 图 1 原始YOLOv8n模型网络结构
Fig.1 Original YOLOv8n model network structure
图 1 原始YOLOv8n模型网络结构
Fig.1 Original YOLOv8n model network structure
ZHANG Zhangxiang,CHEN Ning.Improved YOLOv8n vehicle recognition algorithm under complex circumstances[J].Journal of Zhejiang University of Science and Technology,2024,36(05):404-416.[doi:10.3969/j.issn.2097-5236.2024.05.006]

在多变的气候和光线条件下维持识别不同尺寸和形态的车辆的准确性,以及在复杂背景下减少误检是自动驾驶车辆面临的诸多挑战。为了应对这些挑战,迫切需要提高车辆识别系统在各种环境下的适应性和精度。
车辆识别技术在智能交通、自动驾驶等应用场景中具有重要作用。近年来,国内外研究者围绕YOLO(you only look once)系列模型的优化,在车辆识别领域取得了显著进展。研究主要集中在网络架构轻量化设计、复杂场景的适应性及小目标检测等方面,并取得了显著成果。
在轻量化设计方面,车辆识别应用对计算资源和实时性的要求不断提升。郑玉珩等[1]提出了一种融合YOLOv4和MobileViT的轻量级车辆检测模型,通过大幅减少模型参数,在维持较高检测精度的同时提升了计算效率。这类轻量化模型的设计对资源受限的嵌入式系统或边缘设备尤为重要。Dong等[2]对YOLOv5的轻量化改进在特定场景下实现了更高的检测精度,展示了轻量化网络在实际应用中的广泛潜力,尤其在自动驾驶车辆检测与识别任务中的重要作用。在实时性和处理效率方面,自动驾驶和智能交通系统中车辆检测对速度的要求也在不断提高,高效模型的设计成为必然趋势。郭宇阳等[3]提出的 GS-YOLOvX 算法,通过优化内存使用和加快处理速度,实现了高效的实时车辆识别,使其能够在复杂的交通场景中实时应用。刘浩翰等[4]对YOLOv7-tiny模型的改进,增强其在多种环境条件下的泛化能力,确保了车辆检测系统在高密度交通环境下能够快速、准确地检测目标。
