 图 1 对抗源样本与非对抗源样本的LD分布
Fig.1 LD distribution of adversarial source examples and non-adversarial source examples
图 1 对抗源样本与非对抗源样本的LD分布
Fig.1 LD distribution of adversarial source examples and non-adversarial source examples
SHAO Qiqi,QIAN Yaguan,WANG Jiamin,et al.Virtual adversarial learning based on latent space of convolutional neural network[J].Journal of Zhejiang University of Science and Technology,2022,(05):426-434.[doi:10.3969/j.issn.1671-8798.2022.05.006]

深度学习在图像识别[1]、语音识别[2]、自然语言处理[3]等领域取得了成功的应用,但是近几年的研究发现,深度神经网络(deep neural network,DNN)很容易受到对抗样本的攻击。对抗样本就是在干净样本上添加微小的扰动,从而导致DNN分类错误,例如在“停止”的交通标志上添加微小的扰动,就能使自动驾驶汽车辨别为“加速”等其他交通标志,从而造成重大交通事故。自Szegedy等[4]发现对抗样本的存在后,后续研究者提出了很多对抗样本的生成方法,如快速梯度符号法(fast gradient sign method,FGSM)[5]、聚焦图像的无目标攻击[6]、基于生成对抗网络合成对抗样本[7]、补丁攻击[8]等,对对抗样本产生的原因也进行了探索[4-5],但由于DNN难以解释的特性,目前仍然没有完全了解对抗样本的产生机理。与此同时,相应的防御方法也被广泛研究。许笑等[9]提出了冗余信息压缩方案以消除附加扰动,有效地防御对抗攻击。范宇豪等[10]根据插值算法能够在图像缩小和放大过程中较好地保留图片信息这一特性,提出基于插值法的对抗防御算法。目前对抗训练被认为是极有效的防御方法,它利用对抗样本来训练模型,不同的对抗样本生成方法构成不同的对抗训练方法。
FGSM对抗训练是对抗训练的早期形式,随后更为有效的对抗训练一直在探究中。Madry等[11]提出投影梯度下降(projected gradient descent,PGD)对抗训练并将其表示为最小最大的鞍点优化问题,其内部最大问题是寻找攻击最强的对抗样本,外部最小问题是在最强对抗样本的干扰下,获得损失最小的DNN。该方法至今仍然保持着较好鲁棒性。现有研究表明,对抗训练的计算复杂度非常高,其中生成对抗样本占了总耗时的主要部分[12]。Zhang等[13]认为,当执行多步PGD攻击时,在反向传播计算对抗样本期间可以减少冗余的计算来获得额外的加速。Shafahi等[12]提出了自由对抗训练(简称Free),通过使用单次反向传播同时更新模型权重和输入扰动,以提高对抗训练的效率。在此基础上,Zhu等[14]提出大批次自由对抗训练(简称FreeLB),与Free不同的是,FreeLB在内部损失最大化的k步过程中没有更新模型参数,而是利用k步之后积累的梯度求平均,再对模型参数进行更新,该方法进一步增强了模型的鲁棒性。Wong等[15]提出了Fast(快速)对抗训练,利用先前的小批量扰动或从均匀随机扰动中初始化一个扰动添加到干净样本上,并使用比扰动约束更大的步长,加上循环学习率和混合精度计算等技术,使得Fast对抗训练在增强模型鲁棒性的同时实现加速。
