 图 2 生成器G和判别器D的结构示意图
Fig.2 Structure diagram of generator G and discriminator D
图 2 生成器G和判别器D的结构示意图
Fig.2 Structure diagram of generator G and discriminator D
WANG Jiamin,QIAN Yaguan,LI Simin,et al.Attention-CGAN-based adversarial example denoising method[J].Journal of Zhejiang University of Science and Technology,2022,34(06):512-520.[doi:10.3969/j.issn.1671-8798.2022.06.006]

随着深度学习技术的发展,卷积神经网络(convolutional neural network,CNN)在图像分类上表现出优异的性能。但是,现有研究表明CNN容易受到对抗样本的攻击[1-2]。对抗样本指在图像上添加的肉眼不能察觉的微小扰动,它导致CNN做出错误的预测; 同时,对抗样本的扰动性还可以在不同模型之间转移[3],这种可转移性能在未知目标模型的权重和结构的情况下进行黑盒攻击。在现实世界中,黑盒攻击已被证明是可行的,这对某些安全敏感的领域(例如身份认证)构成了极大的威胁。因此,构建有效的防御措施,保证深度学习技术能被安全运用,已成为急需解决的问题。
目前,针对对抗样本的问题,人们提出了很多防御方法,大致分为四类:1)对抗训练[4],通过在数据集中添加对抗样本及正确的类标签,修正决策边界,增强模型的鲁棒性; 2)防御蒸馏[5],将复杂模型所获得的知识转移到更简单的模型上,实现梯度掩蔽的目的; 3)对抗样本检测[6],通过检测对抗样本,防止对抗图像输入CNN; 4)去噪预处理,在输入CNN之前将对抗样本的噪声消除,达到保护CNN不被欺骗的目的[7]。我们提出的方法属于去噪预处理,一种基于注意力机制的条件生成对抗网络(attention conditional generative adversarial net,Attention-CGAN)的对抗样本去噪方法。目前也有类似的方法被提出,例如Samangouei等[8]提出防御生成对抗网络(defense generative adversarial net,Defense-GAN),该方法利用WGAN[9](Wasserstein GAN)生成模型来模拟干净图像的分布,达到有效地防御对抗样本的目的; Shen等[7]提出基于GAN消除对抗扰动(adversarial perturbation elimination with GAN,APE-GAN),该方法使用干净样本训练GAN,生成器用于去除对抗样本的噪声,判别器用于区分去噪样本与干净样本; Liu等[10]提出将干净样本和对抗样本同时输入生成器,考虑了干净样本的分布,从而提高了模型的防御性能。