针对复杂场景中的检测能力,尤其在光照不足、遮挡严重的情况下,提升模型的鲁棒性和检测精度是关键。研究者通过对YOLOv8架构的优化,提出了多种增强复杂场景适应性的策略。周飞等[5]通过引入基于相似性的注意力机制模块,提升YOLOv8在处理复杂背景下的检测精度和处理速度,这对夜间驾驶、恶劣天气或遮挡等场景中的车辆检测特别重要; 张利丰等[6]设计的RBT-YOLO模型在减小模型体积的同时,仍保持了优异的检测性能,能够在计算资源有限的设备上应对复杂车辆识别任务的能力。
小目标检测方面,自动驾驶和城市交通监控等场景中,检测远距离或被部分遮挡车辆是一大挑战。Zheng等[7]通过改进YOLOv8,提升全景图像中小目标车辆的检测精度; Niu等[8]结合上下文引导和深度残差学习,增强了模型在复杂场景中识别小目标车辆的能力,提升对远距离车辆和非机动车的检测效果; Liu等[9]提出的级联融合策略进一步增强了YOLOv8n模型在多尺度目标检测中的性能,使小目标车辆的语义和位置信息提取更精准; Li等[10]通过将双向特征金字塔(bidirectional feature pyramid network,BiFPN)和简单注意力模块(simple attention module,SimAM)整合至YOLOv8架构中,提升了多尺度车辆的检测精度,特别是对小目标车辆的检测效果对智能交通系统中的实时交通监控应用具有重要意义。尽管近期这些研究在车辆识别技术方面取得了显著进展,但在处理高背景噪声、目标遮挡和不利光照等复杂环境条件时,上述方法仍面临挑战,这些挑战表明当前车辆识别技术在复杂交通场景中的不足。
为应对上述问题,本研究提出了一种改进的YOLOv8n模型,命名为DB -YOLOv8n(deformable block YOLOv8n),采用三项关键技术策略以提高模型性能,特别针对城市交通的多样性和复杂性。
1 方 法1.1 YOLOv8的改进模型YOLOv8是目标检测领域的一大进步,它继承并优化了YOLOv5的架构,融合多项创新技术以提升性能与适应性。该模型推出多个版本(YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x),以满足不同的计算资源和精度需求。YOLOv8突出自适应图像缩放和马赛克数据增强,以保障在多样化输入下的性能稳定。主干网络主要用于提升特征提取的效率和精度; 颈部结合路径聚合网络与特征金字塔网络,以有效整合不同层次的特征,增强目标识别能力; 头部采用分离头结构,特别强化对细小目标的检测。YOLOv8n版本在保证高精度的前提下,进一步优化了参数量和计算效率,适用于计算资源受限的场景。原始YOLOv8n 模型的网络结构如图1所示。
