 图 1 模型构建过程
Fig.1 Model building process
图 1 模型构建过程
Fig.1 Model building process
MA Wanqing,FENG Jun,YUAN Yuan.Study on performance prediction model of university students based on course association[J].Journal of Zhejiang University of Science and Technology,2024,36(03):205-217.[doi:10.3969/j.issn.1671-8798.2024.03.003]

对学生成绩进行预测与分析是帮助教育工作者发现学生的薄弱环节并提高学生成绩的重要手段。对学生成绩进行预测是数据挖掘在教育领域较为成熟的应用之一,通常预测的值是学生在某一课程中的课堂表现、获得的知识或考试成绩[1]。高校管理者采用了许多方法来监督和指导学生,但由于各种原因,要在早期发现问题并为学生提供他们所需的指导是很有挑战性的。随着信息技术的快速发展及数字化教育管理的广泛应用,海量的学生学习和行为数据及教师教学数据被有效记录和存储。如何有效地利用这些数据,通过一定的技术手段来分析评价学生的学习和教师的教学状况及成果,既提高教师教学、学校决策和管理的针对性和有效性,又向高校管理者提供及时的信息以提高教学过程的质量[2],是当下比较迫切的研究课题。学生成绩预测有助于教师动态掌握学情、发现困难学生、随时调整教学策略,从而降低学生考试不通过的概率,为优化教学过程提高教学质量提供数据保障和科学依据[3]。
Alsariera等[4]将用于评价学习表现的属性分为七类:人口统计因素、学术、内部评估、沟通、行为、心理和家庭/个人属性。其中,最常用的属性是学术因素中的出勤率、绩点(grade point average,GPA)和期末成绩[5],它们是最显著最直接的变量,并且对未来的教育和职业流动性具有切实的价值[6]。另一个常用的属性是学生的人口统计因素(包括性别、年龄和国籍),国内有不少研究者应用学生行为因素如校园一卡通数据预测学生成绩; 兰嘉枫[7]基于校园一卡通数据,对大一新生各项行为情况进行分析,对学生学习状况进行预测预警。孙美娟等[8]对校园一卡通数据和学生成绩数据进行关联分析,对学生进行“画像”,探究学生行为与成绩之间的关系。然而,课程因素如课程先后行关系、相关课程成绩等对学生成绩也有一定的影响。学生在以往学习的课程中积累的基础知识也要运用到之后的课程当中,因此不同课程之间是有关联的。本研究旨在挖掘出这种潜在关联,将其运用到成绩预测中,进而提高模型预测的精准度。
对于预测算法,刘晓云等[9]利用多元线性回归方法,根据某校计算机应用专业学生一年级的成绩预测其毕业成绩,获得较高的预测精度; 林婷婷[10]应用反向传播神经网络算法,估算某高中2016级高考平均成绩,所得预测结果最大绝对误差仅为2分; Naser等[11]利用人工神经网络(artificial neural network,ANN)模型,将学生高考分数、大学绩点、性别等因素作为指标,基于多层感知器拓扑模型训练数据,对学生成绩进行预测,准确率超过80%; Alsariera等[4]统计了2015—2022年使用最多的成绩预测机器学习算法,包括人工神经网络、决策树(decision tree,DT)、支持向量机(support vector machines,SVM)和线性回归(linear regression,LinR)等; 并且将各种算法采用的因素及预测精度进行对比,精度最高的为ANN和DT。