上述对抗训练方法需要在输入空间生成真实的对抗样本,再用对抗样本进行训练。然而,生成对抗样本的过程需要更新对抗扰动,这需要通过反向传播计算损失对样本的梯度来实现,因此占用了大量训练时间。此外,对抗样本训练会影响模型对干净样本的预测精度。针对这些问题,我们提出一种虚拟对抗学习方法,也称之为虚拟对抗训练,将寻找输入空间中的扰动来生成对抗样本的问题,转化为寻找隐空间中的扰动来生成虚拟对抗样本的问题,从而有效地避免计算损失对样本的梯度,大幅提高对抗训练的速度,同时引入阈值机制来保证训练后的模型对干净样本的预测精度影响较小。
1 基本符号和定义在本研究中,定义训练数据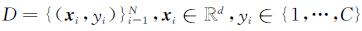 ,yi为xi的类标签。Fθ(x)表示一个参数为θ的预训练神经网络模型,Fθ(x)=F(N)(…(F(2)(F(1)(x))))。分类器Fθ(x)的最后一层为softmax层,输出概率向量P=(p1,p2,…,pC),样本被判别为第j类的置信度pj可表示为
,yi为xi的类标签。Fθ(x)表示一个参数为θ的预训练神经网络模型,Fθ(x)=F(N)(…(F(2)(F(1)(x))))。分类器Fθ(x)的最后一层为softmax层,输出概率向量P=(p1,p2,…,pC),样本被判别为第j类的置信度pj可表示为
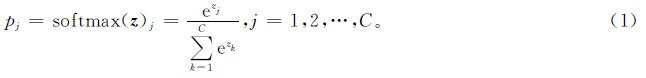
式(1)中:向量z=(z1,z2,…,zC)为分类器Fθ(x)的倒数第二层的输出logits。记(^overy)=argmaxj{pj}是样本x的预测分类标签。
定义1 对抗样本:对于干净样本x,它的正确类标签为y。如果存在扰动δ,||δ||=2<ε,ε为扰动大小约束,使得x'=x+δ满足argmaxjFθ(x')≠y,那么称x'为对抗样本。
由于对抗扰动δ受到约束,并不是任何一个干净样本都能获得对应的对抗样本。为了更好地阐述相关方法,定义了对抗源样本的概念。
定义2 对抗源样本:对于干净样本x,它的正确类标签为y。假设G为某个对抗样本生成算法,满足Fθ(G(x))≠y,那么该样本称为当前模型Fθ下G算法的对抗源样本。
定义3 虚拟对抗样本:干净样本x通过网络倒数第二层的输出logits为z,在logits上添加扰动Δ,即z'=z+Δ,如果在输入空间存在一个对应的对抗样本x',满足Fθ(x')=softmax(z'),那么把这样的x'称为虚拟对抗样本。
2 虚拟对抗学习的实现2.1 问题的描述传统的对抗训练需要在输入空间寻找一个最小扰动δ生成对抗样本x'=x+δ,再用对抗样本来训练分类器,而本研究在特征空间寻找一个最小的扰动Δ生成虚拟对抗样本进行训练。假定干净样本x的真实标签y与预测标签(^overy)一致,y=(^overy),虚拟对抗样本x'的softmax输出为P'=(p'1,p'2,…,p'C),样本被判别为第j类的置信度p'j可表示为
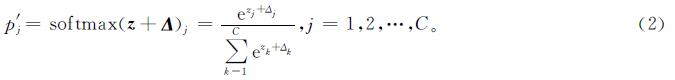
式(2)中:扰动Δ=(Δ1,Δ2,…,ΔC),为与z同维度的向量。记y'=argmaxj{p'j}为虚拟对抗样本的输出标签。由对抗样本的定义可知:y'≠y∩y'≠(^overy),即有y≠argmaxj{p'j}。因此,argmaxjFθ(x')≠y等价于softmax(z+Δ)y<max{softmax(z+Δ)j|1≤j≤C∩j≠y}。由于softmax函数是一个单调递增函数,上述不等式又等价于zy+Δy<max{zj+Δj|1≤j≤C∩j≠y}。因此,可以把生成虚拟对抗样本的过程表示为如下的优化问题:
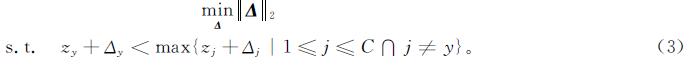
把上述虚拟对抗样本的生成和对抗训练结合在一起,就是本研究提出的虚拟对抗学习。
2.2 阈值机制的建立传统的对抗训练只用对抗样本训练模型,虽然能提高模型的鲁棒性,但也会严重降低对干净样本的预测精度。同样地,为了更好地保证虚拟对抗训练的分类效果,需要给定一些约束条件来选择,让一些干净样本生成虚拟对抗样本来参加训练。根据1.1节中对抗源样本的定义,可以认为对抗源样本是容易生成对抗样本的干净样本,因此,本研究选择在对抗源样本上添加扰动Δ使其生成虚拟对抗样本。
记样本的logits中的第二大值为zs,最大值与第二大值之差(logits distance,LD)为zy-zs。通过FGSM攻击获得了CIFAR-10和ImageNet(30)数据集上对抗源样本的LD和非对抗源样本的LD,观察到二者LD分布近似服从正态分布,如图1所示。显然,对抗源样本的LD均值(mean of logits distance,MLD)小于非对抗源样本的MLD,利用这种差异性建立阈值机制,设定阈值γ,把LD<γ作为约束条件来挑选对抗源样本,就能获得大量对抗源样本。
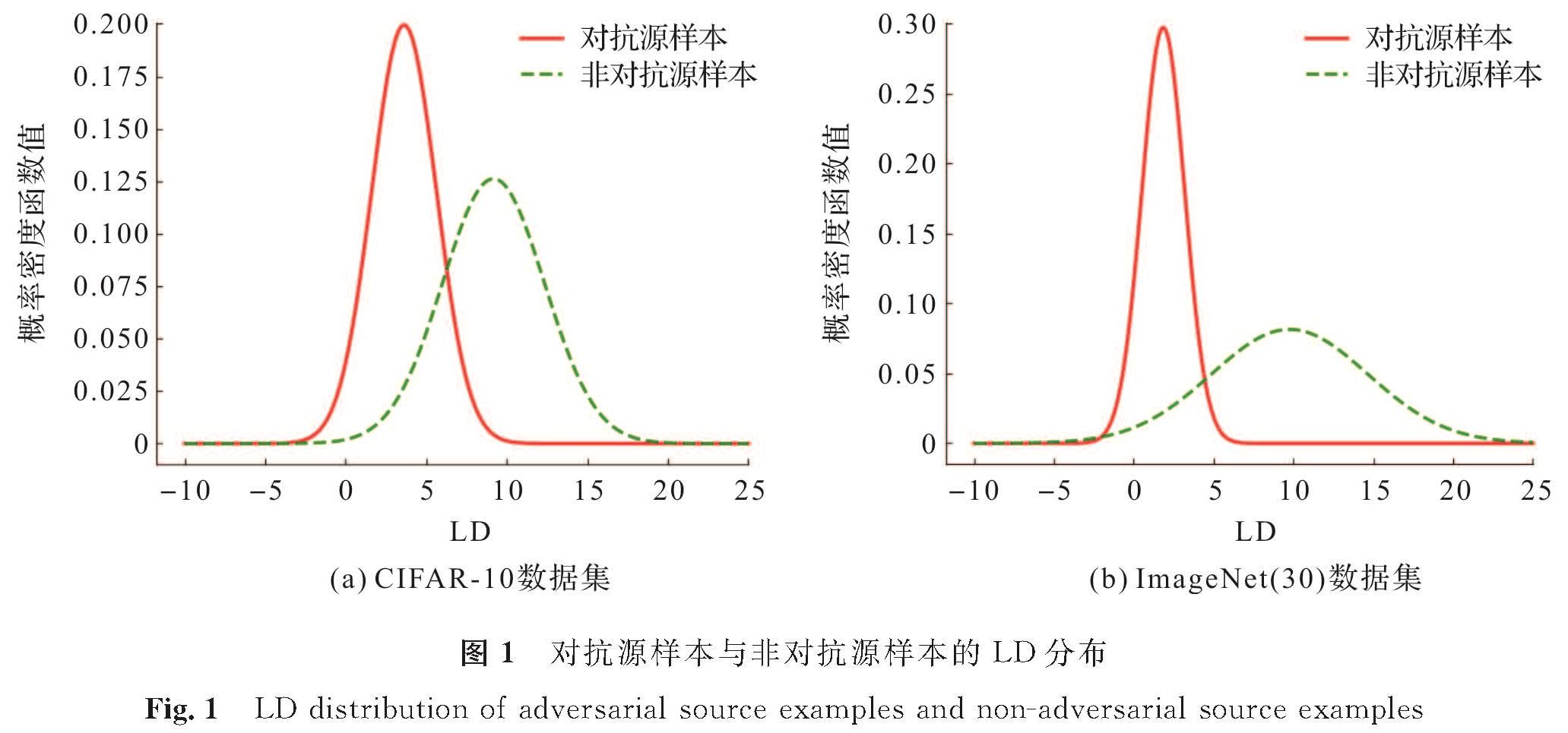
图1 对抗源样本与非对抗源样本的LD分布
Fig.1 LD distribution of adversarial source examples and non-adversarial source examples
2.3 寻找最小扰动

由于在约束条件zy+Δy<zs+Δs下不能得到可行域的边界,故进一步放松约束条件,要求zy+Δy≤zs+Δs,此时,所求的Δy和Δs为式(4)的近似最优解。当zy+Δy=zs+Δs时,zy+Δy与zs+Δs通过softmax层后输出的置信值相等,则该样本数据位于第一大类和第二大类的决策边界上,即各有50%的概率归于两类之一。虚拟对抗训练并不严格要求每个样本都生成虚拟对抗样本,若该样本数据添加扰动后被判别为第一大类,则它作为正确样本参与训练; 若被判别为第二大类,则它作为虚拟对抗样本参与训练。根据不等式的求解方法,可以得到Δy=-(zy-zs)/2,Δs=(zy-zs)/2,λ=zy-zs。因此,式(3)的近似最优解为Δ*=(Δ1,…,Δj,…,ΔC),即
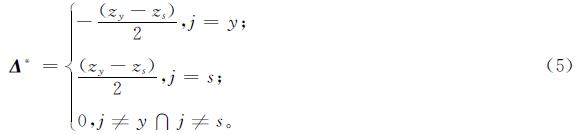
利用虚拟对抗样本和干净样本训练模型的方法称为虚拟对抗训练。图2为虚拟对抗训练方法示意图,其具体做法是:1)设定T个训练周期,把训练集分为M个批次,将第一个批次的训练数据输入参数为θ0的模型,通过神经网络倒数第二层得到logits,即z; 选出满足条件LD<γ的z,即对抗源样本的z,为其添加相应的扰动Δ,非对抗源样本保持不变; 通过softmax层计算损失,进行反向传播更新参数θ0为θ1。2)对剩余的M-1个批次重复上述过程,直至参数由θM-1更新为θM,即完成一个周期的训练。3)重复上述流程,直至完成T个周期的训练。
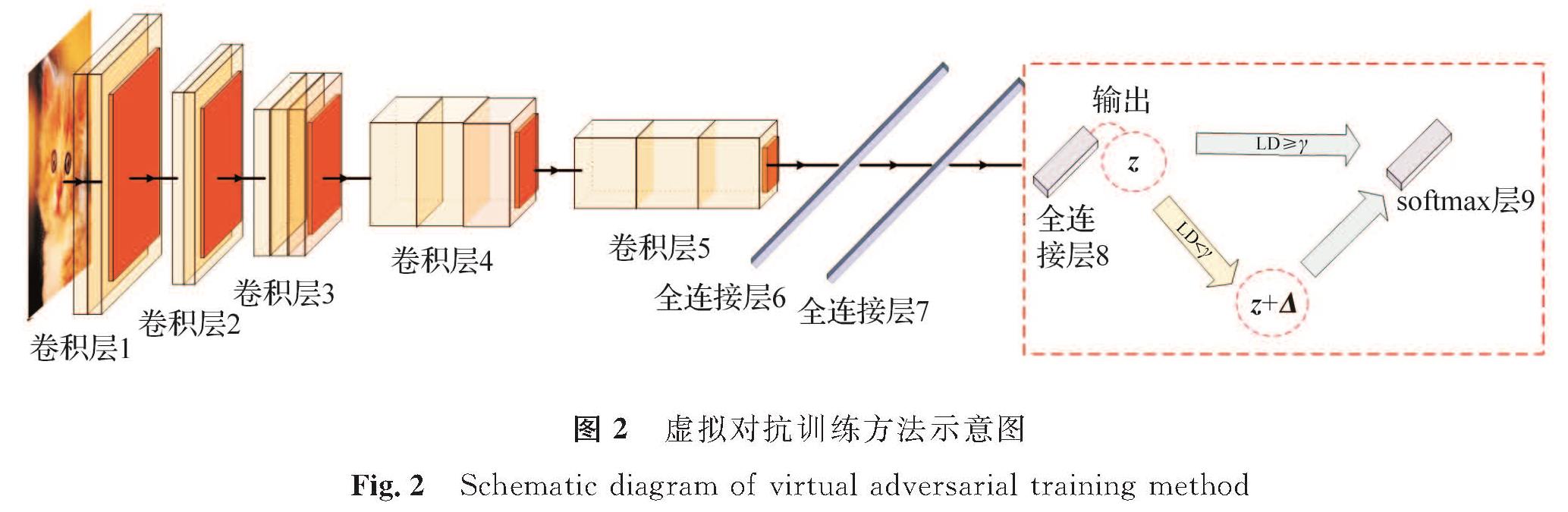
图2 虚拟对抗训练方法示意图
Fig.2 Schematic diagram of virtual adversarial training method
3 试验评估
在深度神经网络架构上测试虚拟对抗训练算法,应用于CIFAR-10和ImageNet(30)图片分类数据集。