但是,以上几种方法都没有将注意力机制[11]和分类损失考虑在内,使得生成器不能处理例如ImageNet这种比较复杂的图像,也不能保证去除噪声后的样本注意力与干净样本注意力一致。为了解决这些问题,我们提出Attention-CGAN,即在训练CGAN的时候,构造新的损失函数——注意力损失函数和分类损失函数,以达到在去噪的同时保留干净样本注意力的目的。
1 基于Attention-CGAN的对抗样本防御Attention-CGAN的对抗防御流程分为两步:第一步,通过构造注意力分类损失函数训练CGAN来修复对抗样本,得到一个重建的图像; 第二步,将重建的图像输入分类器,如果能被正确分类,则达到消除噪声对图像语义影响的目的。本研究在训练Attention-CGAN时加入了分类损失,其目的是利用标签信息使得生成器的模拟空间变小,从而降低模型的训练难度。
基于Attention-CGAN的对抗样本防御方法流程图如图1所示。Attention-CGAN由三部分组成:生成器G、判别器D及注意力分类损失函数LAttention-CGAN。假设干净样本为x,扰动为δ,那么干净样本对应的对抗样本x'=x+δ,生成器和判别器均以额外信息x'为条件,直接学习输入x'与输出去噪样本x″之间的映射。生成器G用于重建注意力区域,得到去噪样本x″,而判别器D尽可能检测出G“伪造”的x″,D也可以看作是G的指导。考虑到CGAN训练的不稳定性,为避免G合成的输出图像中出现伪像,从而导致x″输入分类器时很难被正确分类,本研究定义了注意力分类损失函数来解决此问题。
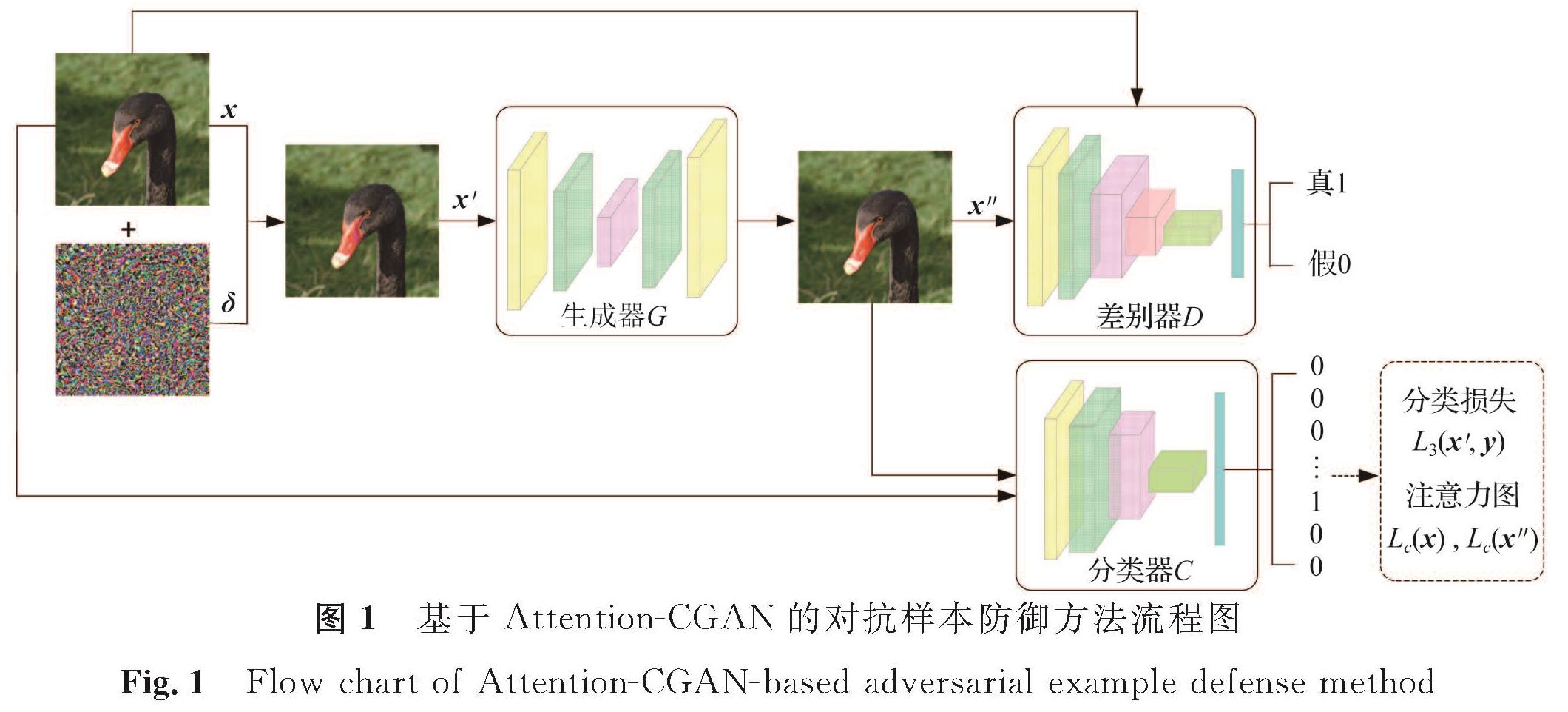
图1 基于Attention-CGAN的对抗样本防御方法流程图
Fig.1 Flow chart of Attention-CGAN-based adversarial example defense method
1.1 Attention-CGAN
Attention-CGAN的生成器G和判别器D共同构成一个动态博弈模型。判别器D的任务是区分来自模型的样本和来自训练数据的样本,生成器G的任务是最大限度地混淆D。上述博弈过程可以当作一个极小极大问题来建立模型:
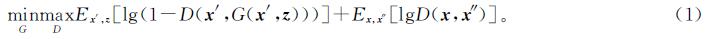
式(1)中:E为数学期望; z为随机噪声。生成器G和判别器D的定义及结构如下。
1.1.1 生成器G(Z×X')→X″是生成模型,生成器G接收随机噪声数据z∈Z及对抗样本x'∈X',生成去噪图像x″∈X″。对于单个对抗样本x'去噪,在不丢失背景图像任何细节信息的情况下,生成器G尽可能地重建注意力区域,使得x″与x的分布无限接近。因此,问题的关键在于设计一个良好的G的结构来生成x″。
