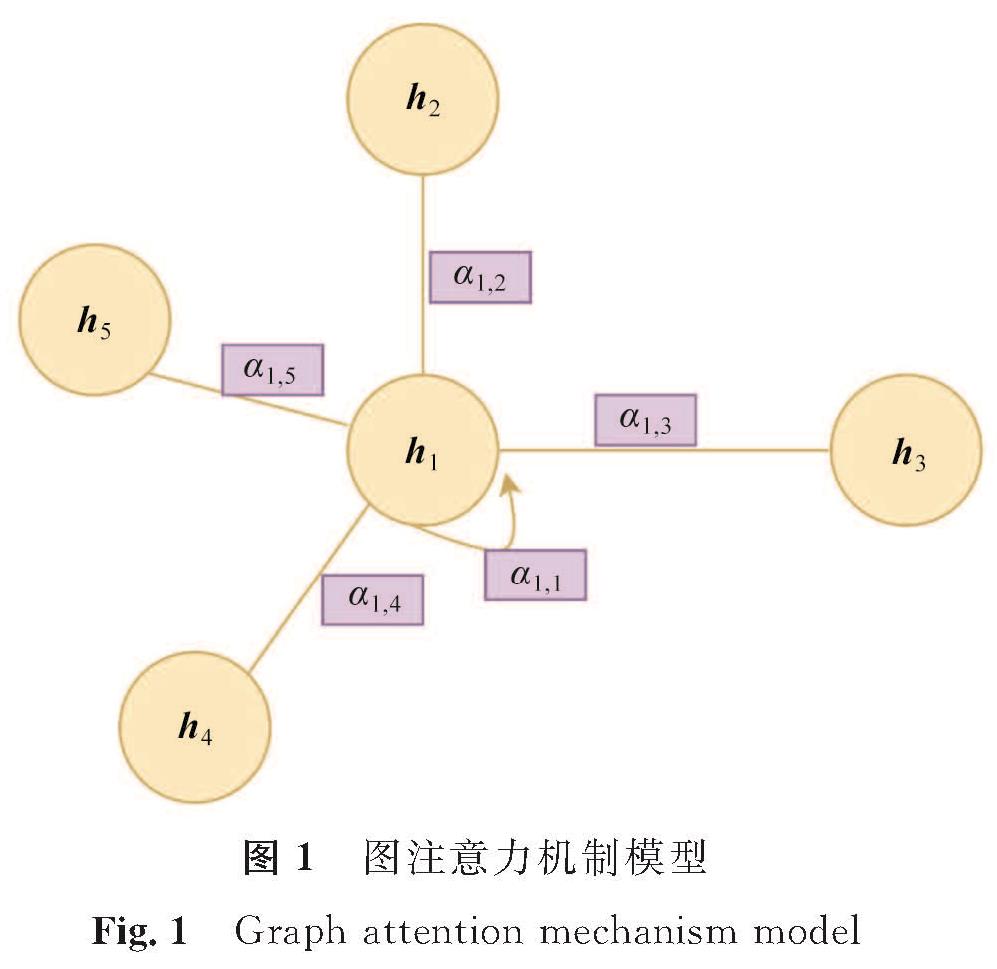
图1 图注意力机制模型
Fig.1 Graph attention mechanism model
图神经网络是神经网络的一个分支,最早于2005年被提出。其基本思路是,图中节点的性质由其自身的属性和邻居节点的属性共同决定[13],网络为图中每个节点分配向量h,该向量包含了自身节点和邻节点的信息,可以用于节点预测、图分类等任务。GAT(graph attention networks,图注意力机制网络)[14]在图神经网络中引入注意力机制[15],赋予邻节点不同的重要性。图注意力机制模型如图1所示,点h1为研究对象,把节点自身也视为一阶邻居,根据节点的特征向量h1计算节点词向量权重α。在更新节点的特征向量时,根据权重对邻居信息进行聚合,得到包含邻居信息的节点向量[16]。
1.3 点积注意力机制注意力机制模型为了获得足够的表达能力,需要采用线性转换来提升输入特征的维度[17],为此,模型使用权重矩阵W对每个节点进行线性变换,然后在每个节点上计算注意力机制权重系数。hi和hj为点积注意力机制节点的实体向量,采用点积算法计算节点中词向量的权重α,通过激活函数σ计算实体节点间的注意力权重β。点积注意力机制在点积算法的基础上进一步融合了注意力权重,并且对注意力权重的计算采用了相同数学表达式[18]。
2 模型结构详细设计本研究提出的AGTNet模型结构如图2所示,模型包括表征提取和推理计算模块。[P1,P2,…,Pn]与[Q1,Q2,…,Qn]为输入的问题和段落向量,[E1,E2,…,En]与[T1,T2,…,Tn]为表征提取后的特征向量,W为权重矩阵,[R1,R2,…,Rn]为图中节点。本模型在表征抽取模块的神经网络隐藏部分使用参数共享和矩阵分解技术,有效降低了模型的空间复杂度; 同时使用点积计算方式的图注意力机制进行答案预测,有效提升了模型问答推理能力和问答准确率,解决了用户问句理解难、模型推理预测计算能力不足等问题。
