 图 1 整体训练过程
Fig.1 Overall training process
图 1 整体训练过程
Fig.1 Overall training process
ZHANG Yuming,ZHOU Wujie,YE L.Indoor scene parsing method based on self-distillation and dual-mode[J].Journal of Zhejiang University of Science and Technology,2024,36(03):218-227270.[doi:10.3969/j.issn.1671-8798.2024.03.004]

随着生产生活水平的提高,室内智能机器人作为智能家居领域中不可或缺的构成部分正处于迅猛发展中。智能机器人取代人类从事简单劳作的趋势越来越明显,比如智能送餐、智能陪护等,而其用到的关键技术之一就是计算机视觉。近年来,基于卷积神经网络[1](convolutional neural network, CNN)的深度神经网络以其良好的场景分析性能在计算机视觉任务中得到广泛的应用。
作为计算机视觉的一个重要分支,室内场景解析近年来也发展迅猛。场景解析是将图像中每个像素点按照不同物体类别进行分类,最终获得整个图像分割图。基于全连接神经网络[2](fully connected network, FCN)的框架在语义分割领域表现出色,编码器-解码器结构[3]的出现让高分辨率图像能获取高层的语义信息,从而实现更准确的像素级预测。虽然上述方法都取得了较好的效果,但单一的三色(red green blue, RGB)图像在理解场景的三维结构方面还有待提高。此外,单一的RGB图像对光照变化非常敏感,在不同的光照条件下,同一物体的颜色可能会发生变化,从而影响模型对物体的识别和分类。深度图包含丰富的深度信息和边界信息,这些信息可以为RGB图像提供重要的补充。为了充分利用深度特征中的信息,一些研究者探索了如何有效地挖掘和利用深度特征中的几何位置信息。Hazirbas等[4-6]将深度特征和RGB特征作为互补信息源进行简单融合来丰富整体的信息输入。Jiang等[7]和Chen等[8]分别提出了一种残差编码解码网络(residual encoder-decoder network, RedNet)和一种空间引导网络(spatial guided network, SGNet),从残差连接和空间信息两个角度提升了模型准确度。Cao等[9]提出了一种形状卷积层(shape convolution, ShapeConv),用于对深度特征进行形状分量和基分量处理。Zhou等[10]则提出了一种后渐进制导融合和深度增强网络(progressive guided fusion and depth enhancement network, PGDENet),通过特定模块增强对深度信息的关注度而提升性能。然而,在深度学习模型中,模型所存储的信息量过大,会带来信息过载的问题。引入注意力机制,可以在众多的输入信息中关注更为重要的特征信息并赋予其更高权重,削弱或过滤掉无关信息,从而有助于解决信息过载问题。Chen等[11-14]通过基于分离融合门控(separation-and-aggregation gate, SA-Gate)、双边跨模式互动网络(bilateral cross-modal interaction network, BCINet)等方法,有效地将不同模态的特征进行分离和融合,从而提高了解析的准确性。