3.1 试验设置本研究的试验采用2个基准数据集:CIFAR-10和ImageNet(30)。CIFAR-10包含60 000张彩色图片,其中50 000张作为训练集,10 000张作为测试集,图片大小为32×32像素,总共10类。ImageNet(30)是在ImageNet上随机挑选的30类彩色图片,每类1 350张,其中39 000张作为训练集,1 500张作为测试集,图片大小为224×224像素。由于现实生活中很难知道对抗样本的来源,为了更切合真实情况,试验采用黑盒攻击,即对手不了解目标模型的内部知识,具体而言,用于对抗训练的网络架构与用于生成对抗样本的网络架构不同。
在CIFAR-10上几种对抗训练的网络架构为ResNet-18,测试集为攻击VGG-16网络架构训练的模型生成的扰动样本。在ImageNet(30)上使用Pytorch提供的预训练模型进行再训练,几种对抗训练的网络架构为AlexNet,测试集为攻击ResNet-18网络架构训练的模型生成的扰动样本。
本试验硬件如下:显卡型号为Titan XP,有4个GPU,内存为12 GB; 服务器操作系统为Ubuntu16.04.6 LTS。模型的训练使用了循环学习率[16],可以大幅减少深度神经网络训练所需要的训练周期。
3.2 阈值对虚拟对抗训练的影响阈值γ作为一个超参数,会影响经过虚拟对抗训练后的模型的效用。以下从3个方面验证阈值对虚拟对抗训练的影响:训练所需的时长; 训练后的模型对干净样本的测试精度; 训练后的模型对扰动样本的测试精度。
在CIFAR-10上设定虚拟对抗训练的训练周期为4,网络架构为ResNet-18,循环学习率最小值为0,最大值为0.2,干净样本集为测试集上被F1分类正确的样本,其中F1是使用干净样本对ResNet-18进行训练得到的模型,扰动样本集为对F1进行FGSM攻击生成的样本,扰动大小为0.05。在ImageNet(30)上设定虚拟对抗训练的训练周期为4,网络架构为AlexNet,循环学习率最小值为0,最大值为0.02,干净样本集为测试集上被F3分类正确的样本,其中F3是使用干净样本对AlexNet进行训练得到的模型,扰动样本集为对F3进行FGSM攻击生成的样本,扰动大小为0.007。图3为阈值对虚拟对抗训练时长、干净样本预测精度和扰动样本预测精度的影响。
由图3(a)和(d)可知,随着阈值的增加,虚拟对抗训练所需的时间呈现增加的趋势。在CIFAR-10上,当γ<6时,随着阈值的增加,虚拟对抗训练的训练时间增加得比较快; 而γ>6时,训练时间增加得较慢,基本上稳定在6.25 min。类似地,在ImageNet(30)上,当γ>15时,训练时间趋于稳定。阈值较大时,训练时间趋于稳定是因为当阈值大于某个值后,大多数样本都改变其logits,此时再增加阈值,也不会改变更多的样本,因而也不会再延长训练时间。
由图3(b)和(e)可知,无论在CIFAR-10上还是在ImageNet(30)上,随着阈值增大,虚拟对抗训练后的模型会影响对干净样本的分类效果。尤其是在CIFAR-10上,预测精度的最大值与最小值之差约为5.9%。
由图3(c)和(f)可以看出知,随着阈值的增大,虚拟对抗训练后的模型对扰动样本的预测精度提高。但从预测精度的最大值和最小值来看,在CIFAR-10上,二者之差不超过1.6%,测试精度相差不大; 而在ImageNet(30)上,二者之差大约为3.5%,这也说明阈值增大能够增强模型的鲁棒性。
综上所述,阈值越小,训练时间越短,对干净样本的预测效果越好,对扰动样本的防御效果影响不大。因此,在应用虚拟对抗训练时可以选取一个较小的阈值。
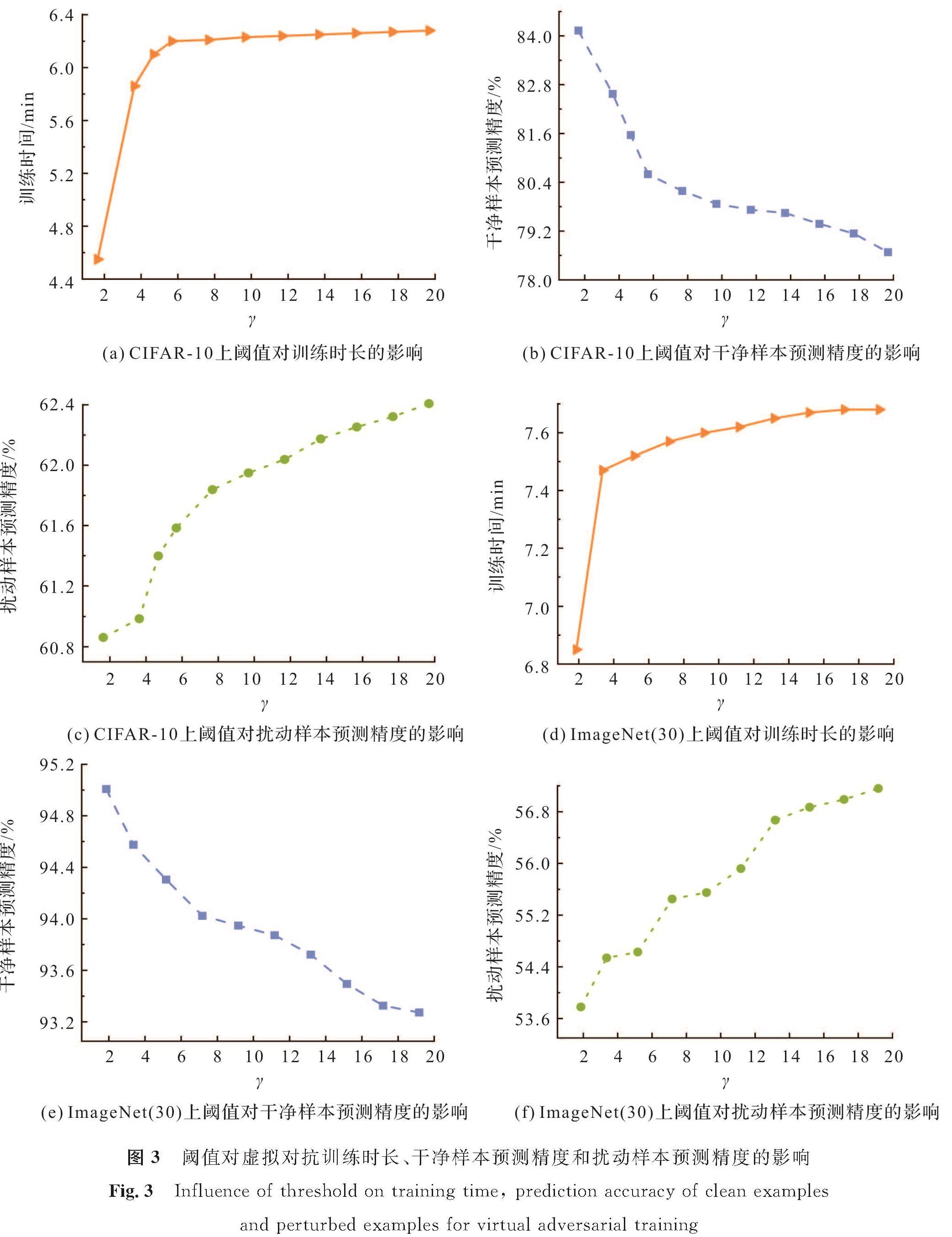
图3 阈值对虚拟对抗训练时长、干净样本预测精度和扰动样本预测精度的影响