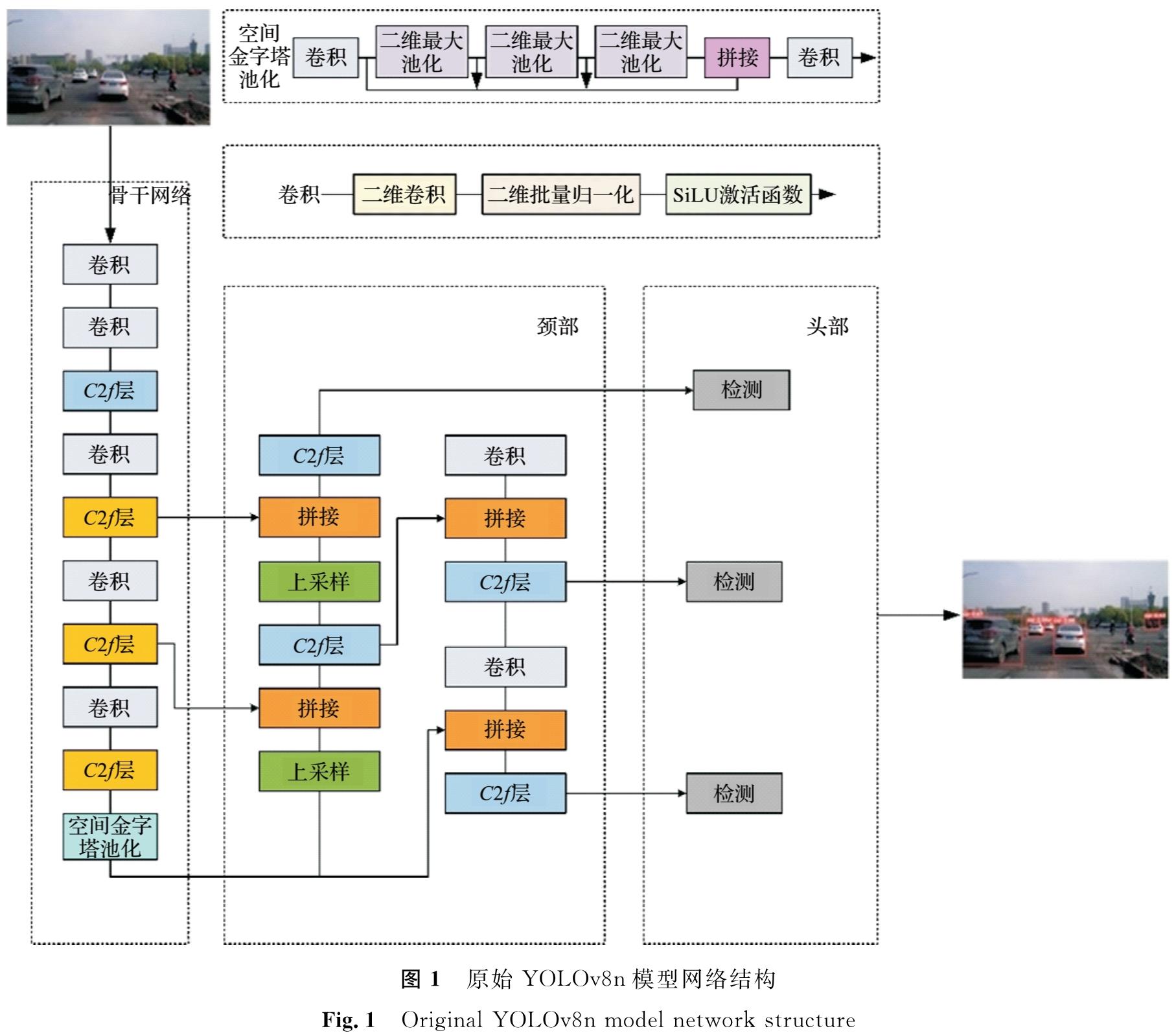
图1 原始YOLOv8n模型网络结构
Fig.1 Original YOLOv8n model network structure
在本研究中车辆识别模型选择YOLOv8n作为基础模型,并针对自动驾驶场景中小型车辆识别的需求,实施了3项改进:
1)针对图像中远距离不同尺寸和类型的车辆,将可变形卷积(deformable convolutional networks,DCN)融合到主干网络中的第5、7、9层,使提取的特征与车辆的实际形状接近,卷积区域能够始终覆盖在车辆形状周围,以增强模型对不同尺寸车辆的适应性。
2)为了改善低光照环境下的目标特征识别能力,在颈部分12、15、16、18、22、24、26层分别融合通道注意力(efficient channel attention,ECA)和改进的BiFPN,提升模型对关键目标特征的捕捉能力和强化特征融合的效果。此外,BiFPN与P2层的结合,优化模型对多尺度信息的处理能力,进一步提升车辆检测的精度。
3)引入精确边界框回归的高效交并比损失函数(focal and efficient intersection over union loss, Focal-EIOU loss),代替传统损失函数,提高模型对复杂样本的学习效率,从而在整体上提高检测的精度和泛化能力。
这些综合性的改进显著提升了模型在自动驾驶领域的车辆检测性能。DB -YOLOv8n模型网络结构如图2所示。
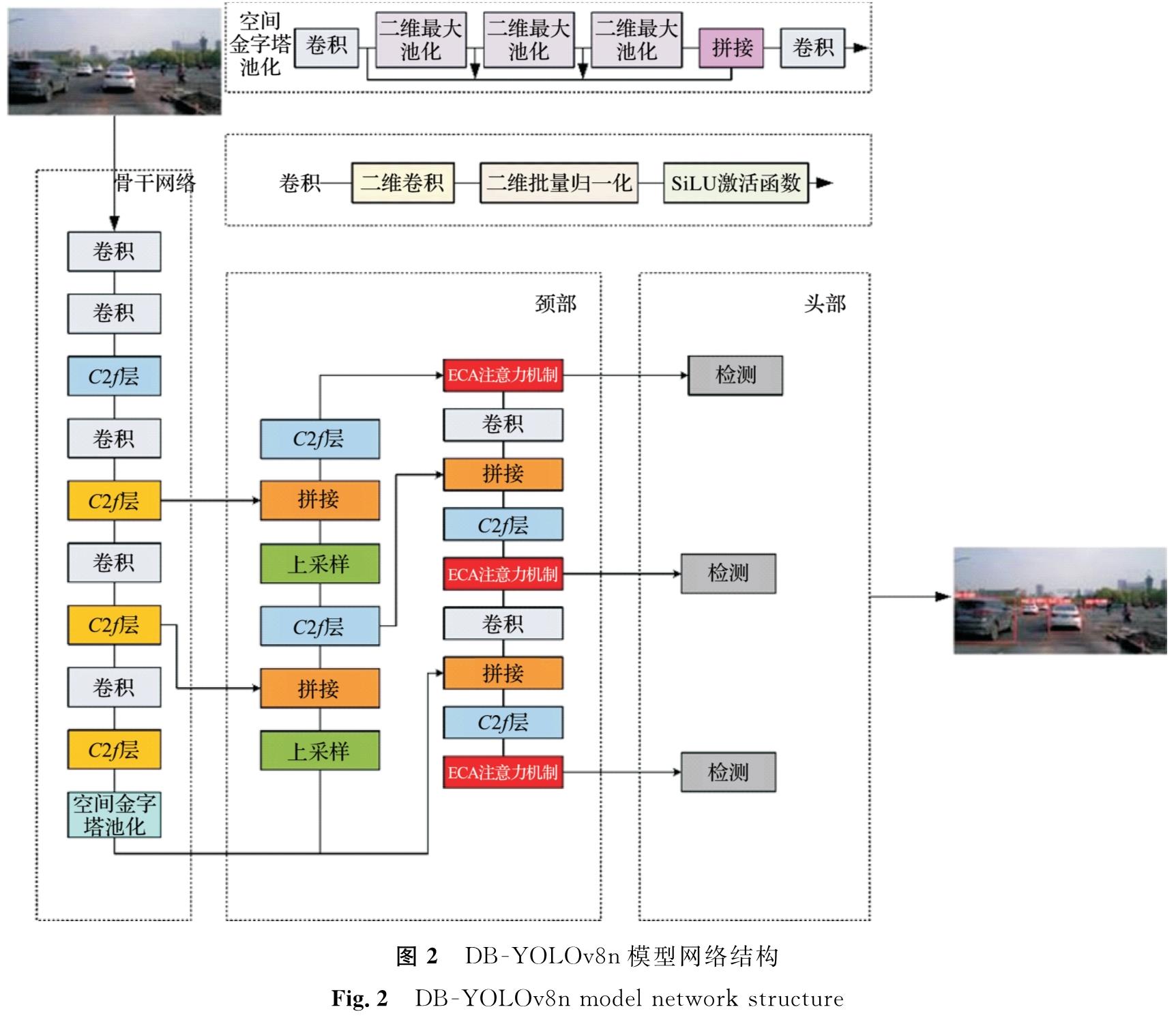
图2 DB -YOLOv8n模型网络结构
Fig.2 DB -YOLOv8n model network structure
1.2 可变性卷积模块
DCN模块是本研究的重点之一,其核心在于可变形卷积,能有效适应目标物体的形状和姿态变化。传统卷积和可变形卷积对比如图3所示,它展示了3×3的正常卷积与可变形卷积的采样点对比,其中可变形卷积通过在标准采样点上添加位移量(蓝色箭头)来实现动态调整,使卷积核能自动适应尺度变换、比例变换和旋转变换。我们进一步优化了DCN,通过引入更精细的调制机制,提高对车辆特征捕捉的灵敏度和准确性情况,使网络能更深入地理解物体的结构和几何变化,特别是在处理各种角度和距离情况下车辆形状扭曲时,能显著提高检测的鲁棒性和准确性。