尽管上述研究在室内场景解析领域取得了显著成效,但多数研究者在进行RGB和深度特征融合时仍存在未充分利用两种模态特征的问题,同时不同特征层之间的融合不足也会导致模型预测结果出现偏差。针对以上问题,本研究提出了一种用于室内场景解析的基于自蒸馏[15-17]和双模态的自蒸馏多级级联网络(self-distillation multi-stage cascade network, SMCNet),将分割变换器[18](segmentation transformer, SegFormer)获得的四组特征输入特征增强模块(feature enhancement module, FEM)进行特征增强和分组融合,再经过自蒸馏监督模块(self-distillation supervision module, SSM)和多级级联监督模块(multi-stage cascaded supervision module, MCSM)的双重监督,获得更精确的室内场景解析结果。
1 SMCNet模型1.1 整体训练过程传统的深度学习网络训练过程相对简单,仅使用数据的真实值对模型的预测结果进行监督,这可能导致模型精度下降。为了解决这一问题,本研究提出的方法采用了自蒸馏监督和多级级联监督两种方法:自蒸馏监督在特征与特征之间进行监督; 而多级级联监督则在真实值与预测值之间进行监督。通过计算预测图在不同评估指标上的表现,可以获得最终评价结果。整体训练过程如图1所示。
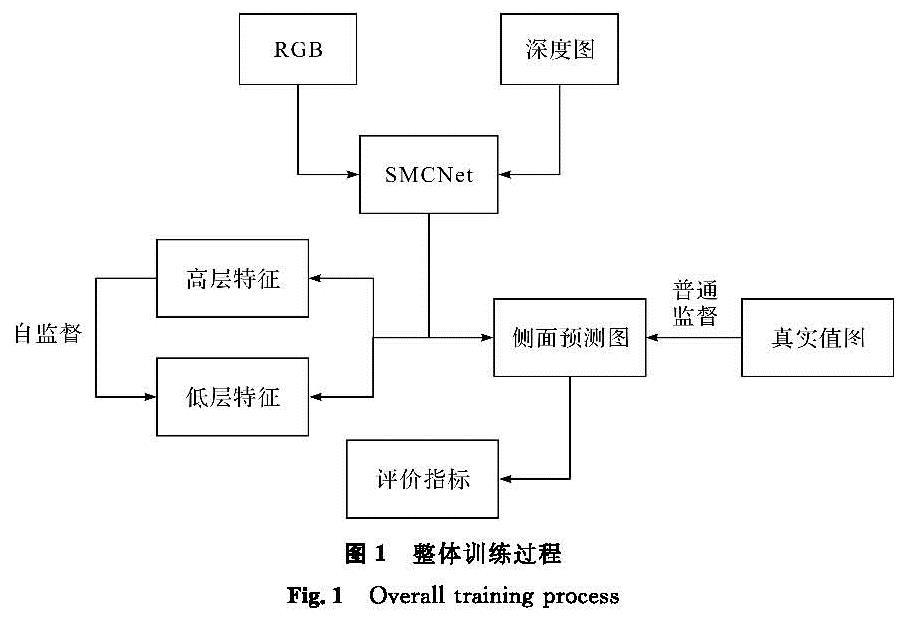
图1 整体训练过程
Fig.1 Overall training process
1.2 整体模型结构
整体模型结构如图2所示,SMCNet主要遵循编码器解码器框架。在编码器部分,首先使用分割变换器对输入数据进行处理,以提取分级特征,从而获得不同分辨率下的多通道抽象特征表示,分别将其命名为Ri和Di,其中i为特征所处的层级,i=1,2,3,4; 然后将4组特征分别传入特征增强模块,以增强特征中的有价值信息; 最后再将增强后的4组特征传入融合模块,以实现充分融合,从而尽可能多地获取彩色和空间信息。融合后的特征(F1,F2,F3,F4)被传入两个不同模块:一是自蒸馏监督模块,该模块负责将高层中有价值的信息传递到低层中,以实现跨层信息的充分交融; 二是多级级联监督模块,该模块执行跨层采样融合操作,以生成最终的预测图。通过这种方式,SMCNet能有效地利用RGB和深度特征,并充分融合不同尺度的特征信息,从而在室内场景解析任务中获得更精确的预测结果。
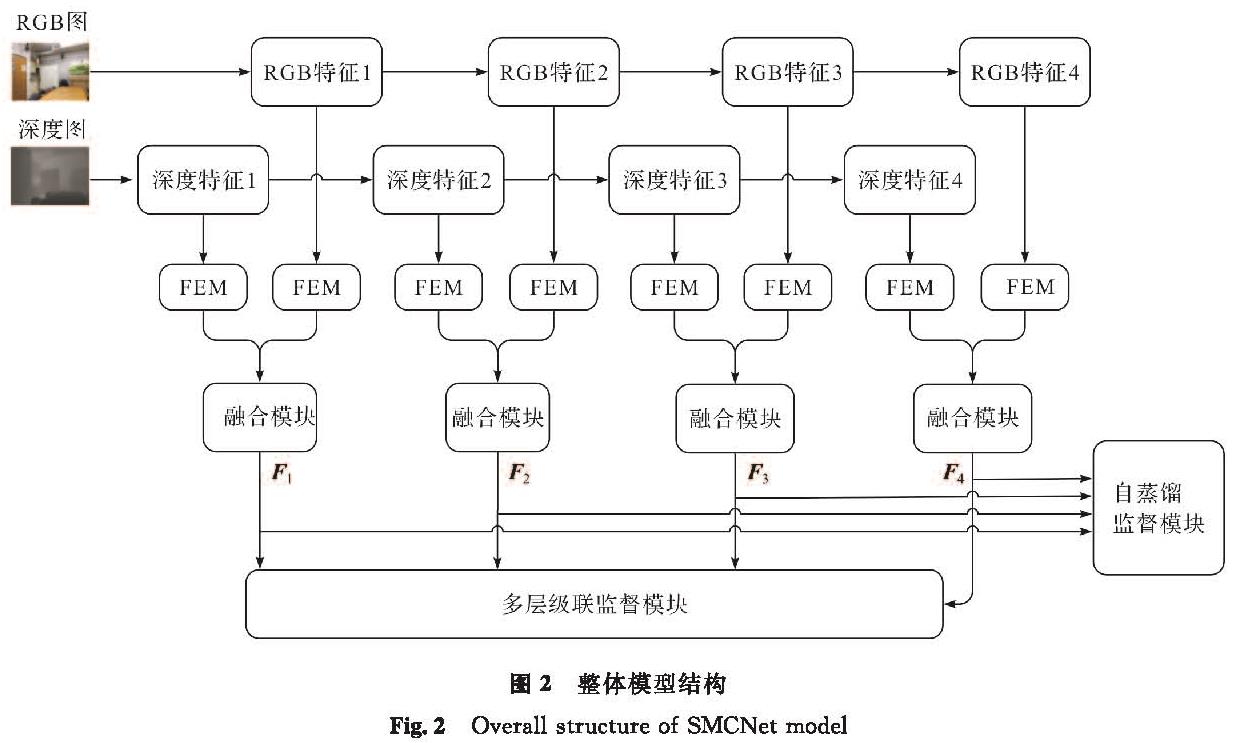
图2 整体模型结构
Fig.2 Overall structure of SMCNet model
1.3 特征增强模块和融合模块
双模态数据[19]是指将图像数据的RGB通道与另一个图像源(如深度图、热力图)结合在一起,作为网络算法的输入。引入双模态数据是为了解决单模态数据表征的局限性,从而从多个角度和方面对物体进行观测。双模态特征的信息融合旨在从不同的数据源中获取对同一物体的多重表征特征,从而提取具有鉴别性、更能表达特定物体的特征,以实现高精准度、高效率的网络训练,并提升网络性能。