Fig.3 Influence of threshold on training time, prediction accuracy of clean examples and perturbed examples for virtual adversarial training
3.3 虚拟对抗训练与其他对抗训练的比较
把虚拟对抗训练应用于CIFAR-10和ImageNet(30)数据集上,以对比几种对抗训练后的模型对干净样本的预测精度、对扰动样本的预测精度及模型训练时间。在CIFAR-10和ImageNet(30)上,分别使用虚拟对抗训练、FGSM对抗训练、Fast对抗训练及PGD对抗训练进行试验。
在CIFAR-10上,4种对抗训练的网络架构为ResNet-18,训练周期为4,循环学习率最小值为0,最大值为0.2。对于虚拟对抗训练,阈值γ=3.63; 对于FGSM对抗训练,扰动大小为16/255; 对于Fast对抗训练,扰动大小为16/255,步长为20/255; 对于PGD对抗训练,扰动大小和步长分别为16/255和8/255,迭代次数为4。为了说明对抗训练能提升对扰动样本的防御效果,只用干净样本训练的ResNet-18模型(即ResNet-18标准训练)作为对照,训练周期也为4。此外,使用干净样本训练VGG-16模型(即F2),用于得到干净测试集和扰动测试集。干净测试集为CIFAR-10测试集上被F2预测正确的样本,扰动测试集为攻击F2生成的扰动样本,攻击方法分别为FGSM、基本迭代法(basic iterative methon,BIM)[17]、PGD、RFGSM[18]、Fast、C&W(Carlini & Wagner)攻击[19]和动量差分输入迭代快速梯度符号法(momentum diverse input iterative fast gradient sign method,M-DI2-FGSM)[20]。
在ImageNet(30)数据集上,4种对抗训练的网络架构为AlexNet,训练周期为4,循环学习率最小值为0,最大值为0.02。对于虚拟对抗训练,阈值γ=2.0; 对于FGSM对抗训练,扰动大小为2/255; 对于Fast对抗训练,扰动大小为2/255,步长为3/255; 对于PGD对抗训练,扰动大小和步长分别为2/255和1/255,迭代次数为3。使用干净样本训练的AlexNet模型(即AlexNet标准训练)作为对照,训练周期为4。使用干净样本训练ResNet-18模型(即F4),用于得到干净测试集和扰动测试集,干净测试集为ImageNet(30)测试集上被F4预测正确的样本,扰动测试集为攻击F4生成的扰动样本,攻击方法分别为FGSM、BIM、PGD、RFGSM、Fast、C&W和M-DI2-FGSM。
3.3.1 对抗训练后的模型对干净样本分类效果的比较图4为标准训练和对抗训练后的模型对干净样本的预测精度。从图4中可以看出,与标准训练相比,对抗训练后的模型会降低对干净样本的分类精度,而本研究提出的虚拟对抗训练优于其他对抗训练,在CIFAR-10上,预测精度比其他对抗训练的模型预测精度高出7.21~14.68百分点,在ImageNet(30)上,预测精度高出8.31~11.47百分点,甚至高于标准训练模型的预测精度。
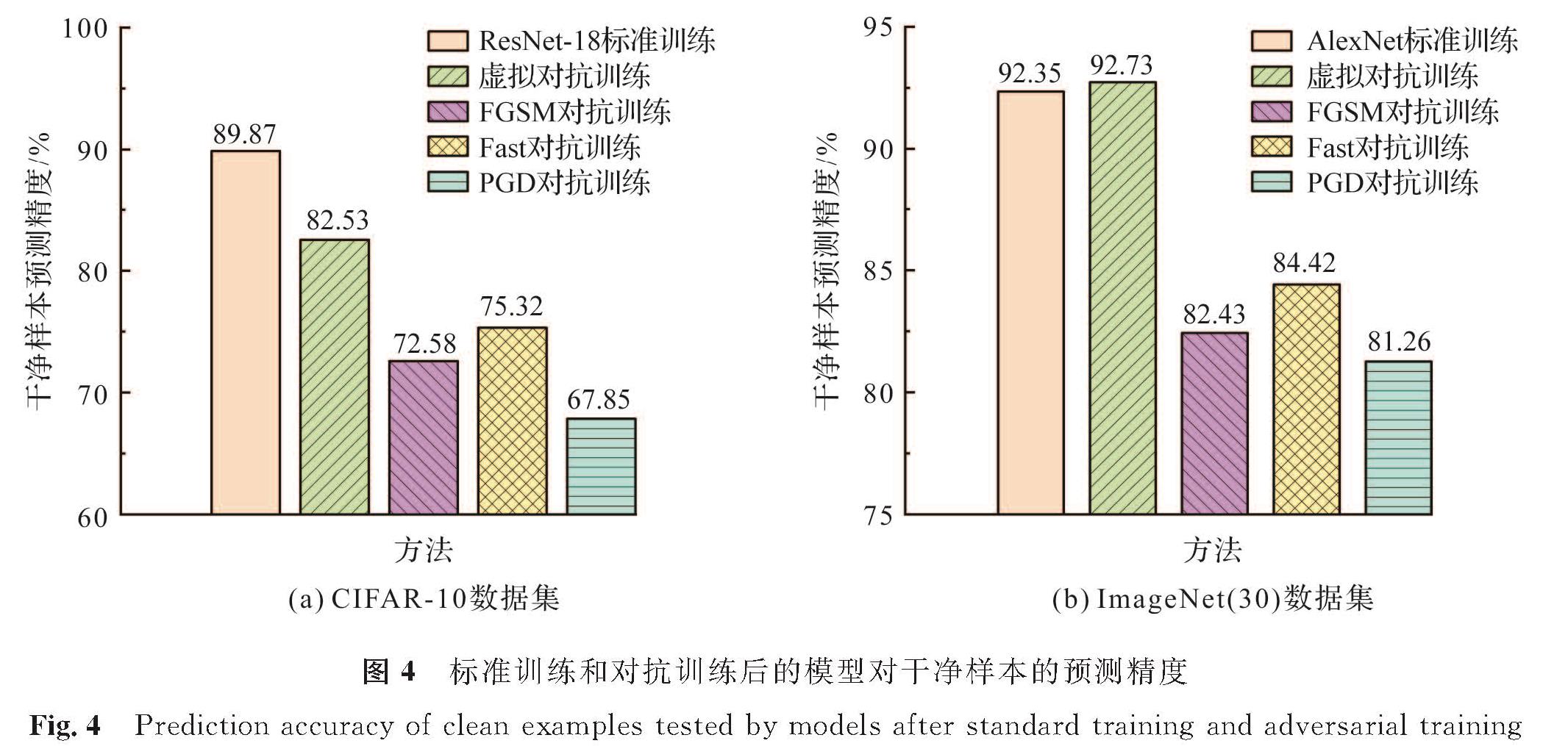
图4 标准训练和对抗训练后的模型对干净样本的预测精度
Fig.4 Prediction accuracy of clean examples tested by models after standard training and adversarial training
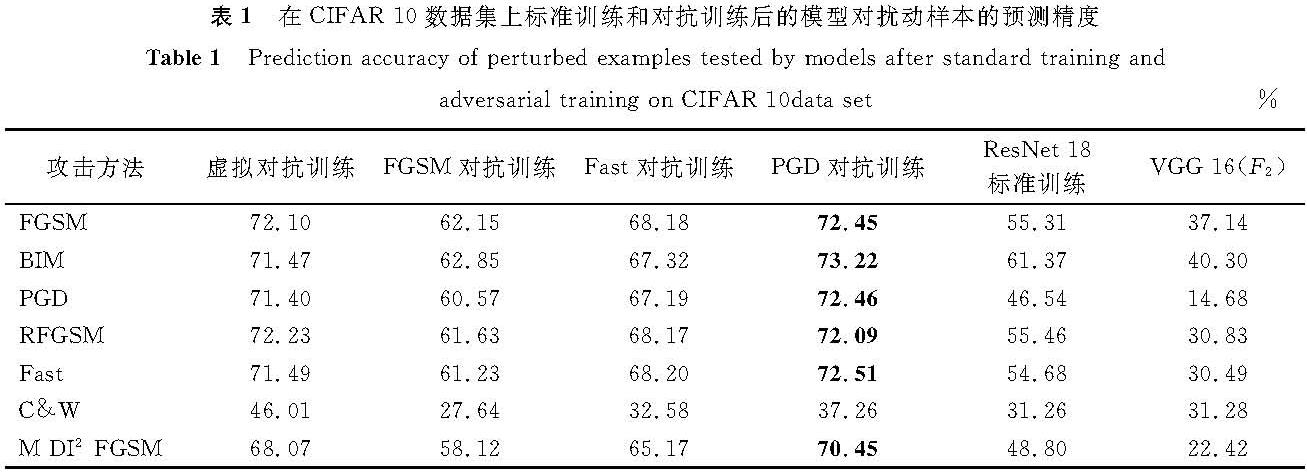