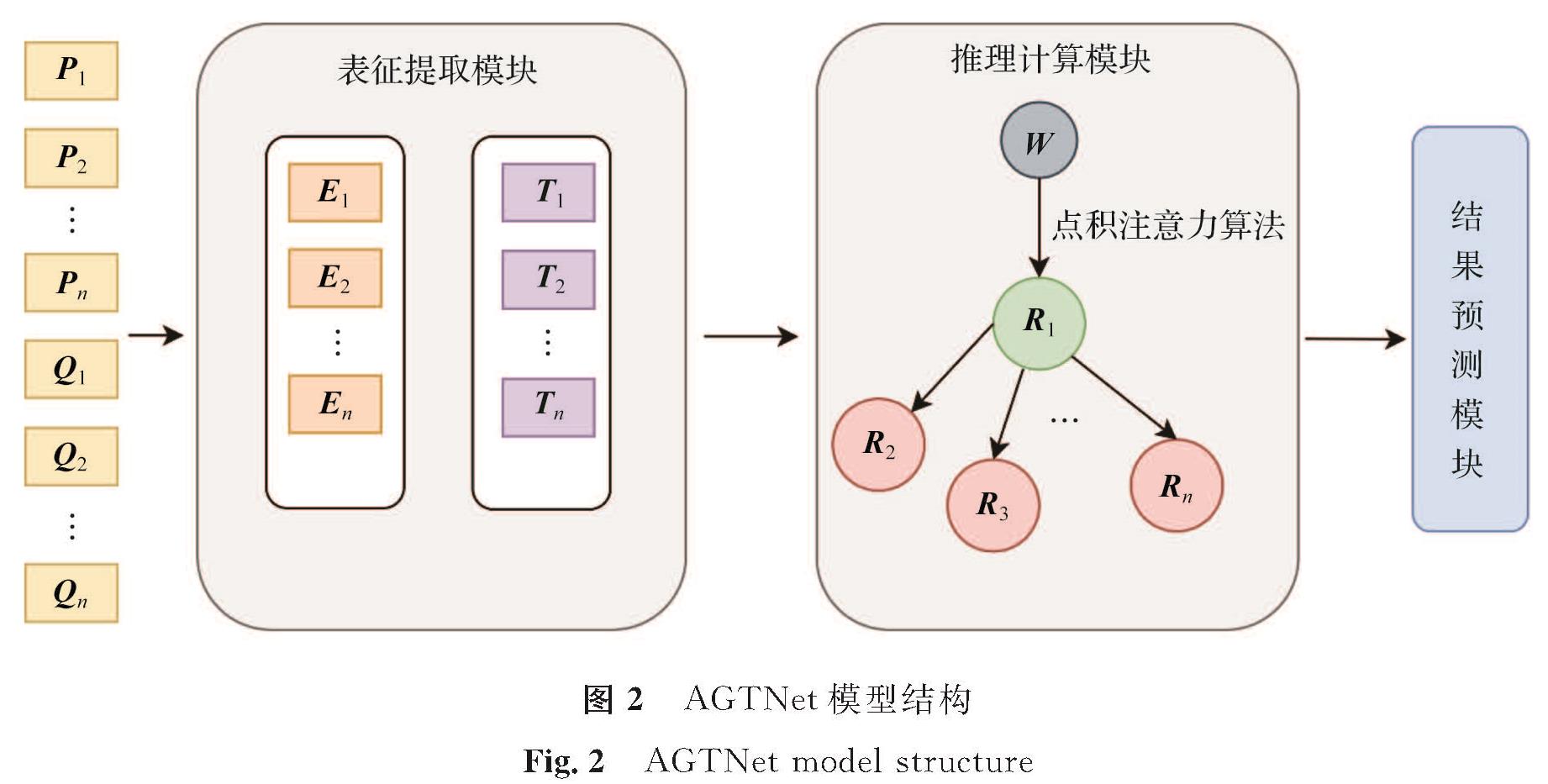
图2 AGTNet模型结构
Fig.2 AGTNet model structure
2.1 表征提取模块
本研究的表征提取模块采用了ALBERT模型[19],将问答语料输入模型,输出对应问题Q和段落的词向量P,以及从中提取出的语义向量s。表征提取流程如图3所示,首先将问题[Q1,Q2,…,Qn]与段落[P1,P2,…,Pn]打包成一个序列共同输入; 其次ALBERT通过词嵌入方式生成表征向量[E1,E2,…,En]; 最后将表征向量输入编码层,输出编码向量[T1,T2,…,Tn],从编码层随之输出的还有语义向量s。
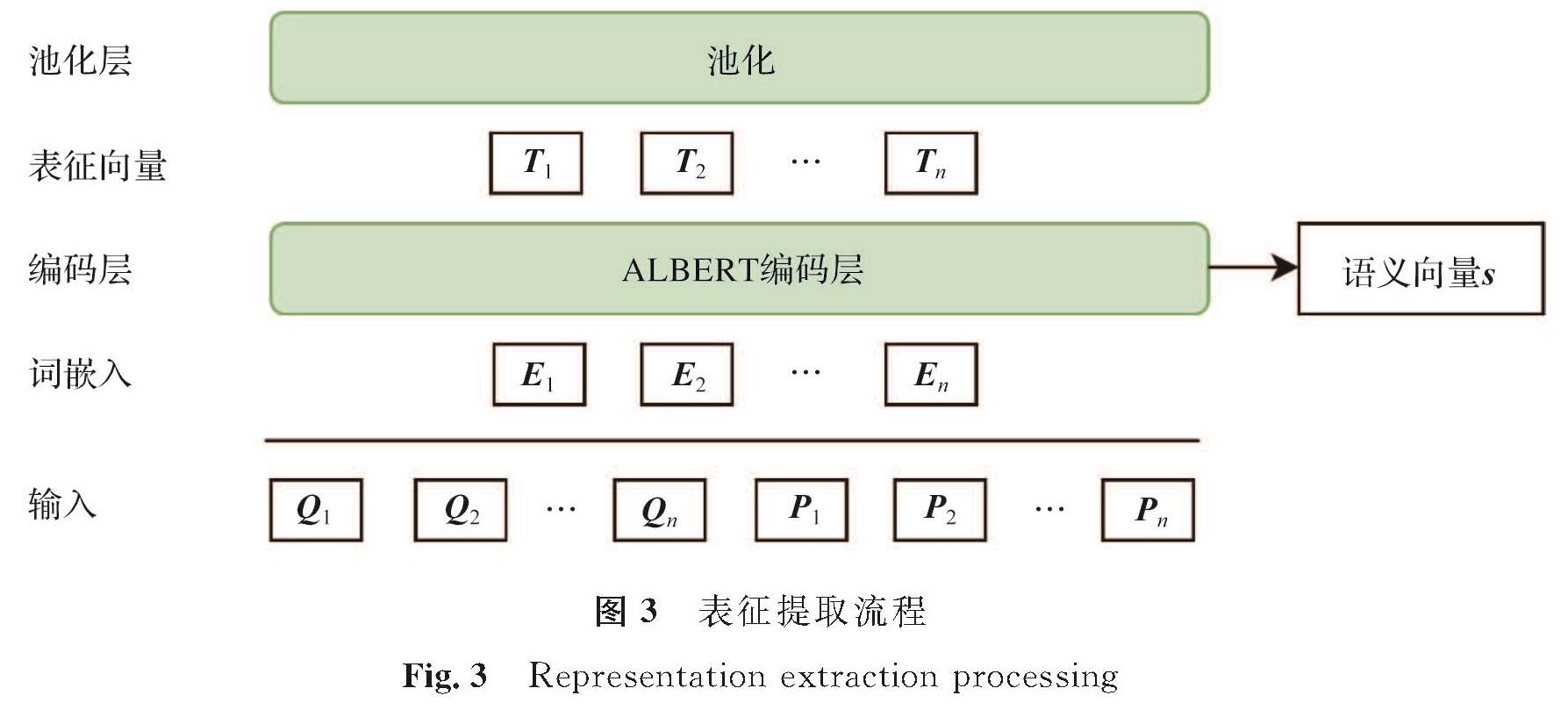
图3 表征提取流程
Fig.3 Representation extraction processing
2.2 推理计算模块2.2.1 实体计算

图4 实体间注意力权重计算过程
Fig.4 Process of calculating attention weights among entities
推理计算模块实体间注意力权重计算过程如图4所示,用点积注意力机制来模仿人类逻辑探索和推理过程。R'1为融合邻节点信息后的实体。
将图中的节点信息传播到每个邻节点进行融合。在每个推理步骤中,假设每个节点都有信息要传播到它的邻节点,与问题和段落相关性越大的邻节点从附近接收的信息越多。通过在实体上关联问题来查询相关的节点,把问题表示和实体表示相结合,再乘以抽取出的语义向量,计算得出融合邻节点信息后的实体
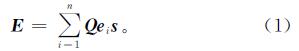
式(1)中:Q为问题向量; ei为第i个词向量; s为语义向量。
2.2.2 推理过程通过以下方法计算两个实体之间的注意力权重:

其中
α=(WE)TWE。(3)
本研究使用的点积图注意力算法与传统GAT的不同之处在于每个节点对其邻节点加权求和,从而形成一个新的实体节点状态
E'=ReLU(βE)。(4)
式(4)中:ReLU为激活函数,用来计算新的实体节点E'的状态信息。
2.3 结果预测模块2.3.1 图转表征本研究设计了图转表征功能来将实体转化为向量。模块将文本向量C与关联实体向量串联,二进制矩阵M中的每行对应一个向量,从E'中选择一个实体嵌入,使用LSTM(long-short-term memory network,长短期记忆网络)[20]进一步处理该信息,以产生下一级上下文向量C',并且将C'作为下一个网络的输入。
C'=L(C,ME')。(5)
式(5)中:C'为下一级的上下文向量; L为长短期记忆网络函数; C为文本向量; M为二进制矩阵。
2.3.2 预测器本研究使用的预测器采取级联结构来解决输出依赖,其中3个同构的LSTM逐层堆叠,预测器有3个输出维度,包括答案的开始位置、答案的结束位置及答案的类型。将下一级上下文文本向量C'输入预测器,每个预测器输出一个对数,并在这些对数上计算出交叉熵损失,这些交叉熵损失在预测器中都进行了优化,每个损失项都有对应的系数加权。预测器输出的损失函数如下:
Ostart=F0(C');(6)
Oend=F1(C',Ostart);(7)
Otype=F2(C',Ostart,Oend)。(8)
式(6)~(8)中:F0、F1、F2分别为预测器函数; Ostart、Oend、Otype分别为答案开始位置、结束位置、类型的对数。
预测器输出损失函数后将进行损失值的计算,计算过程如下:
L=Lstart+λLend+λLtype。(9)
式(9)中:λ为相应损失的系数矩阵; Lstart、Lend、Ltype分别为答案开始位置、结束位置、类型的损失值。