早期关于双模态数据的研究相对简单,不能充分挖掘双模态数据的深层特征。因此,在双模态语义分割任务中,如何设计一种新颖且高效的研究方法就成为了一个具有挑战性的问题。为了解决这个问题,本研究提出了一个特征增强模块和一个融合模块,以便充分挖掘有效信息。特征增强模块和融合模块结构如图3所示。首先,通过通道注意力和空间注意力两种不同的注意力机制对RGB和深度特征进行处理,以获取特征中的高价值表征信息; 然后,将这两种高价值信息进行像素相加和像素相乘后,再分别与原特征进行像素相加后相乘,得到输出特征。特征增强和融合过程表示如下:
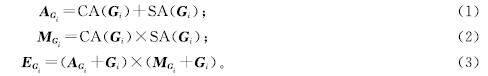
式(1)~(3)中:CA和SA分别为通道注意力和空间注意力操作; AGi和MGi分别为注意力相加、相乘后的特征; EGi为RGB特征增强后的最终特征; Gi为不同层的RGB特征,其中i为特征所处的层级。本节只展示了以RGB特征进行特征增强过程的具体步骤,而深度特征的特征增强过程与其完全相同,可将最终深度特征表示为EDi,其中D为深度特征。
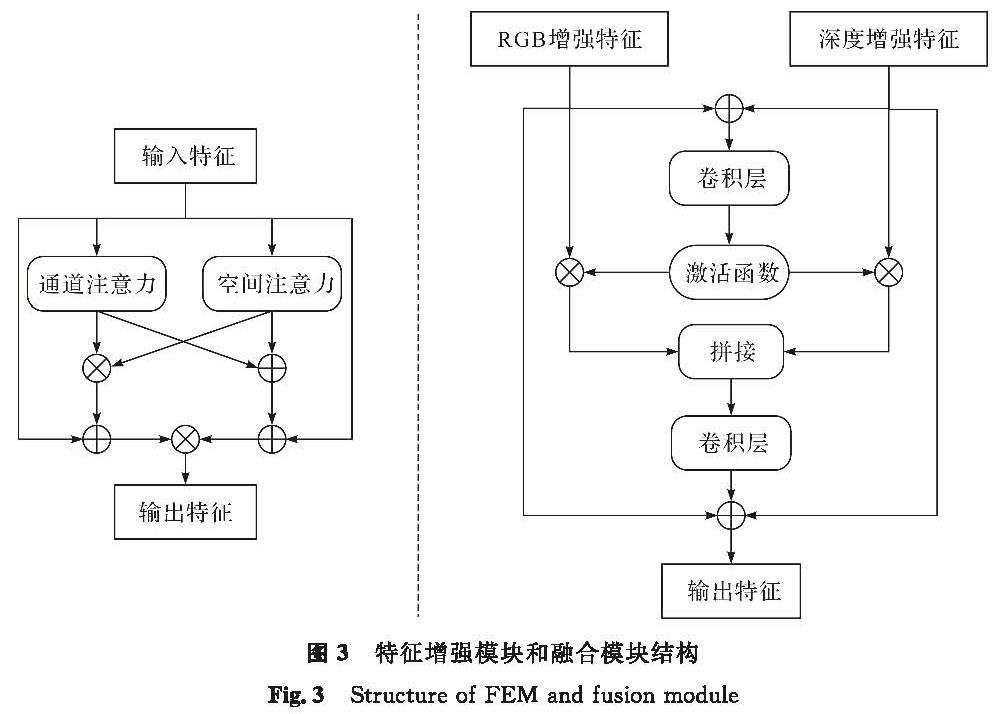
图3 特征增强模块和融合模块结构
Fig.3 Structure of FEM and fusion module
在特征增强之后,重要部分已被深入挖掘,接着需要关注的是如何融合这两种模态的特征,以实现有用信息的最大化利用。对此,本研究特别设计了一个创新的融合模块。首先,将RGB增强特征EGi和深度增强特征EDi进行像素级别的相加; 然后通过卷积层和Sigmoid激活函数进行处理,得到的权重分别与ERi和EDi相乘后,再经过拼接操作和卷积层的处理,与EGi和EDi相加后得到最终输出。融合过程表示如下:
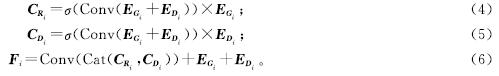
式(4)~(6)中:Conv为卷积核为3×3的卷积操作; σ为Sigmoid激活函数; Cat为沿着通道维度的拼接操作。通过融合模块最终得到了4个层面的融合输出特征Fi(i=1,2,3,4)。这些特征展现了两种模态信息在不同层次上的有效结合情况,为后续的网络训练提供了更丰富、更有鉴别力的特征表示。
1.4 自蒸馏监督模块传统的知识蒸馏方法[20]是一种有效的模型压缩技术,它通过教师网络将自身知识信息传递给学生网络,以提升学生网络的整体表现能力。自蒸馏方法则强调学生网络与教师网络的内在联系,它通过将模型自身某处的特征传递给另一处自身特征,以提升另一处特征的表现能力。低层特征的分辨率更高,包含更多位置、细节信息,但其语义信息更少,噪声更多。高层特征包含更强的语义信息,但是分辨率很低,对细节的感知能力较弱。由于低层特征将经过尺寸变换得到最终的预测图,所以将高层语义信息传递至低层特征,有利于提高低层特征的语义理解能力,从而提升模型对最终结果的预测能力。于是,本研究提出了一种自蒸馏监督模块,其结构如图4所示。首先,将4个不同层的融合特征作为输入,通过3×3卷积操作将不同通道数的特征统一到同一通道数,默认设通道数为64; 然后,将4个特征通过自适应平均池化获得分辨率相同的4个特征; 最后,采用骰子损失[21](dice loss, DiceLoss)作为自蒸馏的监督函数,将第三层的语义信息传递给第二层,第四层的语义信息传递给第一层。这样能赋予与预测图尺寸接近的低层特征更多的有价值信息,形成信息更加丰富、表征能力更强的低层特征。自蒸馏监督过程表示如下:

式(7)~(9)中:Avg为自适应平均池化操作; Dice为骰子损失; Si为统一通道数和分辨率之后的特征; l1和l2在反向传播过程中用于模型参数更新。
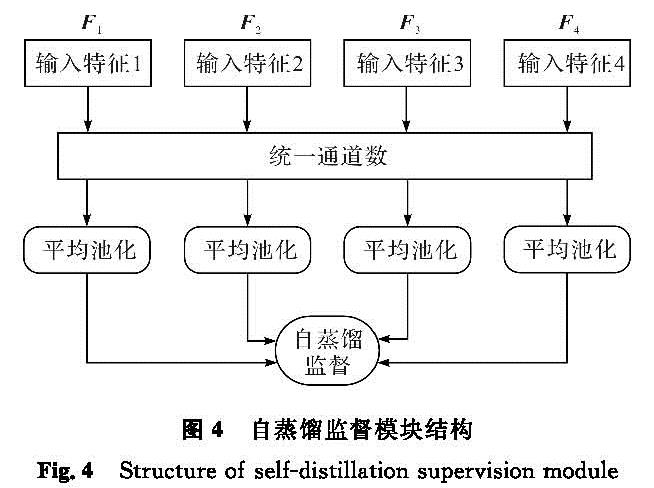
图4 自蒸馏监督模块结构
Fig.4 Structure of self-distillation supervision module
1.5 多级级联监督模块
在编码器阶段,本研究采取了一系列操作来增强双模态特征融合不同模态的特征,并实现跨层信息传递。在解码器阶段,本研究专注于构建跨层连接,并最终生成全分辨率的预测图。在传统的U形结构中,解码器部分通常仅涉及简单的逐层采样和特征融合。然而,这种结构可能导致深度学习模型的深度增加,而模型过深可能会引发反向传播的不充分,不利于参数的更新,甚至可能导致梯度消失等问题。
为了解决这个问题,本研究提出了多级级联监督模块,其结构如图5所示。首先,从最高层开始,将高层和低层的特征一起传入级联块中进行跨层信息融合; 然后,融合后的信息经过一个卷积块的处理后,再与低层特征进行像素级别的相加,生成一个侧面输出,这个侧面输出随后被用作高层特征与低层特征进一步融合的媒介; 最后,用真实值对得到的各层的侧面输出进行监督。多级级联过程表示如下:
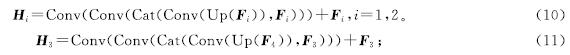
式(10)~(11)中:Up为双线性差值上采样操作。此外,图5中的尺寸变换展示了上采样与卷积层相结合的方法,用于调整特征图的尺寸。通过这种方式,获得了3个侧面输出H1、H2和H3,它们能将特征图的尺寸变换为与真实值相匹配的大小。其中,H1为最终的预测结果。为了监督这3个侧面输出,本研究采用了交叉熵损失(cross-entropy loss, CELoss)。交叉熵损失是一种常用于分类问题的损失函数,能衡量预测概率与真实标签之间的差异。通过这种监督方式,可以促进模型更好地学习和预测图像的真实值。
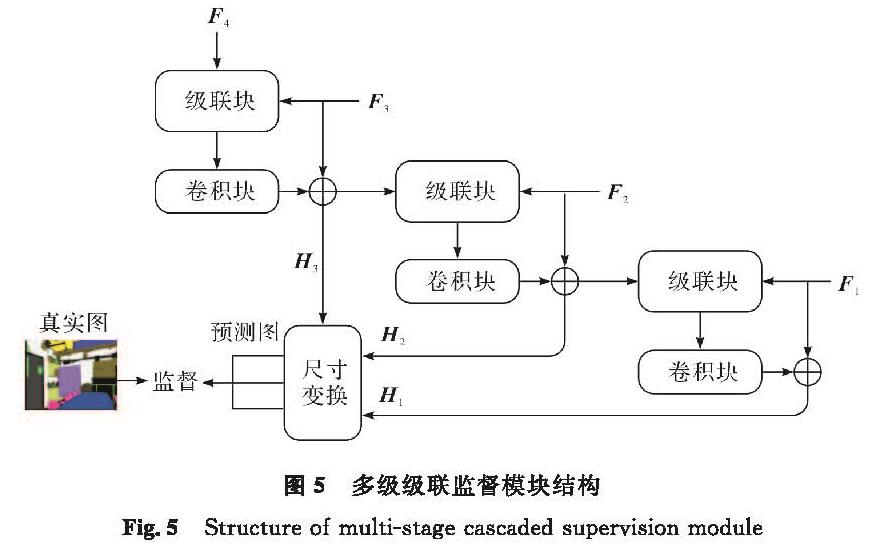
图5 多级级联监督模块结构
Fig.5 Structure of multi-stage cascaded supervision module
1.6 损失函数
在模型训练过程中,损失函数主要由两部分组成:一部分是自蒸馏监督模块的损失,它用于指导模型进行特征信息传递的操作; 另一部分则是交叉熵损失函数,它能衡量预测结果与真实标签之间的差异。
自蒸馏监督过程用到的损失函数为骰子损失,可表示如下:
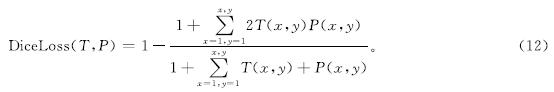
式(12)中:P为网络预测图中各像素所属类别的预测概率; T为对应输入图片的标签中各像素真实的类别。
对3幅侧面分割图的监督则用到了交叉熵损失,交叉熵函数为各像素所属的类别赋予从0到1的值,以表示预测为该类别的概率,其计算公式如下:
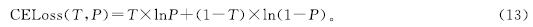
上述两种损失函数共同用于计算模型总预测与真实值之间的差距,为模型训练提供全面的监督和优化。在计算得到损失后,通过反向传播方法更新网络中各卷积层的权重,以逐步优化网络性能并实现最优的训练效果。通过这种训练方式,可以不断提高模型的准确性和鲁棒性,为室内场景解析任务提供更可靠的解决方案。
2 试验与结果2.1 数据描述本研究使用了两个数据集,分别是纽约大学深度版本2(New York University Depth version 2, NYUDv2)[22]和场景理解彩色-深度[23](scene understanding red green blue-depth, SUN RGB-D),以解决RGB-D室内场景解析问题。NYUDv2数据集包含1 449组RGB-D图像及相应的注释。这些数据被划分为795组训练图像和654组测试图像。SUN RGB-D数据集包含10 335组RGB-D图像,涵盖了37个类别,本研究选择了其中的5 285组图像进行训练,剩下的5 050组用于测试。为了确保公平比较,本研究在相同的硬件设备和试验设置下进行。所有试验均使用PyTorch框架训练模型,均在单个NVIDIA TITAN V GPU上进行训练,整个模型在单个场景的平均运行时间为51 ms。试验设置包括每次的数据批次大小为2,动量初始值为0.9,学习率设定为0.000 5,图像被裁剪为480×640像素的大小。在数据预处理阶段,使用了随机缩放、裁剪和翻转。针对NYUDv2和SUN RGB-D数据集,分别进行了300轮和200轮的训练。
2.2 评估指标为了评估本研究所提出方法的性能,试验引入了3种常用的度量标准。这些度量标准在近几年已经得到广泛的应用,能有效地评估模型的分割性能。首先,采用均值交并比(mean intersection over union, MIoU)来度量分割结果与真实标注之间的重叠程度,从而对整体分割性能进行评估; 然后,采用类别平均像素准确率(mean pixel accuracy, MPA)来更好地理解不同类别的分割表现,该度量标准分别计算每个类别中被正确分类的像素比例并求平均,以得到每个类别的平均分割精度; 最后,采用像素精度(pixel accuracy, PA)来确定每个像素点的正确分类情况,以评估分割的像素级准确性。上述度量标准的计算公式如下:
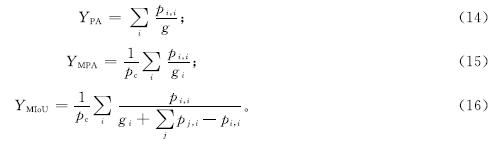
式(14)~(16)中:YPA、YMPA、YMIoU分别为像素精度、类别平均像素准确率、均值交并比; pi,j为类别i被预测为类别j的像素数; pc为总的类别数; gi为真实标签中类别i的像素数。
2.3 试验结果与分析为了验证本研究所提出的模型在双模态室内场景分割中的有效性,将其与6种经典方法进行了全面的对比,包括RedNet[7]、SGNet[8]、ShapeConv[9]、SA-Gate[11]、BCINet[12]、PGDENet[10],自蒸馏多级级联网络与其他模型的3个指标对比见表1。这些方法在不同的深度学习架构和损失函数的基础上,均展现出了各自的独特优势。