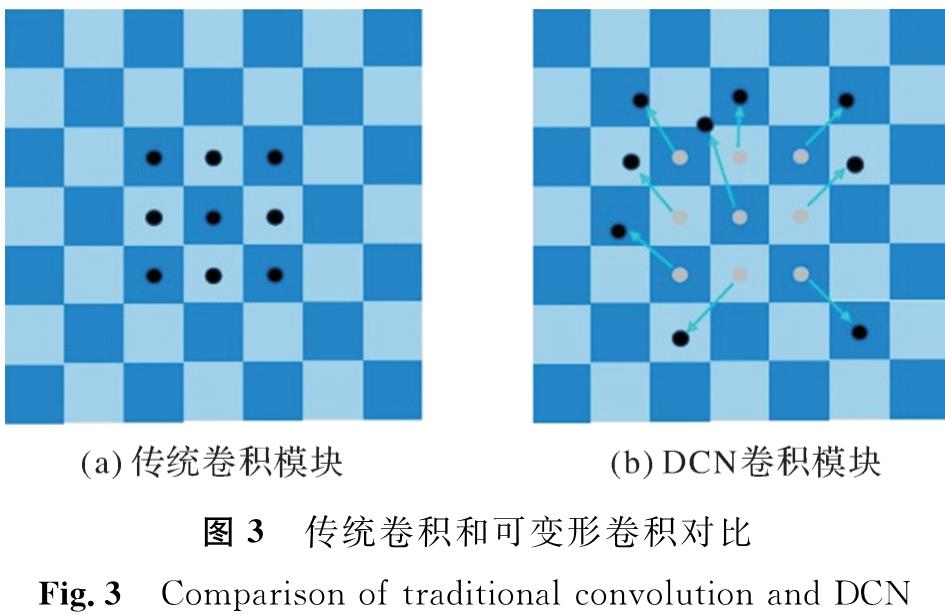
图3 传统卷积和可变形卷积对比
Fig.3 Comparison of traditional convolution and DCN
DCN卷积原理解释如图4所示,图中N为卷积核的采样点数。在DCNv1模型中,虽然空洞卷积扩展了感知范围,但也导致了参数数量的增加,这可能会使模型变得更复杂,增加内存使用,并且训练与推理阶段需要更多计算资源。设定一个包含K个采样点的卷积核,其中采样点k的权重和偏移量分别用wk和pk表示,例如,对于K=9,设定pk的值为{( -1,-1),(-1,0), …,(1,1)},构成一个3×3的卷积核。xp和yp分别为在输入和输出特征图上位置p的特征值。在只学习了偏移函数情况下,可调制的可变形卷积可以表示如下:
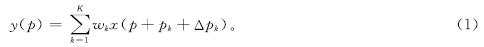
式(1)中:wk为第k个采样点的权重; x表示输入特征图; pk为第k个采样点相对于位置p的偏移; Δpk为第k个采样位置的可学习偏移量。
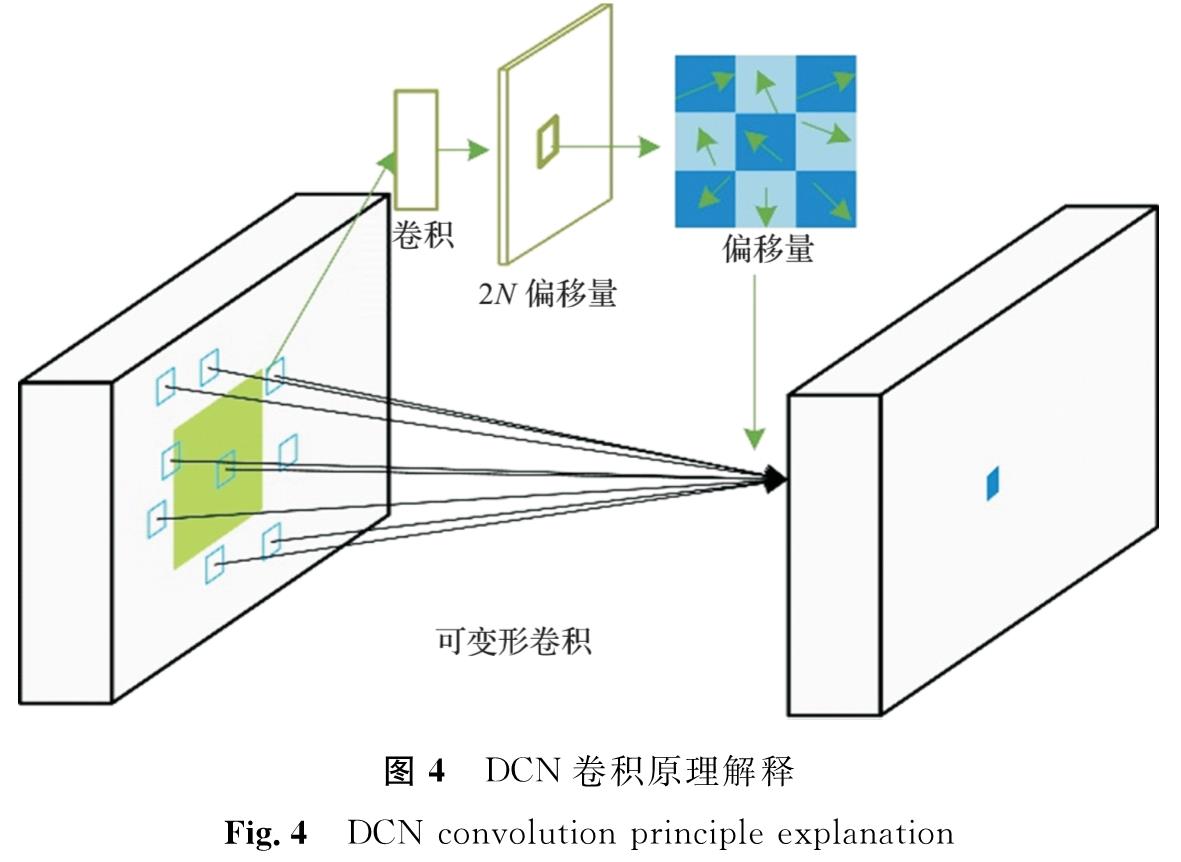
图4 DCN卷积原理解释
Fig.4 DCN convolution principle explanation
与DCNV1中固定的空洞卷积率不同,DCNV2引入了可变的空洞卷积率[11]。这意味着DCNV2中,可以在不同的层级和感受野上使用不同的空洞卷积率。通过灵活调整空洞卷积率,DCNV2可以更好地捕捉和整合不同尺度的上下文信息,从而提高模型对不同尺度特征的表示能力。因此通过为每个采样点引入可学习的卷积权重,改进后的DCN可以在卷积过程中动态调整权重,使模型更灵活地适应不同位置的特征,从而提高对复杂场景和不同尺度目标的检测能力。改进的DCN表示如下:
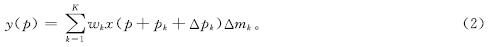
式(2)中:Δmk为可变形卷积网络中引入的额外参数,用来调节采样点的权重强度。
调制因子Δmk的值被限制在[0,1],而Δpk为一个不受限制的实数值。因为p+pk+Δpk可能是一个分数位置,所以在计算输入特征映射x时,采用了双线性插值来处理p+pk+Δpk。这两个参数都是通过对输入特征映射x应用独立的卷积层得到的,该卷积层的空间分辨率和膨胀率与当前卷积层相同。输出层有3K个通道,前2K个通道代表学习到的偏移量Δpk,余下的K个通道通过Sigmoid层处理后,产生调制因子Δmk。