目前很多方法是基于稀疏编码[12-14],这些方法采用的是对称编码-解码结构,将输入的图像传输到特定域来有效分离背景图像和不需要的成分(例如本研究的对抗扰动),在分离之后将背景图像(在新域中)转移回原始域。因此,本研究生成器的结构采用U形对称网络,其结构示意如图2。U形对称网络是在图像分割领域应用非常广泛的网络结构,利用跳跃连接(skip-connections),使不同分辨率条件下低层的细节信息得以保留,从而能充分融合特征[15]。
参考文献[16],本研究G的结构采用步幅为2的4个向下卷积层,9个残差块[17]和4个向上卷积层。
1.1.2 判别器D(X″×X)→[0,1]是判别模型,判别器D接收x″和x,尽可能检测出G“伪造”的x″,D也可以看作是G的指导。从Attention-CGAN结构来看,对输入的x'进行去噪得到x″,不仅是为了使x″在视觉上与x接近,而且还确保x″与x在定量角度相当甚至不可区分。因此,D针对每个输入图像的真伪进行分类。本研究D的结构是一个7层卷积神经网络,其结构示意如图2。
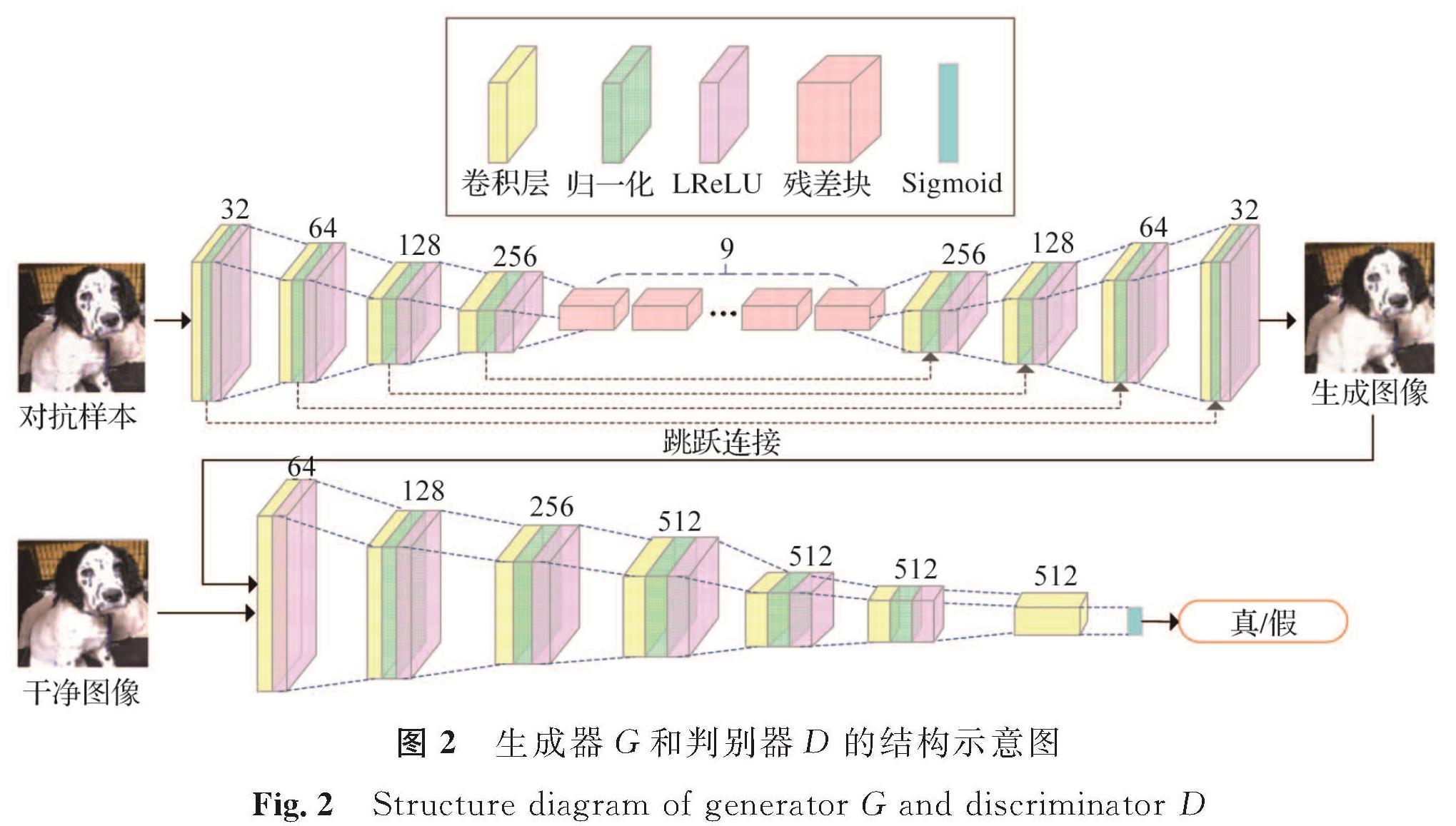
图2 生成器G和判别器D的结构示意图
Fig.2 Structure diagram of generator G and discriminator D
1.2 注意力提取
基于CNN的图像分类与传统的图像分类方法不同,CNN能自动提取图像的特征[18]。注意力区域是CNN进行决策的依据,干净样本和对抗样本的注意力图如图3所示,从图中可看出,对抗样本的注意力区域明显发散,即成功的对抗攻击倾向于偏离和分散注意力区域。因此,需要求出不同特征对CNN决策的重要性,即求出模型的注意力区域。将一个完整的特征图作为基本特征检测器,假设输入图像x∈Rm,x通过CNN后,在最后一层卷积层输出该图像的高层特征A,其中用A(k)∈Ru×v表示高层特征A中第k个卷积核的激活输出,卷积核的大小为u×v。A经过全连接层后,会输出每个类的置信度向量Z,Zc表示第c类的概率值,该值越大表示x被预测为第c类的概率就越大。Zc对A(k)的梯度 可以用来衡量第k个卷积核对第c类的分类预测重要性。基于此,本研究进一步采用全局平均池化操作,计算第k个卷积核的权重
可以用来衡量第k个卷积核对第c类的分类预测重要性。基于此,本研究进一步采用全局平均池化操作,计算第k个卷积核的权重

式(2)中:p和q为激活输出的坐标位置; A(k)pq为第k个卷积核在(p,q)处的激活输出。最后,结合权重λ(k)c对A(k)进行加权求和,得到关于第c类的一个特征激活映射∑kλ(k)cA(k)。考虑到只有∑kλ(k)cA(k)中的正值会对最后的分类结果产生积极作用,所以对最终的加权结果再进行一次ReLU激活处理,去除负值的影响,得到第c类的注意力图