表1 自蒸馏多级级联网络与其他模型的3个指标对比
Table 1 Comparison of three indicators between SMCNet and other models%
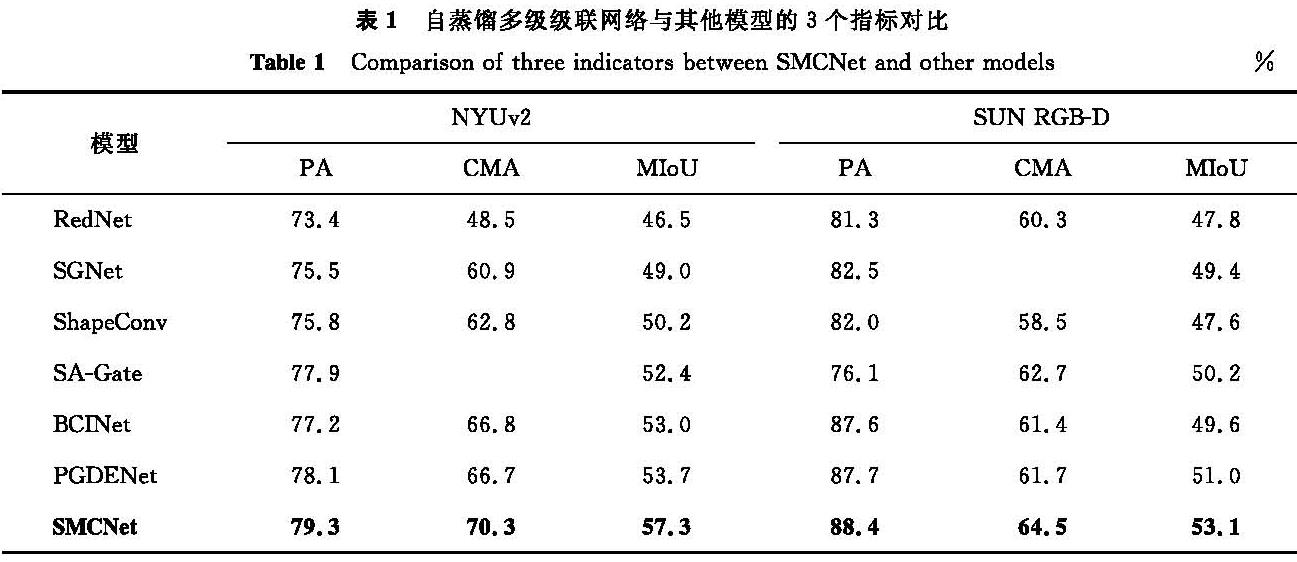
由表1可知,本研究所提出的模型在两个数据集上的各项性能指标均展现出了显著的优势。在NYUDv2数据集上,SMCNet在PA、CMA、MIoU这3个重要指标上,均明显超越了其他方法。这表明SMCNet在提高分割的像素级准确性和每个类别的分类准确性,以及整体分割性能方面均表现卓越。类似地,在SUN RGB-D数据集上,SMCNet也展现出了优良的性能。这再次证明了我们所提模型的有效性和泛化能力,即使在不同的数据集上也能展现出优良的性能。这些结果充分证明了我们所提出的模型在RGB-D室内场景分割任务中的优越性和可靠性。
为了进一步探索SMCNet的性能及其在提升室内场景解析性能方面的潜力,将其与其他领先方法进行了视觉分割分析的对比。试验结果可视化分析如图6所示。在这些比较中,无论是在物体大小还是场景相似性的处理上,SMCNet都展现出了更准确的分割结果。例如,在第一和第二行的比较中,SMCNet准确地分辨出各种物体的类别,这凸显了其强大的分类能力。而在第三行中,SMCNet能更清晰地呈现出一些边界信息,这表明其具有捕捉平滑物体细节信息的能力。这些比较表明,SMCNet不仅能精确地识别和分割类别,同时还能捕捉到平滑物体的细节信息。这一现象反映出高级语义信息和低级细节信息之间相互影响的重要性。综合来看,这些结果有力地证明了SMCNet在室内场景分割任务中的卓越性能。
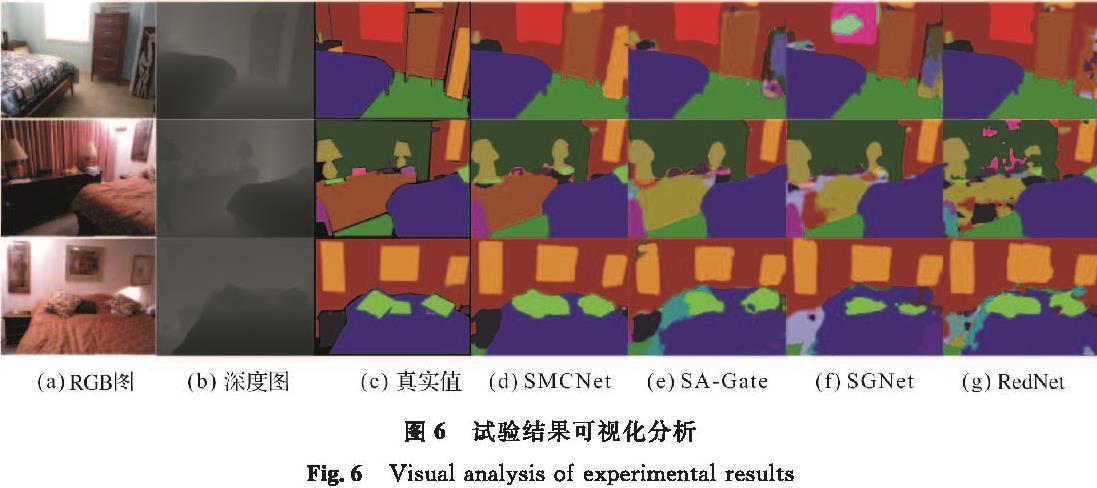
图6 试验结果可视化分析
Fig.6 Visual analysis of experimental results
2.4 消融试验
为了验证SMCNet中各个模块的有效性,本研究在NYUDv2数据集上进行了3组消融试验,分别针对特征增强模块和融合模块、自蒸馏监督模块及多级级联监督模块。自蒸馏多级级联网络消融试验对比结果见表2。首先,对特征增强模块和融合模块进行了一组消融试验,通过简单的元素相加方法替换了原有的模块; 其次,为了验证自蒸馏监督模块的有效性,直接去掉了该模块; 最后,对多级级联监督模块进行了简化处理,只保留了上采样、卷积和像素相加的操作,结果输出也只保留了最后一层的一个预测结果。
表2 自蒸馏多级级联网络消融试验对比结果
Table 2 Comparison results of SMCNet ablation experiment
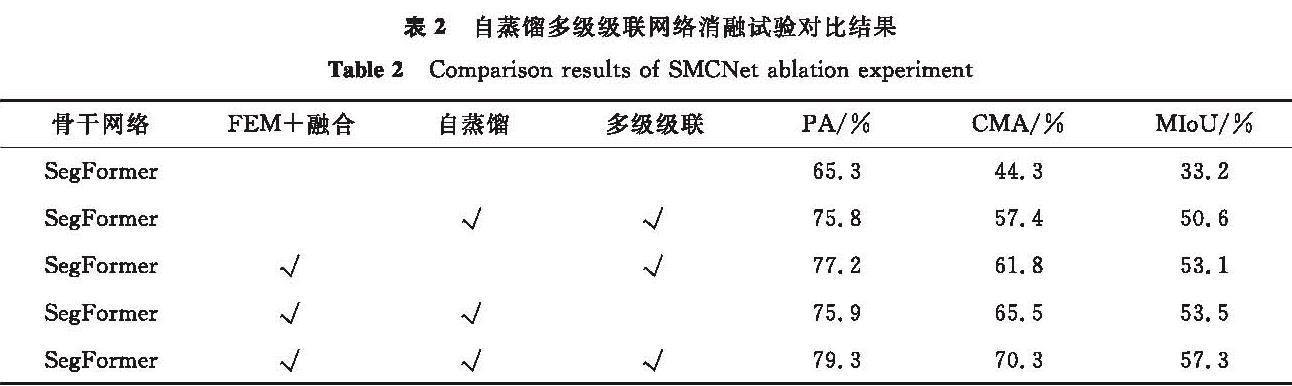
由表2可知,在去掉各个模块之后,模型的性能指标均有所下降。当移除特征增强模块和融合模块时,PA、CMA和MIoU分别下降了3.5、12.9、6.7百分点,而如果去掉自蒸馏监督模块,这3个指标将分别下降2.1、8.5、4.2百分点。此外,简化多级级联监督模块后,模型在PA、CMA和MIoU 3个指标上的性能下降了3.4、4.8、3.8百分点。这些数据充分证明了SMCNet的各个模块对模型性能的重要性。