在这个特定的卷积层中,卷积核的初始权重设为零,因此Δpk和Δmk的初始值分别设为0和0.5。为了学习偏移和调制参数,额外的卷积层的学习速率被设置为现有层的十分之一。通过在标准卷积中引入可学习的位移,DCN增强了模型的适应性和性能,能适应目标的形状变化。在车辆检测中,这意味着网络可以更灵活地处理由于不同角度或距离远近造成的车辆形状扭曲。
1.3 通道注意力模块ECA的核心思想是在卷积操作中引入通道注意力机制,以捕捉不同通道之间的关系,从而提升特征表示的能力。通道注意力机制的目标是自适应调整通道特征的权重,使网络可以更好地关注重要的特征,抑制不重要的特征。通过这种机制,ECA能在不增加过多参数和计算成本的情况下有效地增强网络的表征能力。
ECA注意力机制原理如图5所示,其中,H、W、C分别为特征图的高度、宽度、通道数(即特征图的深度),GAP为全局平均池化,σ为激活函数或非线性变换,x^-为输出特征图。ECA机制[12]是一种高效的通道注意力方法,它通过使用一维卷积代替传统压缩和激励网络机制中的全连接层来减轻模型的复杂性。ECA机制首先对特征图的每个通道执行全局平均池化,随后通过一维卷积自动确定跨通道交流的范围。一维卷积核尺寸k与通道数C之间成正比,在确保模型的轻量化同时,还能有效捕捉通道间的依赖。卷积核大小k与通道数C关系如下:

式(3)中:γ为缩放参数,通常取2; b为偏移量,通常取1; odd表示向上取最近的奇数。
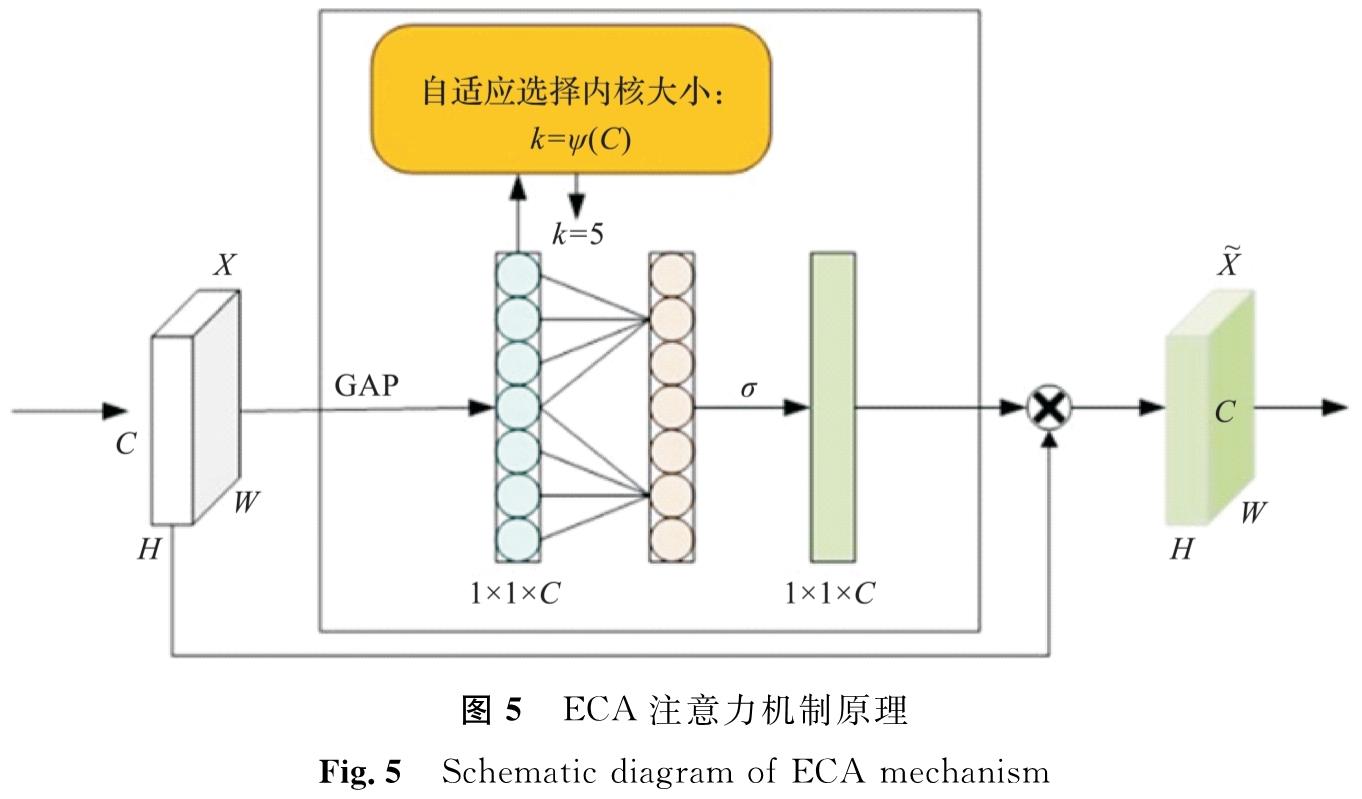
图5 ECA注意力机制原理
Fig.5 Schematic diagram of ECA mechanism
这种策略在只增加少量参数的同时能显著提升性能,尤其是在检测易被忽视的小目标(如较远距离的车辆)时表现出色。ECA模块利用一维卷积核来捕捉跨通道的重要特征,强调那些对车辆检测更关键的信息。这对在城市街景中的车辆检测尤其有用,其原因是背景可能更复杂,车辆可能远离或部分被遮挡。
1.4 改进BiFPN结构的特征融合在YOLOv8中,融合层主要由特征金字塔(feature pyramid network,FPN)路径聚合网络(path aggregation network,PAN)结构组成,然而不同主干网络输出的分辨率及其在融合时的贡献度存在不一致性。特征金字塔[13]通过建立自上而下的融合路径,实现了图像语义信息与特征信息的有效结合,但受限于信息流动的单一方向。路径聚合网络[14]结构中,浅层特征和高层语义信息通过求和操作直接融合,导致特征融合效果不佳。