在课程关联方面,柯红香[12]利用自适应最小支持度关联规则算法,挖掘同一专业不同课程成绩的影响机制,为培养方案中课程开设顺序的优化提供依据; 袁明[13]利用改进频繁模式树(frequent pattern growth,FPGrowth)算法对上海某高校计算机基础课程成绩与证书成绩的相关性进行分析,发现了课程与证书成绩的相关性,为提高证书通过率提供了数据支持; Czibula等[14]提出了一种新的分类模型SPRAR(students performance prediction using relational association rules),利用关系关联规则(relational association rules,RAR)预测学生在某一学科的最终成绩,并取得较好的效果; 何楚等[15]利用谱聚类算法对课程进行聚类,将课程分为通识、基础与专业基础、专业方向、实践教学四类; 陈波[16]通过对宁波城市职业技术学院的30门在线开放课程进行聚类分析,将其按照运行效果分为四类,对在线课程的运行管理提出合理化建议; 有不少研究者采用K均值(K-means)聚类算法来进行教育数据挖掘,而K-means在聚类前要事先确定聚类的数目,但在实际应用中,尤其是数据庞大的情况下,我们很难在试验前确定合适的聚类数目; Kohonen[17]基于生物的“侧抑制”现象提出了自组织映射网络(self-organizing map,SOM),利用其自组织训练的特性,对输入模式进行分类; Delgado等[18]使用SOM模型对拉里奥哈国际大学2015—2019年注册的1 709 189名在线学生进行聚类,结果表明,特定的集群与大学的录取平均情况有关,用户互动和更高的表现之间有明显的关系。
综上所述,以往的学生预测模型仅依据一些常见因素对学生成绩进行预测。对此,本研究尝试构建一种基于课程关联的学生成绩预测模型(students performance prediction using course association,SPCA),利用聚类算法和关联规则挖掘算法,重点考虑不同课程之间的影响,包括课程的先后行关系、课程知识的影响关系等,以进一步挖掘课程之间的关联,不断提高成绩预测的精度。
1 研究方法1.1 试验设计1.1.1 数据选取本研究试验数据来自某高校教务管理系统,研究对象是该校2018—2020级工业工程专业134名学生所修的“智能制造导论”这门课的成绩,其中2018级41人、2019级54人、2020级39人。选取的指标包括学生的人口统计学因素、学术因素和行为因素三类数据,相关属性见表1。
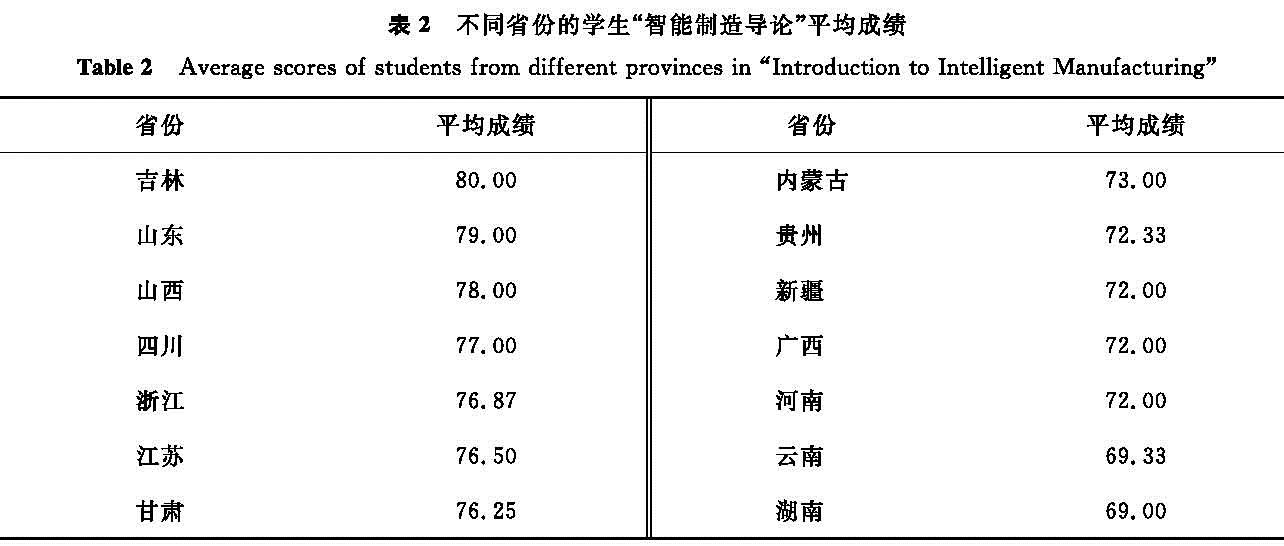
1.1.1.1 人口统计学因素由于不同省份教育水平的不同,学生的学习能力也有所不同,因此学生成绩与省份有一定关系。不同省份的学生“智能制造导论”平均成绩见表2。由表2可知,不同省份的学生平均成绩是有所差异的,如来自吉林省的学生平均成绩最高,为80分; 来自云南省的学生平均成绩最低,为69.33分。
可见,来源省份的不同会对学生的成绩造成一定影响。
表1 相关属性
Table 1 Related attribute
表2 不同省份的学生“智能制造导论”平均成绩
Table 2 Average scores of students from different provinces in “Introduction to Intelligent Manufacturing”
1.1.1.2 学术因素学术因素主要选取的是相关课程期末成绩和平时成绩。由于校公共选修课在不同学生之间差异较大,数据不完整,故排除。此外,还排除了一些选课人数较少的选修课,最终选取了29门课程的期末成绩和平时成绩用于本次研究。
1.1.1.3 行为因素学生的成绩与课堂中的表现、生活学习行为习惯、学习能力等也有紧密关联。于是我们搜集了同一批学生的一卡通数据包括学生图书馆进馆数据、借书数据、食堂消费数据等。
1.1.2 模型构建课程自身、课程与课程之间、课程设置与课程成绩之间均存在着一定的关联。数据集的高维度和大量元素及提出的目标要求使用数据挖掘工具,从学生成绩数据中挖掘课程的潜在关联。为了排除无关因素的干扰,首先作如下假设:1)每学期平时成绩所占比重不变,试卷难度大致相同; 2)每个学生的考试环境相同; 3)教师的评分标准基本上相同。