3 试验设计与结果分析3.1 数据集本研究使用HotpotQA数据集[7]进行试验,数据集由11.3万个人工设计的问题组成,分为干扰项和完整项。在干扰项中84%的问题需要多跳推理,这些数据被分成训练集、验证集和测试集。本研究分别在HotpotQA数据集的干扰项和完整项设置下进行了试验。
3.2 试验细节表征提取模块使用了ALBERT预训练模型。在图的构建阶段,使用斯坦福大学预训练的NER(named entity recognition,命名实体识别)模型[21]来提取命名实体,图中实体的最大数量被设定为40,实体图中每个实体节点的平均度为3.52; 在推理阶段,图注意力模型中每个节点都融合了其余节点的信息。
3.3 试验结果不同模型在HotpotQA测试集干扰项设置下的试验结果见表1,试验评估指标为EM(expectation maximum,最大期望)值及综合指标F1值。本研究提出的AGTNet模型的EM值达到45.53,F1值达到65.25,与其他对比模型相比,AGTNet在HotpotQA测试集干扰项设置下取得了较优的结果。
不同模型在HotpotQA测试集完整项设置下的试验结果见表2。AGTNet模型在每个指标上的表现均优于其他模型,EM值达到69.66,F1值达到81.15。QFE(query-focused extractor,聚焦查询器)[8]、DFGN(dynamically fused graph network,动态融合图网络)[11]等基于深度学习的模型在进行文本特征提取时无法保证其质量,同时在相似度计算层面的运算能力不足,所以在面对复杂问句时仍然存在问句解析难度大、模型推理能力弱等问题,AGTNet针对这些问题,使用参数共享、矩阵分解技术及点积注意力算法,与其他对比模型相比,AGTNet在HotpotQA测试集完整项设置下取得了较优的结果。
表1 不同模型在HotpotQA测试集干扰项设置下的试验结果