在CIFAR-10数据集上标准训练和对抗训练后的模型对扰动样本的预测精度见表1。在表1中,FGSM中的扰动大小为12/255; BIM和PGD中的扰动大小、步长和迭代次数分别为12/255、4/255、4; RFGSM中的扰动大小为12/255,步长为8/255,迭代次数为2; Fast的参数为扰动大小12/255,步长为15/255; C&W为无目标攻击,其中箱型约束为1,置信度为1,迭代次数为30,Adam学习率为0.01; M-DI2-FGSM中扰动大小为12/255,迭代次数为2,衰减率和变换可能性均为1。最后一列为F2在各种攻击下的预测精度,是为了判别扰动测试集中对抗样本所占的比例,以更直观地反映其他模型对F2生成的扰动样本的防御效果。
表1 在CIFAR-10数据集上标准训练和对抗训练后的模型对扰动样本的预测精度
Table 1 Prediction accuracy of perturbed examples tested by models after standard training and adversarial training on CIFAR-10data set%
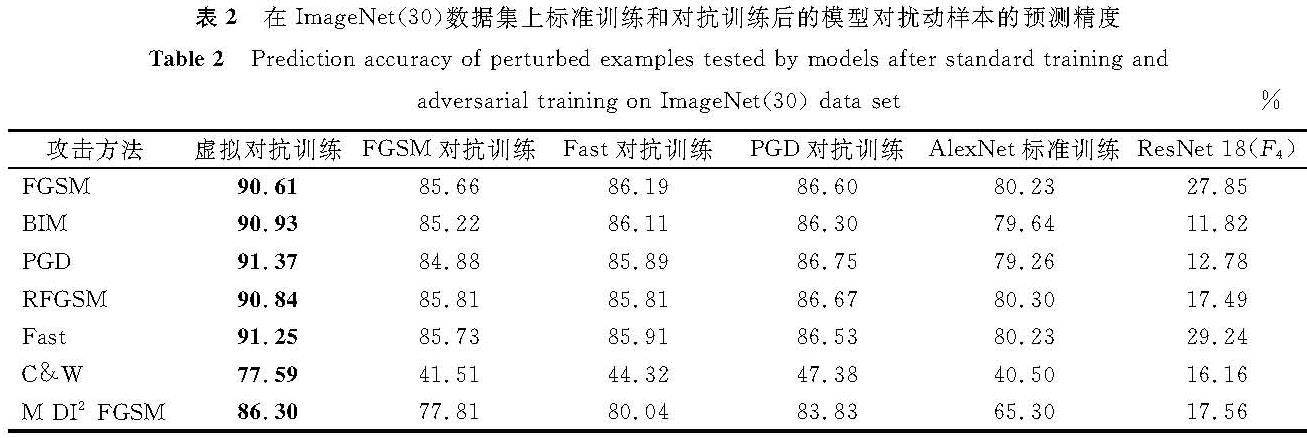
在ImageNet(30)上标准训练和对抗训练后的模型对扰动样本的预测精度见表2。在表2中,FGSM中的扰动大小为2/255; BIM和PGD中的扰动大小为2/255,步长为1/255,迭代次数为3; RFGSM中的扰动大小为2/255,步长为1/255,迭代次数为2; Fast中的扰动大小为2/255,步长为3/255; C&W为无目标攻击,其中箱型约束为5,置信度为1,迭代次数为20,Adam学习率为0.01; M-DI2-FGSM中的扰动大小为2/255,迭代次数为2,衰减率和变换可能性均为1。
表2 在ImageNet(30)数据集上标准训练和对抗训练后的模型对扰动样本的预测精度
Table 2 Prediction accuracy of perturbed examples tested by models after standard training and adversarial training on ImageNet(30)data set%
3.3.2 对抗训练后的模型对扰动样本分类效果的比较
通过表1和表2可知,与标准训练后的模型相比,对抗训练极大地增强了模型的鲁棒性。通过比较4种对抗训练模型的防御效果可以看出,在CIFAR-10上,虚拟对抗训练的防御精度仅低于PGD对抗训练1.06百分点,优于FGSM对抗训练和Fast对抗训练4.21~10.83百分点,但在C&W攻击下,虚拟对抗训练的防御效果最好。在ImageNet(30)上,虚拟对抗训练的防御效果优于其他3种对抗训练。
3.3.3 对抗训练时间的比较表3为4种对抗训练所需的时间。显然,虚拟对抗训练由于不用生成物理意义上的对抗样本,无须计算损失对样本的梯度,从而提高了训练速度。在CIFAR-10和ImageNet(30)数据集上,与目前较先进的Fast对抗训练相比,本研究提出的方法分别缩减了24.19%、26.84%的训练时间,与最慢的PGD对抗训练方法相比,虚拟对抗训练缩减了将近2/3的时间。
表3 4种对抗训练所需的时间
Table 3 Time required for four kinds of adversarial trainingmin

3.3.4 虚拟对抗训练有效的原因