模型构建过程如图1所示,可分为以下几个步骤:
1)对成绩数据进行初步分析,观察其分布特征和变化趋势。选取“马克思主义基本原理”“毛泽东思想和中国特色社会主义理论体系概论”“概率论与数理统计”“线性代数”等课程,比较成绩的变化趋势,观察其相似性及相关性。
2)对29门课程进行课程聚类,将其分为三类,并根据每类课程的特点进行命名。
3)关联规则挖掘。具体的关联关系通过关联规则算法得出,推断出课程成绩之间的关系,进而得出课程之间的内在联系。例如,“管理学原理B”与“经济法学B”之间的关联度为1.29,支持度为0.20,置信度为0.70,在这一条规则中,“管理学原理”为前置课程,“经济法”为后置课程。由此可以得出结论,这两门课程的知识体系之间可能存在一定的内在联系,学习“管理学原理”可以提高“经济法”的学习效果。
基于课程关联的成绩预测模型如图2所示。三种颜色分别代表三种课程类别,假设要预测课程A的成绩,筛选与课程A属于同一聚类类别、开设时间在课程A之前且在关联规则中属于课程A前项的课程作为部分影响因素,即课程D、课程E的成绩,并结合食堂消费数据、图书馆记录数据和入学投档数据进行成绩预测。

图1 模型构建过程
Fig.1 Model building process
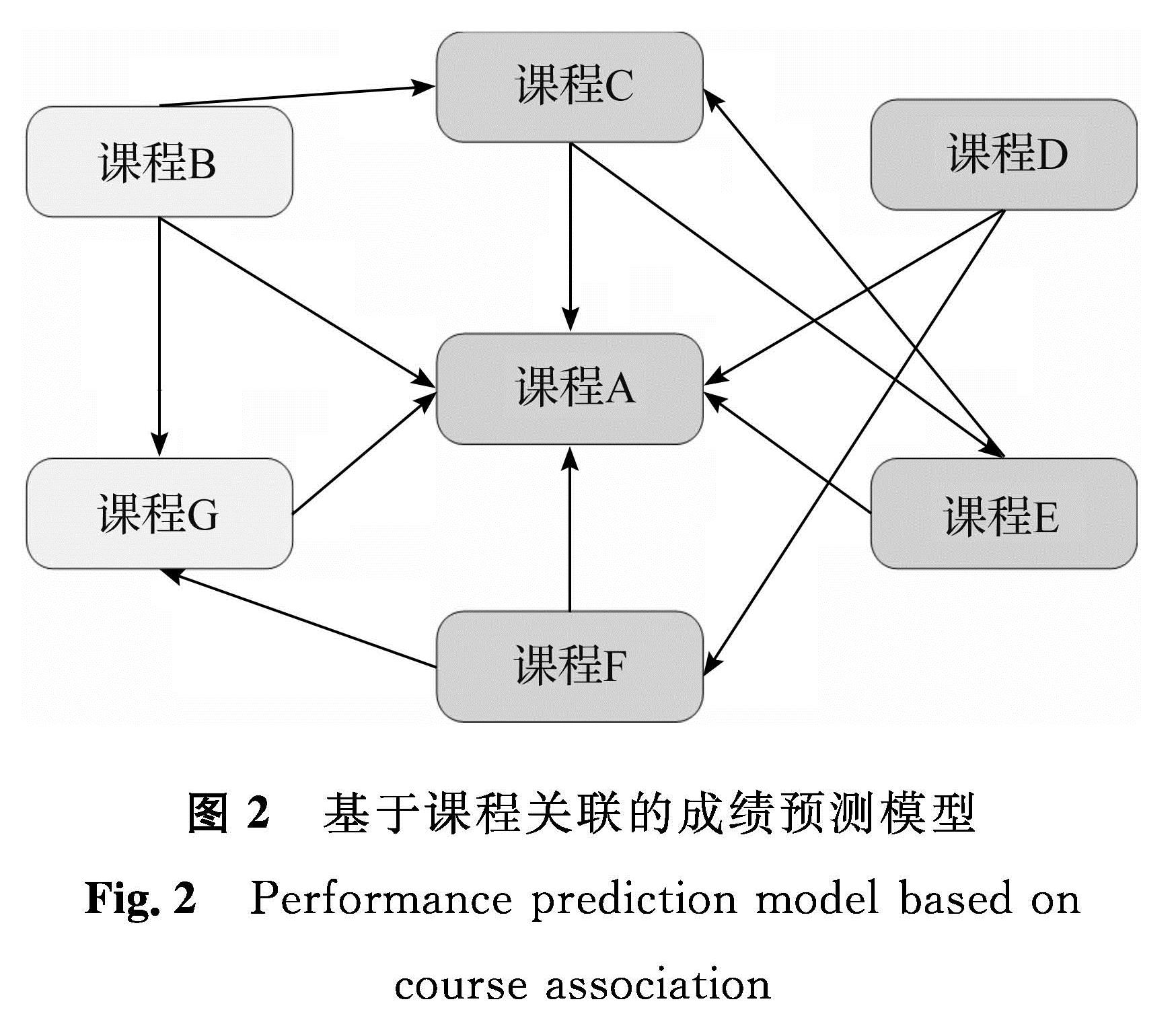
图2 基于课程关联的成绩预测模型
Fig.2 Performance prediction model based on course association
1.2 相关算法1.2.1 SOM神经网络
考虑到各科成绩间的相互影响和不同类别的线性可分性,采用统计学中的聚类分析方法对课程进行分类不太适宜。Jiménez等[19]的研究表明,可以使用人工神经网络有效处理教育和心理测量数据。SOM算法是一种神经网络算法,是一种无监督的降维算法,通过将高维数据投影到节点平面上并进行自组织,实现了高维数据的可视化和聚类。相比其他聚类算法,SOM不需预设分类数目,可自行发掘数据潜在规律,具有自适应性。SOM由输入层和竞争层合成。竞争层会对输入向量进行竞争,相似度越高的输入向量神经元竞争力越强,最终只有一个神经元获胜。获胜神经元的权重向量会趋近于输入向量,促使具有相似特征的输入向量聚集[20]。如此反复,每个获胜神经元就会变得只跟特定的一个类别匹配,这样就实现了数据点的聚类。
1.2.2 Apriori关联规则算法在众多关联规则的算法中,Apriori算法是最为经典的一种,后来的许多算法都是Apriori算法的延伸和改进。1994年,Agrawal等[21]提出了Apriori算法,用于挖掘频繁项集和布尔关联规则。该算法基于先验原理,即频繁项集的子集也一定是频繁的; 反之,非频繁项集的所有超集也是非频繁的。探索过程包括以下步骤:1)浏览数据库,汇总每个项集的数量; 2)将每个项集的支持度与最小支持度对比,筛选出大于或等于最小支持度的项集,形成频繁1-项集的集合L1; 3)借助L1形成频繁2-项集的集合L2,再利用L2形成L3; 4)最后重复上述步骤,直到得出最大频繁K-项集的集合Lk为止。找到关联规则涉及三个步骤,即首先从数据集中提取频繁项集,然后从这些频繁项生成规则,最后根据提升度筛选有价值的强关联规则。
1.2.3 决策树决策树具有树形结构,包含根节点、内部节点和叶子结点三个元素。按照决策树的树状结构对数据集中的不同取值进行测试,由根节点到叶子节点的一条路径就代表一种决策,决策树因此得名。决策树分类器与其他分类方法相比,速度相对较快,并且易于理解。像神经网络这样的方法即使是小数据集也需要非常长的训练时间; 而决策树可以转换为简单易理解的分类规则。此外,与其他分类方法相比,树形分类有时会获得更高的精度[22]。决策树分类算法一般分为两步:首先模型利用训练集,从根节点开始,从上向下来判断,形成决策树,建立模型; 然后利用建立好的样本进行分类。生成决策树所用的规则包括信息增益、基尼系数和信息增益比。DT可以处理两种形式的数据,并且在海量数据集中表现良好,变量之间的关系也易于理解[23]。GPA、成绩和人口统计学因素是在大多数使用DT算法中预测学生成绩准确性最高的因素。基于以上优点,本研究采用决策树算法来建立成绩预测模型。