特征增强和融合模块消融试验可视化分析如图7所示。通过将简单的像素相加方法替换原有的特征增强模块和融合模块,发现整个预测图的准确率出现了大幅的下降。对于大型物体,如门和家居等,模型的预测结果出现了较大的偏差; 同时,对小型物体的细节识别也出现了问题。这些结果表明,特征增强模块和融合模块对提高SMCNet在室内场景解析任务中的预测能力起到了关键作用。

图7 特征增强和融合模块消融试验可视化分析
Fig.7 Visual analysis of ablation experiment with FEM and fusion module
自蒸馏监督模块消融试验可视化分析如图8所示。从图8中可以观察到,在室内场景中的某个厨房场景中,当去掉自蒸馏监督模块后,模型对大型物体和厨房灶台上的小件物体的识别都出现了问题。相比之下,SMCNet在消融前能准确识别大型物体如背景和橱柜等,同时也具有出色的识别小物体的能力。这表明自蒸馏监督模块对提高模型性能起到了重要作用。此外,从这一试验结果中还可以看出充分的跨层信息融合在室内场景解析任务中的重要性。通过保留并利用不同层级的特征信息,SMCNet能更好地理解和解析图像中的各种物体,从而实现更准确的分割。因此,自蒸馏监督模块及跨层信息交互策略在提升模型性能方面具有不可忽视的作用。

图8 自蒸馏监督模块消融试验可视化分析
Fig.8 Visual analysis of ablation experiment with self-distillation supervision module
多级级联监督模块消融试验可视化分析如图9所示。从图9中可以观察到,在卧室场景中,替换掉多级级联监督模块后,模型的识别准确率明显下降。例如,枕头和背景中出现了一些错误的预测信息; 然而,SMCNet的预测结果几乎与真实值一致。这表明多级级联监督模块对提高模型的预测能力具有显著作用,能获得更清晰准确的预测图。
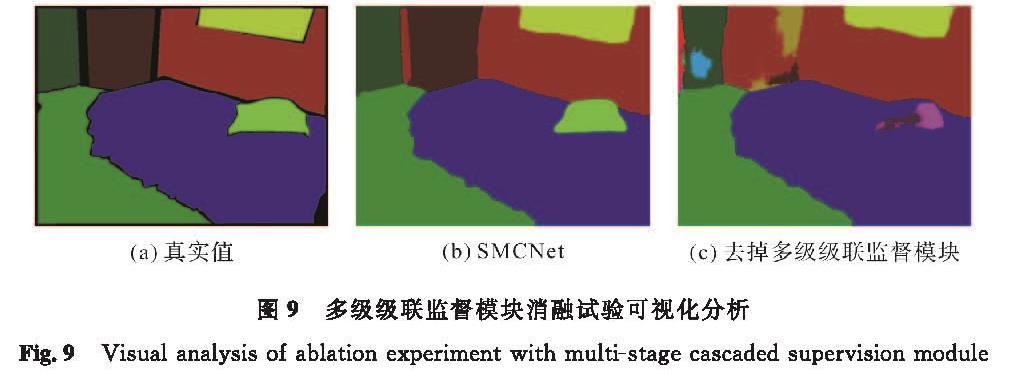
图9 多级级联监督模块消融试验可视化分析
Fig.9 Visual analysis of ablation experiment with multi-stage cascaded supervision module
3 结 语
本研究针对室内机器人在视觉信息获取方面的问题,提出了一种基于自蒸馏和双模态的SMCNet模型。SMCNet的主要创新点在于引入了特征增强模块和融合模块、自蒸馏监督模块及多级级联监督模块。在提取骨干网络的RGB和深度特征后,这些特征分别经过特征增强网络进行增强,并随后融合。融合后的特征一方面通过自蒸馏监督模块来加强模型自身不同层之间的特征交互性,另一方面通过多级级联监督模块对各级特征进行逐级传递和融合,最终得到预测图。通过这两种监督方法,模型参数的反向传播过程更加充分,从而提升了模型的整体性能。在两个室内场景公用数据集NYUDv2和SUN RGB -D上进行了对SMCNet的试验,结果表明,SMCNet在3个评估指标上都展现出了优越性能。未来,我们将继续致力于研究在昏暗或复杂的室内场景中提升模型的表现能力,为室内机器人在更多不同场景下的应用提供保障。
- [1] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(4):640.