通过试验证明,与传统的对抗训练方法相比,虚拟对抗训练使得满足LD<γ的样本生成虚拟对抗样本,而这些样本位于第一大类和第二大类的决策边界上,每当模型更新参数时,相当于对决策边界进行微调,因此对干净精度的影响较小。同时,由于训练过程不断更新模型参数,这种微调的效果放大,就能有效地防御对抗样本。此外,本研究方法无须考虑计算损失对样本的梯度以更新扰动来生成真实的对抗样本,从而缩短了训练时间。
4 结 语针对传统对抗训练耗时且严重降低对干净样本预测精度的缺点,本研究提出了一种不需要生成对抗样本的虚拟对抗学习方法,通过试验研究了超参数阈值对虚拟对抗训练的影响,并比较了虚拟对抗训练与其他对抗训练的优劣。试验结果证明,本文方法不仅能加速对抗训练过程,在速度上优于传统的对抗训练方法,而且能够增强模型的鲁棒性,同时对干净样本的分类效果影响不大。这是一种具有启发意义的对抗训练方法,未来,我们将借鉴虚拟对抗样本的概念,结合真正的对抗样本生成方法来探索新的攻击与防御方法。
- [1] 郑远攀,李广阳,李晔.深度学习在图像识别中的应用研究综述[J].计算机工程与应用,2019,55(12):20.
- [2] 鱼昆,张绍阳,侯佳正,等.语音识别及端到端技术现状及展望[J].计算机系统应用,2021,30(3):14.
- [3] 王睿怡,罗森林,吴舟婷,等.深度学习在汉语语义分析的应用与发展趋势[J].计算机技术与发展,2019,29(9):110.
- [4] SZEGEDY C, ZAREMBA W, SUTSKEVER I, et al. Intriguing properties of neural networks[C]//International Conference on Learning Representations(ICLR). Banff: OpenReview.net,2014:1.
- [5] GOODFELLOW I J, SHLENS J, SZEGEDY C. Explaining and harnessing adversarial examples[C]//International Conference on Learning Representations(ICLR). San Diego: OpenReview.net,2015:1.
- [6] 吴立人,刘政浩,张浩,等.聚焦图像对抗攻击算法PS-MIFGSM[J].计算机应用,2020,357(5):112.
- [7] 张高志,刘新平,邵明文.用于白盒目标攻击的GAN对抗样本生成[J].模式识别与人工智能,2020,33(9):830.
- [8] 钱亚冠,刘新伟,顾钊铨,等.一种基于二维码对抗样本的物理补丁攻击[J].信息安全学报,2020,5(6):79.
- [9] 许笑,陈奕君,冯诗羽,等.基于冗余信息压缩的深度学习对抗样本防御方案[J].网络空间安全,2020,11(8):11.
- [10] 范宇豪,张铭凯,夏仕冰.基于插值法的对抗攻击防御算法[J].网络空间安全,2020,11(4):74.
- [11] MADRY A, MAKELOV A, SCHMIDT L, et al. Towards deep learning models resistant to adversarial attacks[C]//International Conference on Learning Representations(ICLR). Vancouver:OpenReview.net,2018:1.
- [12] SHAFAHI A, NAJIBI M, GHIASI A, et al. Adversarialtraining for free![C]//Advances in Neural Information Processing Systems(NeurIPS). Vancouver:MIT Press,2019:3358.