2 课程关联分析2.1 数据预处理2.1.1 数据清洗将敏感信息去除,删除不相关数据,然后将类似课程合并,采用求平均值的方法进行取值(四舍五入取小数点后一位)。对清洗过程中发现的缺失数据,如果某一学生缺失的成绩较多,那么将这一条记录作删除处理; 如果仅缺失一两门课程成绩,则将缺失的成绩填充为该门课的平均分。
为了避免量纲不同对模型精确度的影响,将课程成绩、平时成绩进行标准化处理,将其数值转化为0~1。
2.1.2 数据转换在经典的Apriori算法中,事务数据库通常以横向结构存储数据,而成绩数据库多采用纵向结构。纵向结构的学生成绩数据库中,每个学生存在多条记录,每条记录包含丰富的信息。
为适应Apriori算法,需调整数据库结构,将其转换成适合挖掘的数据。另外,由于课程的计分规则不同,有些课程成绩为百分制,有些课程成绩为等级制,在进行课程聚类时,需要将等级转换为百分制数值。具体规则为:优秀为95分; 良好为85分; 中等为75分; 及格为65分; 不及格为0分。又由于Apriori算法仅支持分类型数据的关联分析,所以学生成绩需进行离散化处理,将学生成绩分为A、B、C、D四个等级,具体规则为:90~100分,A; 80~<90分,B; 70~<80分,C; 60~<70分,D; <60分,E。转换后的成绩数据举例见表3。
表3 转换后的成绩数据
Table 3 Score data after conversion

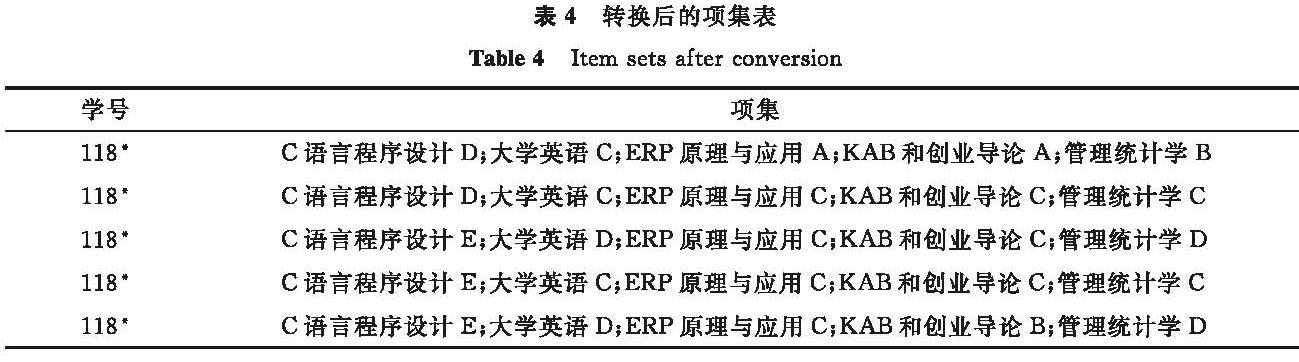
进行关联规则挖掘还需将这些“属性-表”对连接起来,构成一个项,项属性是由“属性-值”对构成的,如“课程名称-成绩等级”。转换后的项集表见表4。表4中每一条记录代表一个事务,旨在探讨多个“属性-值”对间的关联。
表4 转换后的项集表
Table 4 Item sets after conversion
2.2 课程相关性检验
从以往经验来看,若两门课程的性质和内容相似,那么通过课程成绩便可以验证其相似性。以“线性代数”和“概率论与数理统计”为例,这两门课程均为数学类课程,涉及计算、理解、逻辑等相关知识。同一学生如果具备相关能力,那么在这两门课程的考试中取得的分数应该相差不大。成绩走势图见图3,从图中可以看到成绩的走势极为相似,直观地反映出了这两门课程确是有一定关联的。“马克思主义基本原理”与“毛泽东思想和中国特色社会主义理论体系概论”这两门课程同理,两门课程成绩走势差异较小,并且大部分成绩集中于70~90分。
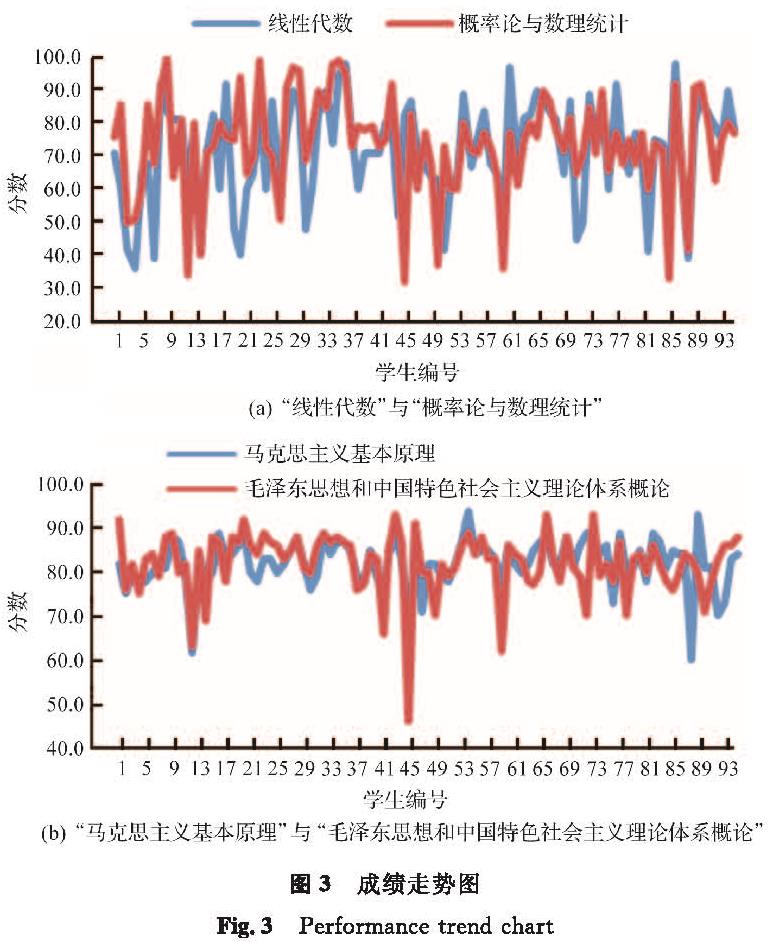
图3 成绩走势图
Fig.3 Performance trend chart
衡量两种事物间的相关密切程度,可以用相关性分析来实现,即计算相关系数。采用皮尔森(Pearson)相关系数法来得出29门课程的相关系数矩阵,每门课程用对应的l1-l29表示。相关性热力图见图4,图中相关系数的正负用不同颜色表示,红色代表正相关,蓝色代表负相关。相关系数的大小可以用颜色深浅表示,颜色越深,相关性越强,白色代表低相关。由图4可知,大部分课程成绩之间为正相关,仅有几门课程成绩呈负相关,并且大部分课程成绩的相关系数绝对值集中在0.3~0.8,这表示课程成绩间具有一定程度的相关性。
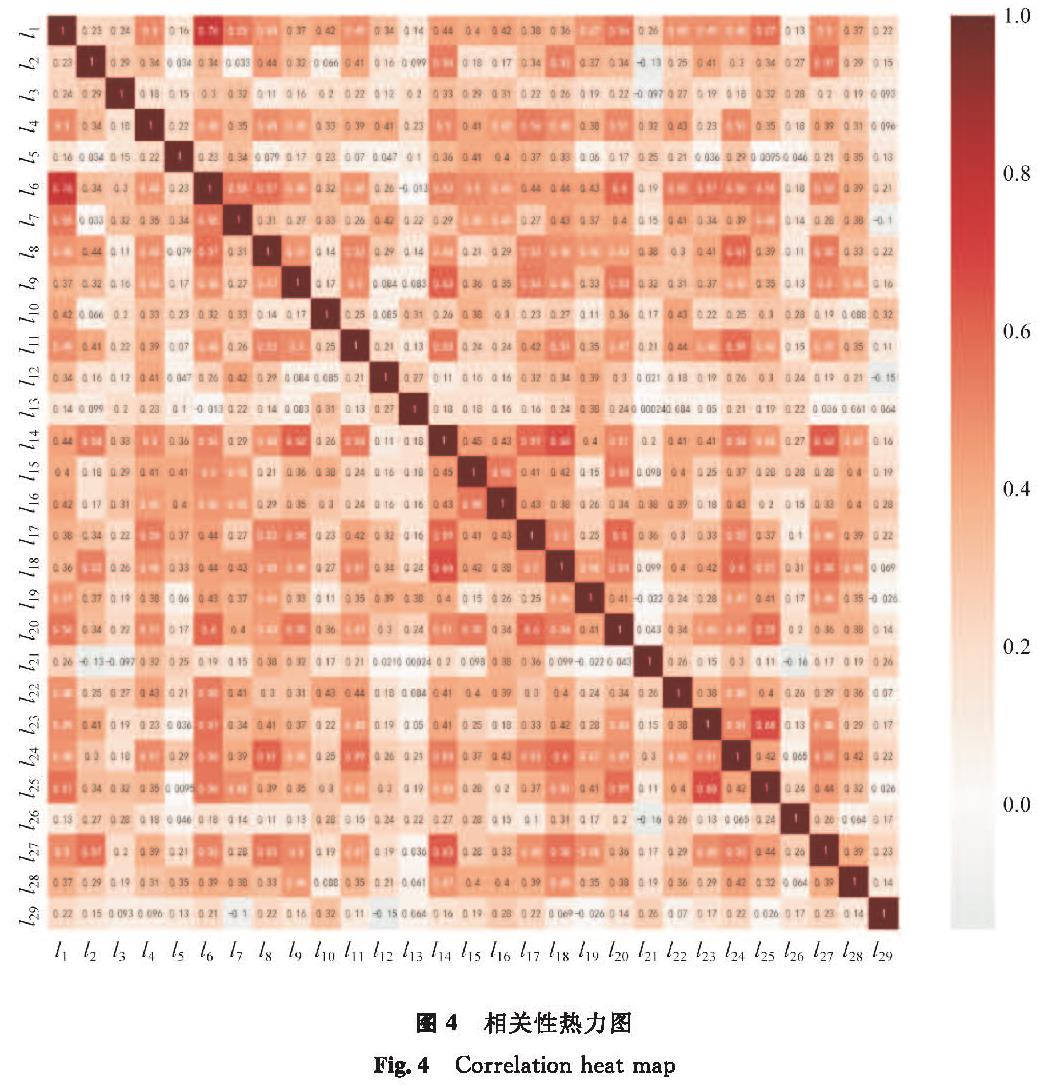
图4 相关性热力图
Fig.4 Correlation heat map
2.3 课程聚类分析