- [2] HOPFIELD J J. Neural networks and physical systems with emergent collective computational abilities[J]. Proceedings of the National Academy of Sciences,1982,79:2554.
- [3] 姬壮伟.基于深度全卷积神经网络的图像识别研究[J].山西大同大学学报(自然科学版),2022,38(2):27.
- [4] HAZIRBAS C, MA L N, DOMOKOS C, et al. FuseNet:incorporating depth into semantic segmentation via fusion-based CNN architecture[C]//Asian Conference on Computer Vision. Taipei:Springer,2017:213.
- [5] YANG E, ZHOU W J, QIAN X H, et al. MGCNet:multilevel gated collaborative network for RGB-D semantic segmentation of indoor scene[J]. IEEE Signal Processing Letters,2022,29:2567.
- [6] WU P, GUO R Z, TONG X Z, et al. Link-RGBD:cross-guided feature fusion network for RGBD semantic segmentation[J]. IEEE Sensors Journal,2022,22(24):24161.
- [7] JIANG J D, ZHENG L N, LUO F, et al. RedNet:residual encoder-decoder network for indoor RGB-D semantic segmentation[EB/OL].(2018-08-06)[2023-10-25]. https://arxiv.org/abs/1806.01054.
- [8] CHEN L Z, LIN Z, WANG Z Q, et al. Spatial information guided convolution for real-time RGBD semantic segmentation[J]. IEEE Transactions on Image Processing, 2021,30:2313.
- [9] CAO J M, LENG H C, LISCHINSKI D, et al. ShapeConv:shape-aware convolutional layer for indoor RGB-D semantic segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. Montreal:IEEE, 2021:7088.
- [10] ZHOU W J, YANG E Q, LEI J S, et al. PGDENet:progressive guided fusion and depth enhancement network for RGB-D indoor scene parsing[J]. IEEE Transactions on Multimedia,2022,25:3483.
- [11] CHEN X K, LIN K Y, WANG J B, et al. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation[C]//European Conference on Computer Vision. Glasgow:Springer,2020:561.
- [12] ZHOU W, YUE Y, FANG M, et al. BCINet:bilateral cross-modal interaction network for indoor scene understanding in RGB-D images[J]. Information Fusion,2023,94:32.
- [13] 徐高,周武杰,叶绿.基于边界-图卷积的机器人行驶路障场景解析[J].浙江科技学院学报,2023,35(5):402.
- [14] 李成豪,张静,胡莉,等.基于多尺度感受野融合的小目标检测算法[J].计算机工程与应用,2022,58(12):177.
- [15] ZHANG L F, BAO C L, MA K. Self-distillation:owards efficient and compact neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,44(8):4388.
- [16] 郑云飞,王晓兵,张雄伟,等.基于金字塔知识的自蒸馏HRNet目标分割方法[J].电子学报,2023,51(3):746.
- [17] AN S, LIAO Q M, LU Z Q, et al. Efficient semantic segmentation via self-attention and self-distillation[J]. IEEE Transactions on Intelligent Transportation Systems,2022,23(9):15256.
- [18] XIE E Z, WANG W H, YU Z D, et al. SegFormer:simple and efficient design for semantic segmentation with transformers[J]. Advances in Neural Information Processing Systems,2021,34:12077.
- [19] WANG Y K, HUANG W B, SUN F C, et al. Deep multimodal fusion by channel exchanging[C]//Conferences on Neural Information Processing Systems. Vancouver:NeurIPS, 2020:4835.
- [20] HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL].(2015-03-09)[2023-10-25]. https://arxiv.org/abs/1503.02531.
- [21] MILLETARI F, NAVAB N, AHMADI S A. V-Net:fully convolutional neural networks for volumetric medical image segmentation[C]//2016 Fourth International Conference on 3D Vision. Stanford:IEEE,2016:565.
- [22] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from rgbd images[C]//Conference on Computer Vision. Florence:Springer,2012:746.
- [23] XIAO J X, OWENS A, TORRALBA A. Sun3D:a database of big spaces reconstructed using SfM and object labels[C]//International Conference on Computer Vision. Sydney:IEEE,2013:1625.