- [13] ZHANG D H, ZHANG T Y, LU Y P, et al. You only propagate once:painless adversarial training using maximal principle[C]//Conference on Neural Information Processing Systems(NeurIPS). Vancouver:MIT Press,2019:1.
- [14] ZHU C, CHENGY, GAN Z, et al. FreeLB:Enhanced adversarial training for natural language understanding[C]//International Conference on Learning Representations(ICLR). Addis Ababa:OpenReview.net,2020:1535.
- [15] WONG E, RICE L, KOLTER J Z. Fast is better than free:revisiting adversarial training[C]//International Conference on Learning Representations(ICLR). Addis Ababa:OpenReview.net,2020:1095.
- [16] SMITH L N. Cyclical learning rates for training neural networks[C]//IEEE Winter Conference on Applications of Computer Vision(WACV). Santa Rosa:IEEE,2017:464.
- [17] KURAKIN A, GOODFELLOW I, BENGIO S. Adversarial examples in the physical world[C]//International Conference on Learning Representations(ICLR). Toulon:OpenReview.net,2017:1.
- [18] TRAMER F, KURAKIN A, PAPERNOT N, et al. Ensemble adversarial training:attacks and defenses[C]//International Conference on Learning Representations(ICLR). Vancouver:OpenReview.net,2018:1.
- [19] CARLINI N and WAGNER D. Towards evaluating the robustness of neural networks[C]//IEEE Symposium on Security and Privacy(SP). San Jose:IEEE,2017:39.
- [20] XIE C H, ZHANG Z S, ZHOU Y Y, et al. Improving transferability of adversarial examples with input diversity[C]//IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Long Beach:IEEE,2019:2725.