一些节点仅从单一节点获取输入,这增加了参数数量并导致效率低。为提高模型效率,本研究引入BiFPN[15]作为特征融合模块,并对其进行改进。改进后的BiFPN结构如图6所示,图中,C3、C4、C5为输入特征层,P3、P4、P5为由输入特征层C3、C4、C5经过双向特征金字塔网络处理后得到的特征图。

图6 改进的BiFPN结构
Fig.6 Improved BiFPN structure
特征信息由交叉阶段部分网络(cross stage partial darknet,CSPDarknet)提取并传递到改进的BiFPN进行特征融合。原始BiFPN的输入为5层,而改进的BiFPN设计了3层多尺度特征映射输入,以适应YOLOv8骨干网络的输出。BiFPN采用了一种带权重的特征融合机制,权重信息在所有特征层之间共享,每层的贡献度清晰,确保网络在训练过程中能逐步学习到每个输入特征的重要性。原始BiFPN使用了深度分离卷积,导致深度卷积层数增加,从而引起梯度信息的重复计算问题。BiFPN中堆叠的普通卷积层无法有效解决这一问题。因此,普通卷积被替换为跨阶段部分网络模块(cross stage partial network,CSP)。CSP模块在不增加计算工作量的前提下,能有效缓解梯度信息的重复计算问题,同时保持改进的BiFPN的性能。
综上所述,BiFPN和改进的BiFPN之间存在两个主要区别:第一,改进BiFPN设计为3层输入; 第二,设计了CSP模块替代普通卷积。改进的BiFPN在保持高效特征融合的同时,显著提升了网络的检测性能。
1.5 Focal EIOU损失函数在YOLOv8n中,边界框回归的损失函数是核心组成部分。EIOU损失函数在处理预测框与实际框之间的尺寸比例、中心距离和覆盖区域时效果显著,提升了定位精度,但在小尺寸和质量较低的标注框处理上存在局限。为此,引入了LFocal-EIOU损失函数,它融合了焦点损失与增强的交并比损失,以更精准地衡量预测框与实际框间的偏差。焦点损失主要针对类别不均衡问题,通过减小对易分样本的关注,加大对难分样本的重视。引入LFocal-EIOU损失函数后,模型对复杂场景下的目标检测精度提升,加强了对困难样本的识别能力,进而提高了模型的泛化性能。这种整合,使得YOLOv8模型在面对多样化问题时性能更优越。LEIOU定义如下:
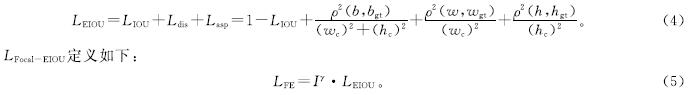