为了排除其他因素的影响,保证结果的可靠性,我们将学生成绩进行标准化处理。由于本次研究中课程数目较多,聚类的维度较高,因此选用SOM神经网络进行课程聚类。利用Python进行SOM神经网络的构建,将标准化的29门课程成绩作为该网络的输入变量。为了取量化误差的最小值,经多次试验观察结果,设置本次试验的最大迭代次数为160。然后确定聚类的数目,本研究采用的评价指标为轮廓系数。轮廓系数ySC(i)是类的密集程度与分散程度的评价指标,形式如下:

式(1)中:i为样本,i=1,2,…,29; La(i)、Lb(i)均代表平均距离; La(i)为样本i到同一簇内其他样本的平均距离; Lb(i)为样本i到其他某簇的所有样本的平均距离。
将原始数据分别聚成二类、三类、四类、五类、六类、七类,观察每一次轮廓系数的大小。不同聚类数目的轮廓系数如图5所示。对于课程样本数量,过于宽泛或过于详细的分类都不适合,因此不考虑分成两类。而由图5可知,除两类以外,当聚类数目为3时,轮廓系数最大。故输出层的神经元数量为3,即将其聚成三类。课程聚类结果见表5。由表5可知,聚类结果与实际情况较为相符。参考文献[20]进行类别命名,其中第一类的四门课程均需要一定的逻辑思维能力和计算能力,如“高等数学”“线性代数”,因此归为数学计算类。第二类课程大多数为专业基础课,如“KAB和创业基础”“物流工程”“智能制造导论”,还有一些通识课,如“中国近代史纲要”“马克思主义基本原理”等,因此将其归为通识与专业基础类。第三类课程大部分需要实践能力和动手能力,如“工程图学”“机械设计基础”等,需要将所学知识应用到实际中,因此归为实践应用类。
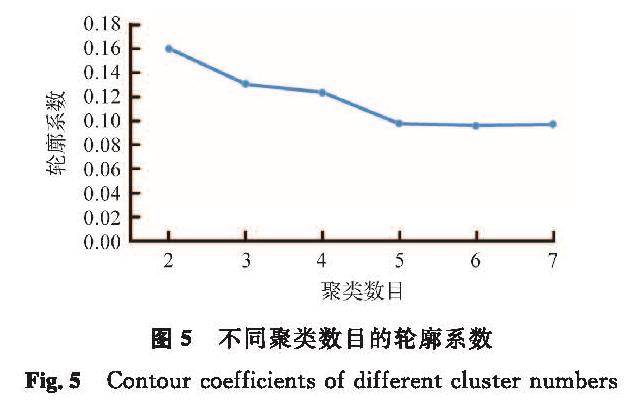
图5 不同聚类数目的轮廓系数
Fig.5 Contour coefficients of different cluster numbers
表5 课程聚类结果
Table 5 Results of course clustering

2.4 课程关联规则挖掘
采用Apriori算法挖掘关联规则。先确定最合适的最小支持度和最小置信度。采用试探法,将最小支持度和最小置信度由0.9开始依次减小0.1,分别观察每次得到的关联规则数量。当最小支持度超过0.5,或最小置信度超过0.8时,关联规则数量为0; 而当阈值过小时,挖掘到的规则数量过多,达到3 000条以上。因此为了避免获得的关联规则数量过少,以致损失一些有意义的规则,阈值不宜设置过大; 而阈值过小也会导致获得关联规则数量过多,造成冗余。因此,需选择合适的阈值,并且利用最小提升度进行筛选。最终设最小支持度为0.2,最小置信度为0.6,最小提升度为1,共得出1 079条关联规则,部分强关联规则见表6。
表6 部分强关联规则
Table 6 Part of strong association rules
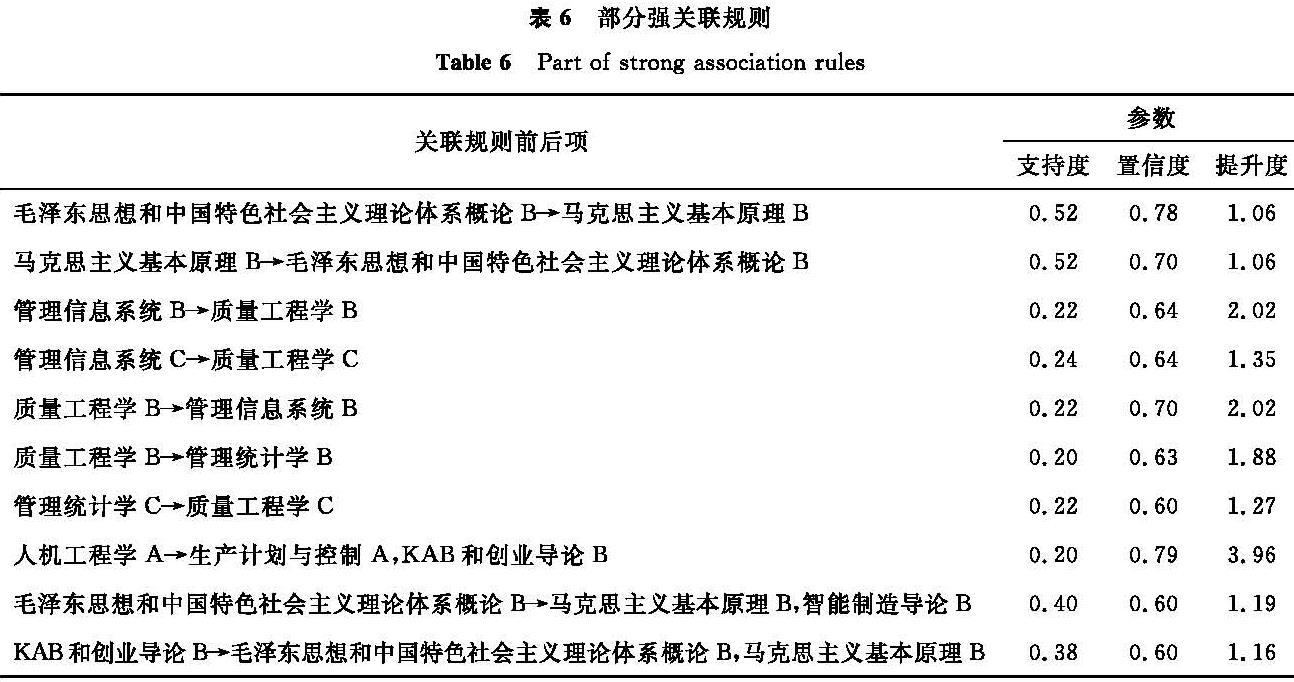
由表6可知:得到的关联规则结果与之前的假设大致相似,“毛泽东思想和中国特色社会主义理论体系概论”与“马克思主义基本原理”之间确实存在一定的联系,二者的课程成绩互相影响,并且由之前描述统计中得到的结果可知,二者相关系数为0.76,并且以上两条规则的置信度都达到了0.70以上; “质量工程学”与“管理信息系统”成绩紧密相连,两门课程中任意一门课程成绩的高低均会影响另一门课程,并且两门课程无论是哪一门作为前置课程,提升度均相近。
绘制部分课程关联图见图6。课程关联在一定程度上量化了一门课程对另一门课程的影响程度,挖掘两门课程之间的内在关联,并且由关联规则的前后置关系,可以得出课程设置的先后顺序,便于学生在学习过程中打好基础,也有利于管理部门对培养计划进行优化更新,设置更为合理的课程体系。

图6 课程关联图
Fig.6 Course association diagram
3 成绩预测3.1 训练模型