Table 1 Experimental results of different models indistractor items of the HotpotQA test set
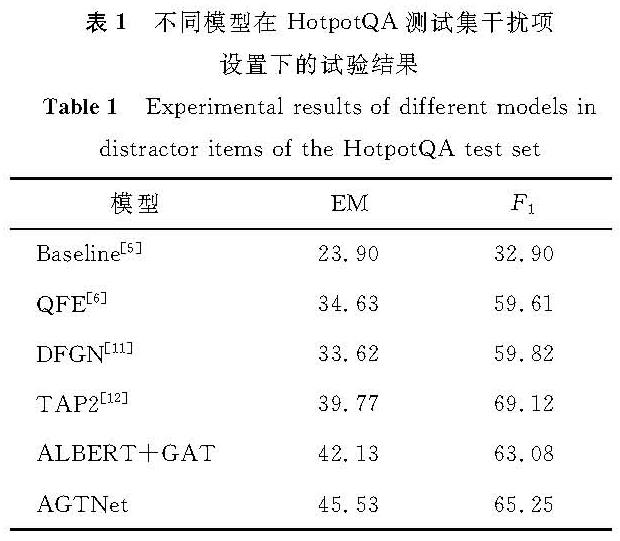
表2 不同模型在HotpotQA测试集完整项设置下的试验结果
Table 2 Experimental results of different models in complete items of the HotpotQA test set

3.3.1 评估依据
为了评估问答系统的逻辑严谨性,本研究使用联合答案/正确答案,即正确答案中联合答案的比例来评估AGTNet的有效性。联合答案指那些从支持性事实中推导出来的答案,因此,这个比例代表了推理的逻辑严谨性。本研究的联合答案/正确答案比例达到59.4%,超过文献[5]的10.9%和QFE的34.6%。
3.3.2 结果分析本研究提出的AGTNet模型在EM值及F1值上都超过比较的其他模型。由于多跳问答的难点在于问题与段落在字面上只有很少的共同词汇,甚至与问题没有语义关系,因此,传统的检索提取模型很难找到问题与段落之间的关联。然而,本研究提出的模型AGTNet会根据线索逐渐发现相关实体。
4 结 语本研究提出了一个新模型来解决大规模的多跳问答问题。模型的表征抽取模块使用ALBERT做实体抽取,推理计算模块使用了结合语义向量的点积图注意力机制算法,从而达到较优的实体级推理水平。本研究提出的AGTNet模型在HotpotQA数据集上进行训练,取得了良好的训练结果,表明了AGTNet的有效性。但是在应对复杂问句和深层推理时,AGTNet的计算逻辑性还有待提高,根据图注意力机制的特性,后续的研究中可以通过加入逻辑性变量来提高可靠性。此外,通过优化系统之间的交互,结合微调和基于特征的表征抽取将提高ALBERT的容量。
- [1] 王瑛,何启涛.智能问答系统研究[J].电子技术与软件工程,2019(5):174.