式(4)~(5)中:LIOU为IOU损失; Ldis为距离损失; Lasp为纵横比损失; wc和hc为覆盖两个框的最小包围框的宽度和高度; b为预测框中心点; bgt为真实框中心点; w为预测框宽度; wgt为真实框宽度; h为预测框高度; hgt为真实框高度; γ为控制异常值抑制程度的参数; I为IOU损失。
2 试验及仿真结果2.1 DB -YOLOv8n的结构说明DB -YOLOv8n算法过程分为图像的预处理、特征提取和后期处理3个关键步骤。首先,在预处理环节,涉及调节图像大小、应用马赛克技巧增强数据和对图像执行标准化操作; 完成预处理操作后,进入主干网络阶段,此时模型负责提取图像特征并进行区域的预测; 最后,采用非极大值抑制技术对重合的边界框实行软性阈值调整和筛选,并把经过筛选的数据重新转化为图像格式,进而完成最终输出车辆的检测结果。DB -YOLOv8n算法总体结构流程图见图7,从中可以看出从输入图像到检测的整个路径,反映了DB -YOLOv8n算法在处理复杂图像数据时的高效性和准确性。
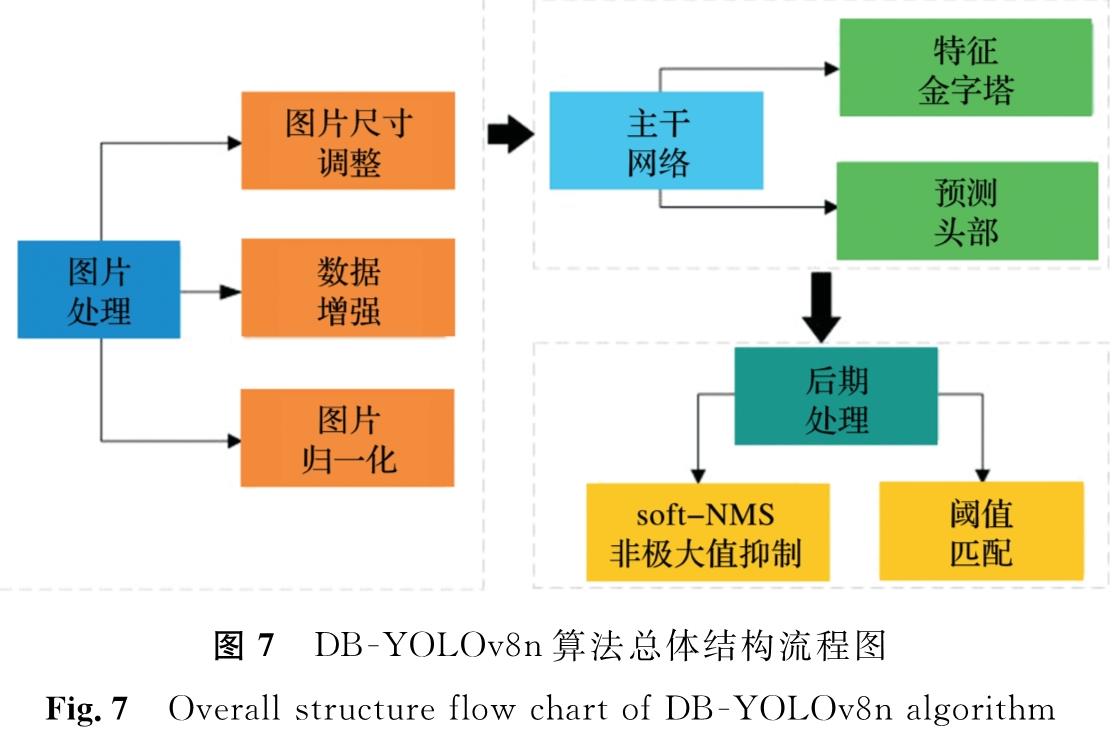
图7 DB -YOLOv8n算法总体结构流程图
Fig.7 Overall structure flow chart of DB -YOLOv8n algorithm
2.2 数据集
在自动驾驶技术的发展过程中,高效且准确的车辆检测技术对提升交通监控和自动驾驶系统的性能至关重要。为此,本研究设计并开发了一个多条件车辆检测数据集(multi-condition vehicle detection dataset, MNCD)以应对复杂的环境条件。MNCD通过杭州市多个不同地点的车载摄像头系统采集而来。这些图像拍摄于多种环境中,包括城市街道、高速公路和乡村道路,涵盖了不同的光照条件和天气情况,如晴天、雨天和夜晚。图像中不仅包含目标车辆,还包含行人、建筑物、树木、广告牌和道路标志等多种背景元素。这些复杂的背景元素和动态场景(如行驶中的车辆和过马路的行人)增加了模型检测的难度。此外,许多图像中存在车辆的部分遮挡、重叠和混杂情况。
MNCD数据集共包含约7 000张高分辨率的道路车辆图像,其中3 000张图像附有精确标注的地面真实框,用于各类车辆的识别和检测。每张图像均标记了边界框,精准定位图中车辆的位置和范围。考虑到研究的重点是车辆检测而非分类,所有不同类型的车辆在此数据集中被称为“车辆类别”。