以“智能制造导论”为后置,得到的部分强关联规则见表7。
表7 以“智能制造导论”为后置的部分强关联规则
Table 7 Partial strong association rules based on “Introduction to Intelligent Manufacturing”
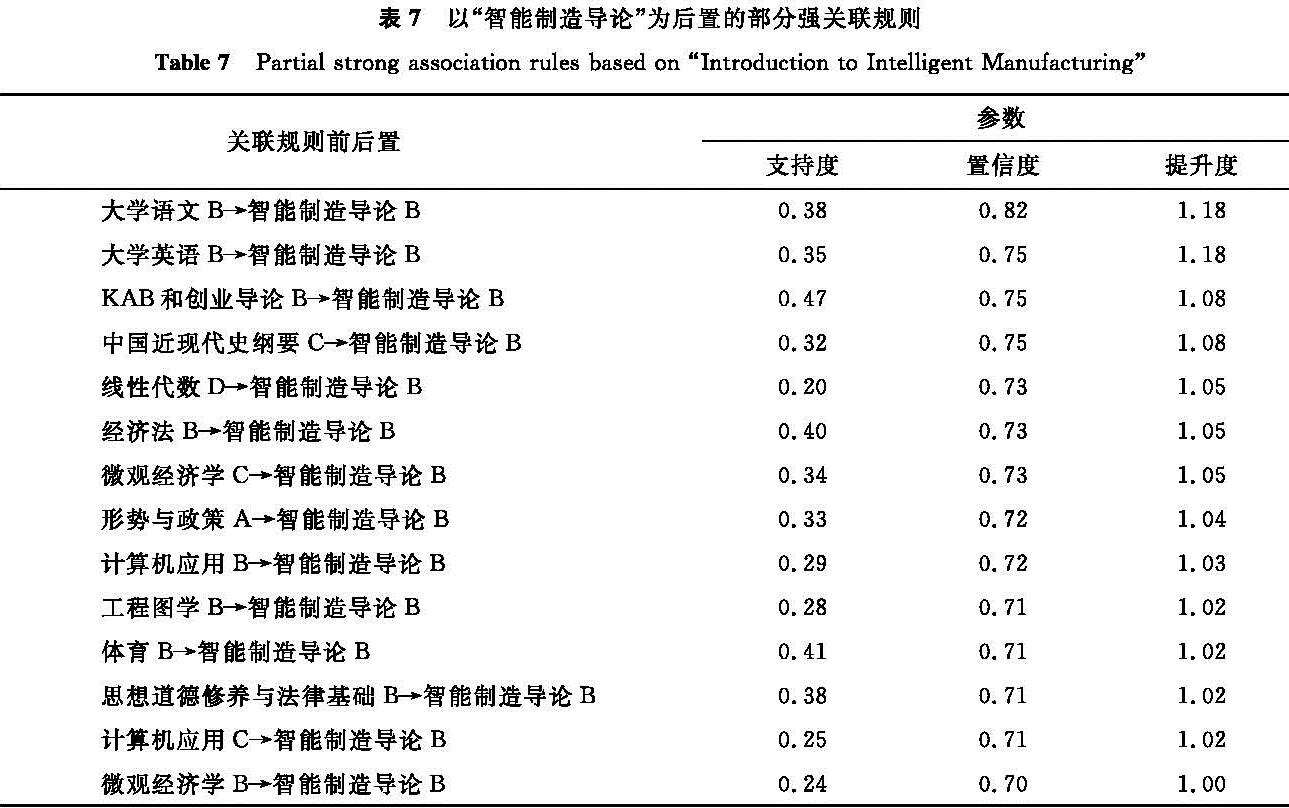
由Apriori算法得到的强关联规则,只要满足前置课程开设学期小于后置课程开设学期,即可认为有效。经查阅培养计划,以上关联规则前置中的课程均开设在“智能制造导论”之前,因此均满足有效条件。又由表5中聚类结果得知,以上课程中与“智能制造导论”属于同一类的课程有“KAB和创业基础”“大学英语”“大学语文”“经济法”“思想道德修养与法律基础”“体育”“形势与政策”“中国近现代史纲要”这8门课程。将这8门课程成绩(x1~x8)作为部分自变量,结合校园一卡通数据和入学投档数据建立预测模型,包括图书借阅、图书馆进馆、省份和消费,并以Pearson相关系数作为指标,计算各属性的特征重要性,如图7所示。

图7 特征重要性
Fig.7 Importance of features
数据准备完成后,得到了用于进行学生成绩预测的数据集。为了便于参数的调整,经多次试验观察精确度,最终将其按8:2的比例分割成训练集和测试集,按照表1进行特征输入,使用决策树算法训练模型。使用GridSearchCV函数进行多参数调优,利用十折交叉验证法计算不同参数下的精确度,即将数据集分为数量相等的10份,每次进行分类时,选择其中一份作为测试集,剩下的9份作为训练集; 这样重复10次,每一次训练集数据和测试集数据都相互独立,并且完全覆盖整个数据集,最终确定模型参数见表8。经参数调优后,生成的学生成绩预测决策树模型如图8所示,模型在测试集上的精确率为90.2%,准确度为88.9%,验证了模型的有效性。
表8 模型参数表
Table 8 Model parameters

图8 学生成绩预测决策树模型
Fig.8 Decision tree model of student performance prediction
3.2 结果对比分析
为了验证SPCA模型是否比以往成绩预测模型有更高的精确率,我们将其与传统模型进行对比。由于传统模型未涉及课程因素,因此我们将模型中相关课程因素剔除,仅利用平时成绩、高考成绩及食堂消费、图书馆进馆、图书借阅数据,并利用相同参数进行成绩预测,ytest、ypred分别代表实际成绩和预测成绩,预测结果对比折线图见图9。
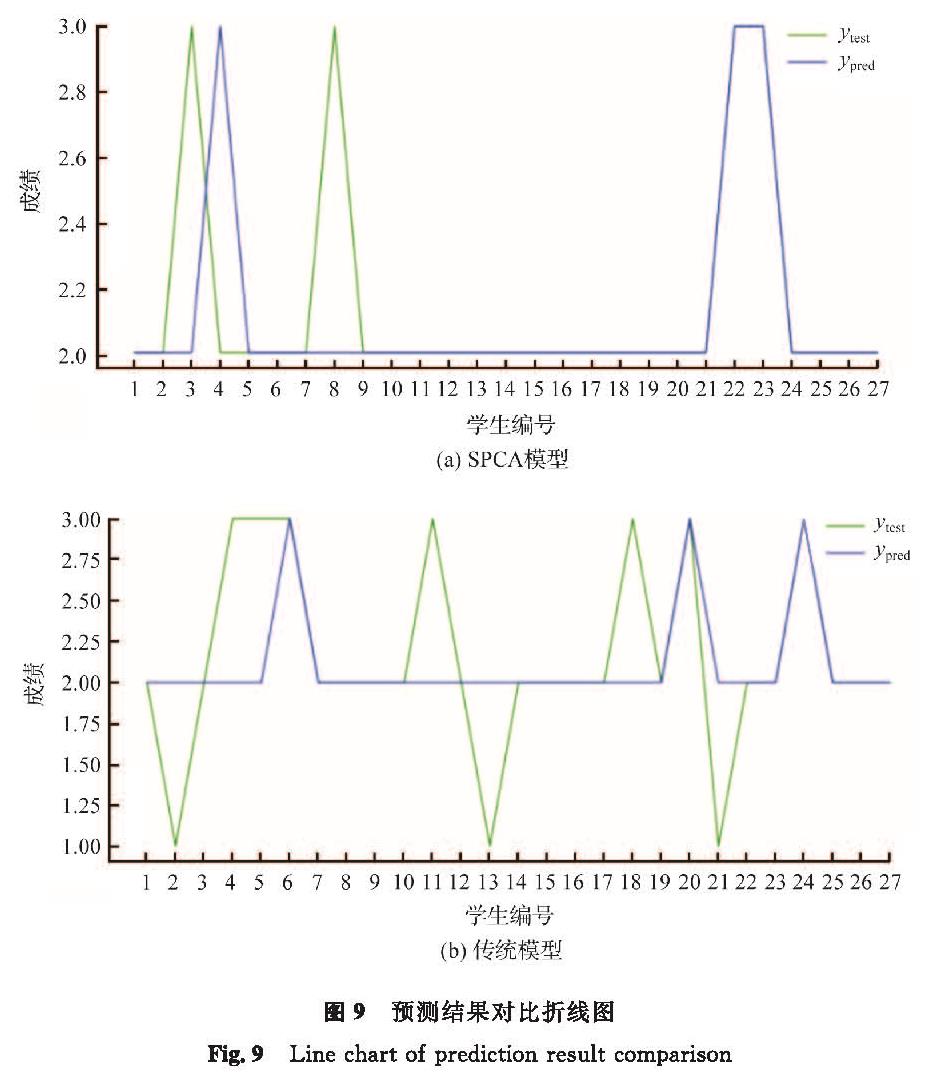
图9 预测结果对比折线图
Fig.9 Line chart of prediction result comparison
评估分类算法优劣常用的指标有精确率、召回率、准确率、F1分数等。本次试验选择加权平均法来计算各项指标,获得模型的训练效果指标见表9。由表9可知,传统模型的各个指标均低于SPCA模型,拟合效果均没有SPCA模型好,这进一步验证了SPCA模型的优越性。
表9 模型训练效果指标
Table 9 Model training effect index%

4 结 语
本研究将课程关联引入成绩预测模型中,以真实数据为研究对象,建立成绩预测模型。预测精确率为90.2%、准确率为88.9%,结果表明该模型及其构建过程是有效的。与传统的成绩预测研究相比,本研究提出的模型融合了多重课程关联,为后续解读预测结果提供了更多角度。从学生角度来看,可根据预测结果发现潜在的学业风险,如在前一学期有课程未取得理想的成绩甚至考试不通过,那么可预测到下一学期开展的相关课程也有不及格的可能,因而应该加强该课程的学习,避免考试不通过。从教师角度来看,可根据成绩预测的结果,合理调整授课进度和内容,因材施教,促进学生对知识的理解和吸收。如果一名学生在某一学科出现了不合格现象,教师可以利用模型预测结果,重点关注后续课程中与该学科相关联的学科学习情况。