图3 干净样本和对抗样本的注意力图
Fig.3 Attention maps of clean examples and adversarial examples
1.3 损失函数
由于CGAN训练极不稳定,会导致以下3种情况:第一,去噪之后的图像仍然带有噪声,或者出现畸形; 第二,去噪之后的图像不能保留原始图像的语义特征,即注意力区域发生转移; 第三,去噪之后的图像输入分类器后不能被正确分类。为了解决这些问题,本研究引入注意力损失函数、分类损失函数及感知损失函数来训练生成对抗网络:
LAttention-CGAN=L0+λ1L1+λ2L2+λ3L3+λ4L4。(4)
式(4)中:L0为像素级损失函数; L1为对抗损失函数; L2为注意力损失函数; L3为分类损失函数; L4为感知损失函数; λ1、λ2、λ3和λ4分别为对抗损失函数、注意力损失函数、分类损失函数及感知损失函数的预定义权重。新的损失函数LAttention-CGAN能保留图像的原始注意力区域,同时保留图像的颜色和纹理信息,使去噪之后的图像拥有良好的视觉效果,且能够被正确分类,最终达到防御的目的。下面给出L0、L1、L2、L3及L4的具体形式。
1.3.1 像素级损失函数给定一个通道为C、宽为W、高为H的图像对{x',x}(即C×W×H),像素级的损失函数定义为
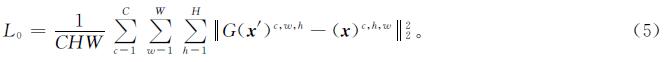
注意力损失函数最大程度地减少2张注意力图之间的成对差异,其公式为
L2=||Fc(x)-Fc(G(x'))||22。(6)
1.3.3 对抗损失函数和分类损失函数给定N个输入-标签对(xi,x'i,yi),对抗损失函数及分类损失函数的计算分别如下:
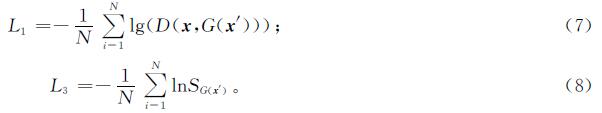
式(8)中:S为softmax函数。
1.3.4 感知损失函数假设某个网络φ第i层输出的特征图大小为Ci×Wi×Hi,其感知损失函数的计算如下:
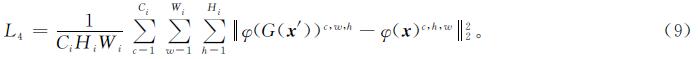
本研究采用的感知损失函数与文献[19]中的方法类似,加入感知损失函数的目的是最小化高级特征之间的距离,不同之处在于本研究采用的是VGG-16的ReLU3_3层的输出来计算感知损失。
2 试验评估为了验证本文方法的有效性,我们在2个基准数据集上进行了试验。首先通过可视化分析,从肉眼角度直观说明用本方法对图像去噪的可行性,以及验证去噪之后的图像注意力区域是否保持不变; 然后采用典型对抗攻击,包括PGD和C&W方法来验证Attention-CGAN的防御性能; 最后与目前最新的防御方法进行比较,以验证Attention-CGAN的有效性。