- [2] RAIPURKAR P, ZHANG J, LOPYREY K, et al. SQuAD:100,000+ questions for machine comprehension of text[J].Advances in Neural Information Processing Systems,2017,1(8):5999.
- [3] SEO M, KEMBHAVI A, FARHADI A, et al. Bidirectional attention flow for machine comprehension[J].High Technology Letters,2017,23(2):179.
- [4] 姚智.基于深度学习的医疗问答系统的开发[J].中国医疗设备,2019,34(12):88.
- [5] WELBL J, STENETORP P, RIEDEL S. Constructing datasets for multi-hop reading comprehension across documents[J].Transactions of the Association for Computational Linguistics,2018,6(8):287.
- [6] TALMOR A, BERANT J. The web as a knowledge-base for answering complex questions[C]//Proceedings of the conference of 2018 the North American Chapter of the Association for Computational Linguistics. San Francisco:Margan Kaufmann,2018:269.
- [7] YANG Z, QI P, ZHANG S, et al. Hotpotqa:a dataset for diverse, explainable multi-hop question answering[J].Semantic Scholar,2016,2(4):4.
- [8] SONG L, WANG Z, YU M, et al. Exploringgraph-structured passage representation for multi-hop reading comprehension with graph neural networks[J].Communications of the ACM,2020,63(11):139.
- [9] DHINGRA B, JIN Q, YANG Z, et al. Neural models for reasoning over multiple mentions using coreference[J].International Journal of Computational Intelligence Systems,2020,28(12):2704.
- [10] KIP F, WELLING M. Semi-supervised classification with graph convolutional networks[J].Computer Science,2015,9(13):4.
- [11] QIU L, XIAO Y, QU Y, et al. Dynamically fused graph network for multi-hop reasoning[C]//2019 Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Boston:Kluwer,2019:58.
- [12] TU M, WANG G, HUANG J, et al. Multi-hop reading comprehension across multiple documents by reasoning over heterogeneous graphs[C]//NAACL HLT 2019 Conference of the North American Chapter of the Association for Computational Linguistics. Washington:IEEE Computer Society,2019:13.
- [13] SCARSELLI F, GORI M, TSOI A C, et al. The graph neural network model[J].IEEE Transactions on Neural Networks,2009,20(1):61.
- [14] VELIKOVI P, CUCURULL G, CASANOVA A, et al. Graph attention networks[C]//52nd Annual Meeting of the Association for Computational Linguistics. Piscataway:IEEE,2017:125.
- [15] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//2017 Advances in neural information processing systems. New York:IEEE Communications Society,2017:257.
- [16] LUONG M T, PHAM H, MANNING C D. Effective approaches to attention-based neural machine translation[C]//5th International Conference on Learning Representations ICLR 2017 Conference Track Proceedings. Columbus:McGraw-Hill,2017:48.
- [17] 陈雨龙,付乾坤,张岳.图神经网络在自然语言处理中的应用[J].中文信息学报,2021,35(3):1.
- [18] KIPF T N, WELLING M. Variational graph auto-encoders[J].Computer Science,2014,7(11):5.
- [19] LAN Z, CHEN M, GOODMAN S, et al. ALBERT:a lite bert for self-supervised learning of language representations[C]//Proceedings of the IEEE International Conference on Computer Vision. New York:IEEE,2020:166.
- [20] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J].Neural computation,1997,9(8):1735.
- [21] MANNING C D, SURDEANU M, BAUER J, et al. The stanford corenlp natural language processing toolkit[C]//Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics. New York:IEEE,2014:98.