从管理部门角度来看,可根据成绩预测结果及时发现困难学生,进行成绩预警。本研究提出的方法可以在早期发现学习困难学生,具有一定的前瞻性和针对性。通过课程间关联模型的建立和关联分析,为制定合理的培养方案、优化课程体系提供了新的思路和强有力的依据。虽然目前研究取得了初步的成果,但还存在着一些需要完善的内容。首先,当前选取样本量较少,且由于教师评分的主观性,可能造成不同课程的成绩不具有统一标准,因此产生误差; 其次,目前构建的指标体系尚不完善,仅包括客观因素。下一步可以将主观因素引入模型中,选取不同专业的相似课程进行对比试验,同时规范教师的评分标准,建立更丰富、更完善、更科学的指标体系。
- [1] ROMERO C, VENTURA S. Educational data mining:a review of the state of the art[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C(Applications and Reviews),2010,40(6):601.
- [2] 黎龙珍.基于决策树算法的在线学习成绩预测[J].信息技术与信息化,2021(1):130.
- [3] 班文静,姜强,赵蔚.基于多算法融合的在线学习成绩精准预测研究[J].现代远距离教育,2022(3):37.
- [4] ALSARIERA Y A, BAASHAR Y, ALKAWSI G, et al. Assessment and evaluation of different machine learning algorithms for predicting student performance[J]. Computational Intelligence and Neuroscience,2022,2022:1.
- [5] SHAHIRI A M, HUSAIN W,RASHID N A. A review on predicting student's performance using data mining techniques[J]. Procedia Computer Science,2015,72:414.
- [6] BINMAT U, BUNIYAMIN N, Arsad P M, et al. An overview of using academic analytics to predict and improve students' achievement:a proposed proactive intelligent intervention[C]// IEEE 5th Conference on Engineering Education.Selangor:IEEE,2013:126.
- [7] 兰嘉枫.基于一卡通数据的大一新生成绩预测预警[D].武汉:华中师范大学,2022.
- [8] 孙美娟,张俊,年梅.基于校园一卡通和成绩数据的学生画像研究[J].计算机时代,2023(8):20.
- [9] 刘晓云,刘鸿雁,李劲松.基于多元线性回归的学生成绩预测研究[J].计算机技术与发展,2022,32(3):203.
- [10] 林婷婷.基于BP神经网络算法的成绩预测模型研究[J].计算技术与自动化,2022,41(1):79.
- [11] NASER S A, ZAQOUT I, GHOSH M A, et al. Predicting student performance using artificial neural network:in the faculty of engineering and information technology[J]. International Journal of Hybrid Information Technology,2015,8(2):221.