2.1 试验设置2.1.1 数据集在CIFAR10[20]和ILSVRC2012[21]2个基准数据集上进行试验验证,所有的自然图像均归一化到[0,1]。CIFAR10数据集由60 000张32×32×3像素的图像组成,包含10类图像,每类6 000张图,其中50 000张用于训练,另外10 000张用于测试。ILSVRC2012图像分类数据集包含1 000类图像,共有120万张244×244×3像素的图片,其中50 000张作为验证集。
2.1.2 模型和试验环境所有的CIFAR10试验均使用AlexNet[22]、VGG11[23]和ResNet18[17]网络结构,在单个GeForce RTX 2080ti上运行; 所有的ILSVRC2012试验均使用AlexNet、VGG16和ResNet34网络结构,在4个GeForce RTX 2080tis上运行。
2.1.3 Attention-CGAN的训练方法使用自适应动量(adaptive momentum,Adam)优化器,初始学习率设置为0.0 002,CIFAR10和ILSVRC2012的批量分别为128和32,CIFAR10和ILSVRC2012的迭代次数分别为1 000和2 000,损失函数的权重分别为λ1=1、λ2=1、λ3=1.5和λ4=1。
2.1.4 攻击方法在评估试验中使用PGD-50、C&W(l2范数)攻击。对于PGD-50,扰动约束设置为16/255,步长为2/255,随机重启10次; 对于C&W设置常数为1,学习率为0.01,迭代1 000次。
2.1.5 评价指标采用分类器的分类准确率来定量分析本研究方法的防御性能,峰值信噪比(peak signal to noise ratio,PSNR)[24]和结构相似性指数(structural similarity,SSIM)[25]用来定量分析生成图片的质量。给定H×W像素的图像x,其对应的对抗样本为x',那么x与x'之间的PSNR和SSIM可定义为
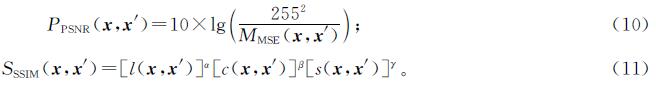
式(10)~(11)中:MXMSE(x,x')为x与x'的均方误差; α、β、γ均大于0; l(x,x')为亮度比较; c(x,x')为对比度比较; s(x,x')为结构比较。
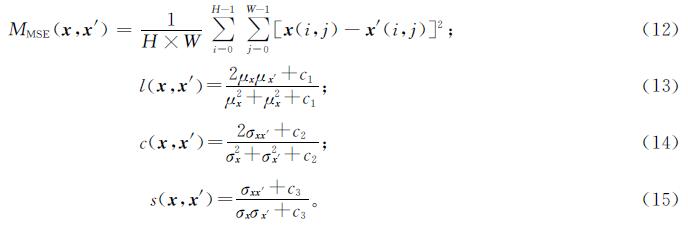
式(13)~(15)中:μx和μx'分别为x与x'的像素平均值; σx和σx'分别为x与x'的像素标准差; σxx'为x与x'之间的像素协方差; c1、c2和c3和数。
2.2 可视化结果为了验证本算法能较好地去除噪声,本研究通过两步来说明。第一,通过可视化分析来说明Attention-CGAN的去噪结果在视觉上的可行性。Attention-CGAN在CIFAR10和ILSVRC2012数据集上的可视化试验结果如图4所示,从图4(a)第三行可以清楚观察到Attention-CGAN具有很好的去噪性能,并且能充分学习数据集的特征,这一点在ILSVRC2012数据集上体现更为明显(图4(b))。与CIFAR10相比,ILSVRC2012更好地反映图像的细节特征,图像的语义特征也更加清晰,即使图像纹理更加复杂,Attention-CGAN依然可以达到良好的去噪效果。第二,通过可视化分析来说明去噪后的图像具有语义不变性。干净样本与其对应的去噪样本的注意力示意图如图5所示,图中第一行为干净样本及其对应的注意力区域,第二行为去噪之后的样本及其对应的注意力区域,从中可以观察到去噪之后的样本注意力区域几乎不会发生转移,这也说明本研究提出的方法在去噪的同时有效地保留了干净样本的特征,使得图像注意力区域几乎不发生偏移。

图4 Attention-CGAN在CIFAR10和ILSVRC2012上的可视化试验结果
Fig.4 Visualization test results of Attention-CGAN in CIFAR10 and ILSVRC2012

图5 干净样本与其对应的去噪样本的注意力示意图
Fig.5 Attention map of clean examples and their corresponding denoised examples
2.3 对几种攻击方法的防御
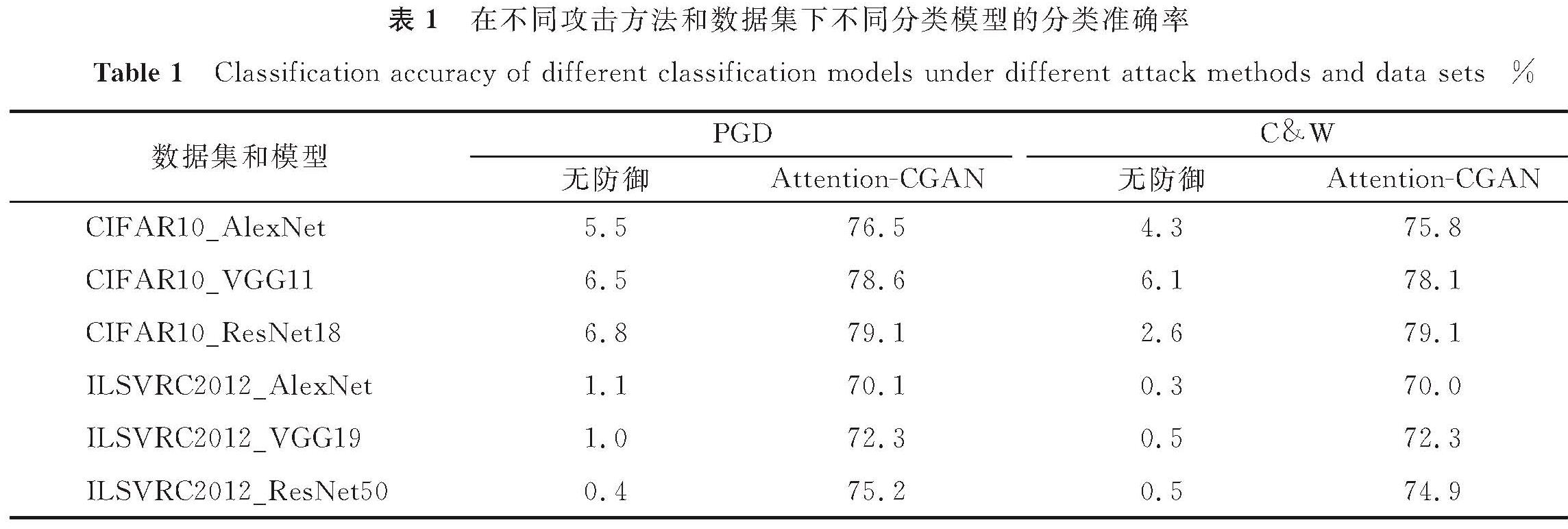
本研究利用定量试验来验证Attention-CGAN的防御性能。表1展示了在CIFAR10和ILSVRC2012上基于PGD和C&W攻击算法的不同分类模型的分类准确率。由表1可知,本研究提出的Attention-CGAN方法对对抗样本具有很好的复原效果,去噪之后的分类准确率显著提高。例如,使用PGD对CIFAR10_ResNet18的攻击,去噪之后的分类准确率从6.8%提高到79.1%。接下来,将本文方法与其他防御方法进行对比,以进一步说明Attention-CGAN的防御性能。
表1 在不同攻击方法和数据集下不同分类模型的分类准确率
Table 1 Classification accuracy of different classification models under different attack methods and data sets%
2.4 不同防御方法的对比试验
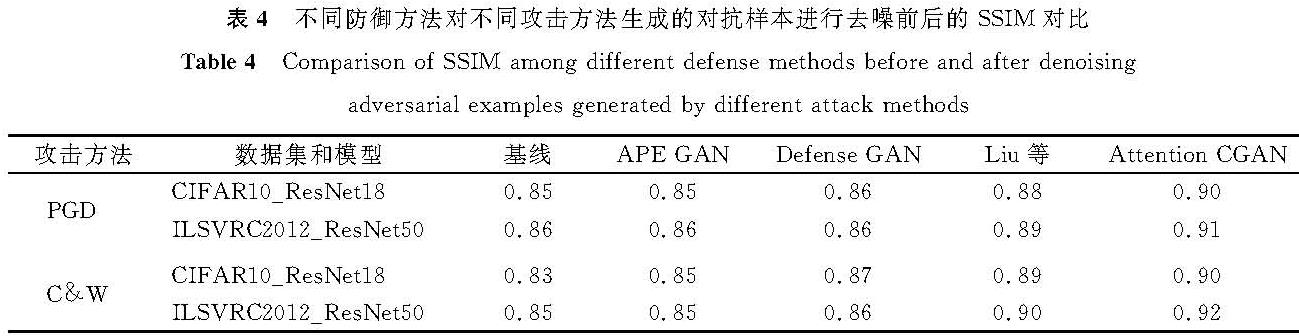
为了进一步验证Attention-CGAN的有效性,将其与现有的3种防御方法进行比较,分别是APE-GAN[7]、Defense-GAN[16]和Liu等[18]提出的方法。不同模型和数据集下4种防御方法分类准确率的比较见表2,其中攻击方法采用PGD-50算法,在CIFAR10_VGG11上,与上述3种方法相比,本算法的分类准确率分别提高了7.5%、8.3%和7.5%。