- [12] 柯红香.最小支持度挖掘算法在高校学生成绩关联规则的应用[J].长江工程职业技术学院学报,2023,40(2):69.
- [13] 袁明.改进FP-Growth算法在考证成绩分析中的应用[J].信息技术与信息化,2021(6):53.
- [14] CZIBULA G, MIHAI A, CRIVEI L M. SPRAR:a novel relational association rule mining classification model applied for academic performance prediction[J]. Procedia Computer Science,2019,159:20.
- [15] 何楚,宋健,卓桐.基于频繁模式谱聚类的课程关联分类模型和学生成绩预测算法研究[J].计算机应用研究,2015,32(10):2930.
- [16] 陈波.职业院校在线开放课程运行效果聚类分析[J].中国成人教育,2019(4):48.
- [17] KOHONEN T. The self-organizing map[J]. Proceedings of the IEEE,1990,78(9):1464.
- [18] DELGADO S, MORÁN F, SAN JOSÉ J C, et al. Analysis of students' behavior through user clustering in online learning settings, based on self organizing maps neural networks[J]. IEEE Access,2021,9:132592.
- [19] JIMÉNEZ R, GERVILLA E, SESÉ A, et al. Dimensionality reduction in data mining using artificial neural networks[J]. Methodology Europtan Journal of Research Methods for the Behavioral and Social Sciences,2009,5(1):26.
- [20] 赵翠翠,尹春华.K-means和SOM在商品评论中的情感词聚类对比[J].北京信息科技大学学报(自然科学版),2020,35(1):23.
- [21] AGRAWAL R, SRIKANT R. Fast algorithms for mining association rules[C]//International Conference on Very Large Data Bases. San Francisco:VLDB,1994:487.
- [22] MEHTA M, AGRAWAL R, RISSANEN J. SLIQ:a fast scalable classifier for data mining[C]//International Conference on Extending Database Technology. Avignon:Springer Berlin Heidelberg,1996:18.
- [23] MAYILVAGANAN M, KALPANADEVI D. Comparison of classification techniques for predicting the cognitive skill of students in education environment[C]//2014 IEEE International Conference on Computational Intelligence and Computing Research. Coimbatore:IEEE,2014:1.