这说明本研究提出的方法能有效去除对抗样本的噪声,达到防御对抗攻击的目的。同时,本研究采用2个广泛使用的图像质量度量指标PSNR和SSIM,来定量分析去噪后样本与干净样本的相似度。这两个指标有相同的评价标准,即其值越大图像质量越好。不同防御方法对不同攻击方法生成的对抗样本进行去噪前后的PSNR和SSIM对比见表3和表4,与其他3种方法进行比较,本研究所提方法的PSNR和SSIM明显较高,表明Attention-CGAN显著提高了图像的质量,而且有效地保留了干净样本的重要语义特征,使得去噪之后的样本注意力区域与干净样本保持一致。
表2 不同模型和数据集下4种防御方法分类准确率的比较
Table 2 Comparison of classification accuracy of four defense methods under different models and data sets%
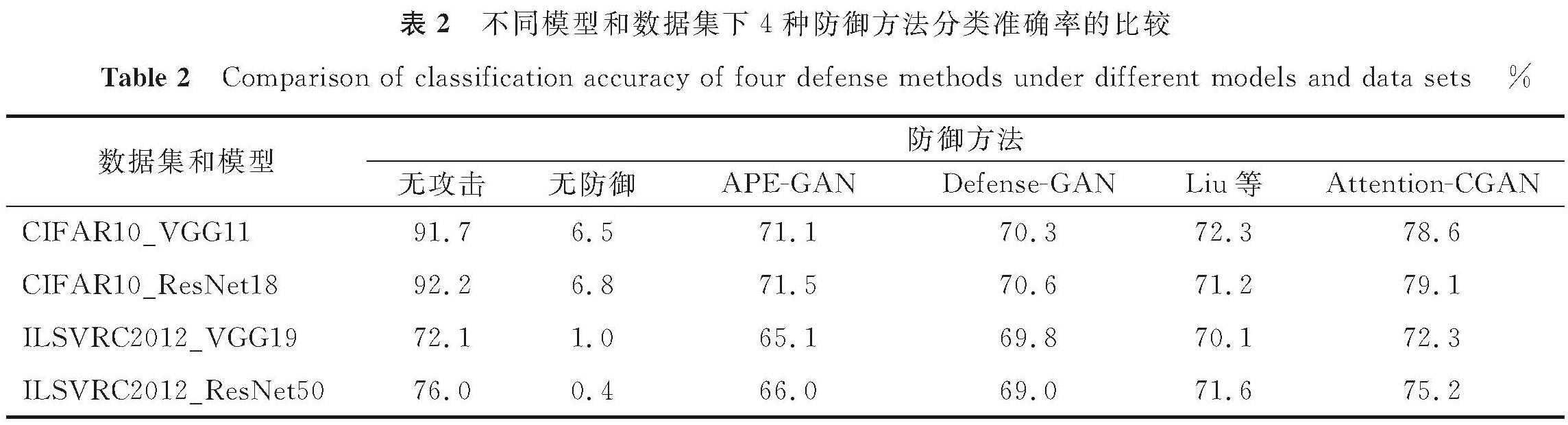
表3 不同防御方法对不同攻击方法生成的对抗样本进行去噪前后的PSNR对比
Table 3 Comparison of PSNR among different defense methods before and after denoising adversarial examples generated by different attack methods
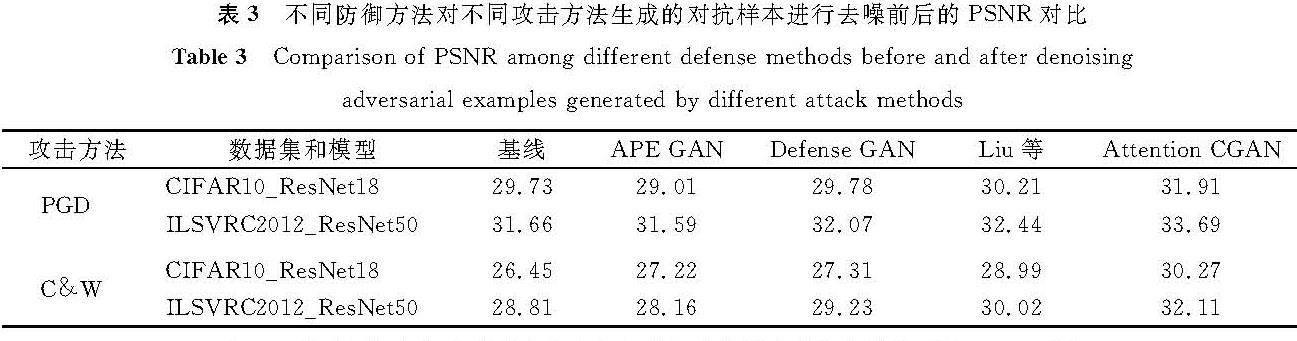
表4 不同防御方法对不同攻击方法生成的对抗样本进行去噪前后的SSIM对比
Table 4 Comparison of SSIM among different defense methods before and after denoising adversarial examples generated by different attack methods
3 结 语
本研究提出了一种新的对抗样本防御方法——Attention-CGAN:引入注意力分类损失有效地实现对抗样本的去噪,同时保留干净样本的语义特征; 利用标签信息减少了Attention-CGAN的训练难度,使得去噪后的样本和干净样本的分布更接近,从而提高了分类器对对抗样本的防御性能。在2个数据集上进行了大量的定性和定量试验,结果表明,Attention-CGAN能有效地去除对抗样本的噪声且保留原始干净样本的语义特征,从而验证了本防御方法的有效性。
- [1] XIE C, YUILLE A. Intriguing properties of adversarial training at scale[EB/OL].(2016-06-10)[2021-07-28]. https://arxiv.org/abs/1906.03787.
- [2] 刘西蒙,谢乐辉,王耀鹏,等.深度学习中的对抗攻击与防御[J].网络与信息安全学报,2020,6(5):36.
- [3] 姜妍,张立国.面向深度学习模型的对抗攻击与防御方法综述[J].计算机工程,2021,47(1):11.
- [4] WONG E, RICE L, KOLTER J Z. Fast is better than free:revisiting adversarial training[EB/OL].(2020-01-02)[2021-07-28]. https://arxiv.org/abs/2001.03994.
- [5] GOLDBLUM M, FOWL L, FEIZI S, et al. Adversarially robust distillation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York:AAAI,2020,34(4):3996.
- [6] WANG Y J, TAN Y A, ZHANG W J, et al. An adversarial attack on DNN-based black-box object detectors[J].Journal of Network and Computer Applications,2020,161:102634.
- [7] SHEN S W, JIN G Q, ZHANG Y D, et al. Ape-gan:adversarial perturbation elimination with gan[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway:IEEE,2019:3842.
- [8] SAMANGOUEI P, KABKAB M, CHELLAPPA R. Defense-gan:protecting classifiers against adversarial attacks using generative models[EB/OL].(2018-05-17)[2021-07-28]. https://arxiv.org/abs/1805.06605.
- [9] ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks[C]//International Conference on Machine Learning. Sydney:MLR,2017:214.
- [10] LIU S Q, SHAO M W, LIU X P. GAN-based classifier protection against adversarial attacks[J].Journal of Intelligent & Fuzzy Systems,2020,5(2):39.
- [11] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM:visual explanations from deep networks via gradient-based localization[J].International Journal of Computer Vision,2020,128:340.
- [12] BIANCO S, CELONA L, PICCOLI F, et al. High-resolution single image dehazing using encoder-decoder architecture[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway:IEEE,2019:1.
- [13] CASAS L, KLIMMEK A, NAVAB N, et al. Adversarial signal denoising with encoder-decoder networks[C]//28th European Signal Processing Conference. Piscataway:IEEE,2021:1467.
- [14] KANG L W, LIN C W, FU Y H. Automatic single-image-based rain streaks removal via image decomposition[J].IEEE Transactions on Image Processing,2012,21(4):1742.
- [15] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2017:1125.
- [16] PORAV H, BRULS T, NEWMAN P. I can see clearly now:image restoration via de-raining[C]//International Conference on Robotics and Automation. Piscataway:IEEE,2019:7090.
- [17] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE,2016:773.
- [18] HINTON G E. Learning multiple layers of representation[J].Trends in Cognitive Sciences,2007,11(10):430.
- [19] JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[C]//European Conference on Computer Vision. Berlin:Springer,2016:700.
- [20] KRIZHEVSKY A, HINTON G. Learning multiple layers of features from tiny images[J].Handbook of Systemic Autoimmune Diseases,2009,1(4):1.
- [21] RUSSAKOVSKY O, DENG J, SU H, et al. Imagenet large scale visual recognition challenge[J].International Journal of Computer Vision,2015,115(3):211.
- [22] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J].Communications of the ACM,2017,60(6):84.
- [23] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL].(2014-09-04)[2021-07-28]. https://arxiv.org/abs/1409.1556.
- [24] HORE A, ZIOU D. Image quality metrics:PSNR vs. SSIM[C]//20th International Conference on Pattern Recognition. Piscataway:IEEE,2010:2366.
- [25] ZHOU W, BOVIK A C, SHEIKH H R, et al. Image quality assessment:from error visibility to structural similarity[J].IEEE Transactions on Image Processing,2004,13(4):606.