此外,我们还使用了卡尔斯鲁厄理工学院与丰田技术研究院(Karlsruhe Institute of Technology and Toyota Technological Institute,KITTI)提供的数据集,是全球主要的自动驾驶视觉算法评测数据集之一。我们选用了其中的2D目标检测数据集,并对标签进行了调整,仅保留了车辆类别。训练集和测试集分别包含7 481张和7 518张图像,我们从中选取了9 000张图像作为试验数据,通过上下翻转、水平翻转和随机裁剪扩充至16 386张。
在试验设计上,为了最大化模型的训练效果并有效地评估其性能,本试验将上述数据集按照8:2的比例划分为训练集和验证集。这种分割方式不仅提供了充足的数据支持模型训练,而且为性能验证提供了适当的测试样本,能全面评估模型在实际道路条件下的性能。
2.3 试验环境与参数配置本研究基于Ubuntu 20.04操作系统,试验环境为:深度学习框架使用PyTorch 2.0.0,编程语言版本为Python 3.8,图形加速库CUDA版本为11.8。硬件配置包括:CPU为12核的Intel(R)Xeon(R)Platinum 8352V @ 2.10 GHz; GPU为NVIDIA GeForce RTX 4090,配备24 GB显存。训练相关参数设置如下:训练轮数为200次,批量大小为16,输入分辨率为640×640像素,初始学习率为0.01,余弦退火参数为0.01,优化器采用Adam,动量设置为0.937,权重衰减系数为0.005。
2.4 评价指标为了客观评价交通场景中算法的检测性能,我们采用了精确率(fP)、召回率(fR)、平均精度(fAP)、每秒传输帧数及浮点计算次数作为评价指标。其中:精确率和召回率用于衡量模型的检测准确性和完整性,而所有类别的平均精度(fmAP)代表模型在多个类别上的检测性能,每秒传输帧数表示模型每秒内可以处理的图像数量,是评估模型检测速度的指标; 浮点计算次数是衡量模型计算复杂度的指标。

式(6)~(9)中:yTP为正确预测为正类的样本数量; yFP为错误预测为正类的样本数量; yFN为实际为正类但被错误预测为负类的样本数量; Pri为不同召回率下的精度; ri为召回率; n为类别的总数量。
2.5 消融试验对各模块进行融测试以验证其在DB -YOLOv8n中的有效性,YOLOv8n作为基线模型,DB -YOLOv8n消融试验结果见表1。
表1 DB -YOLOv8n消融试验结果
Table 1 DB -YOLOv8n ablation experiments result
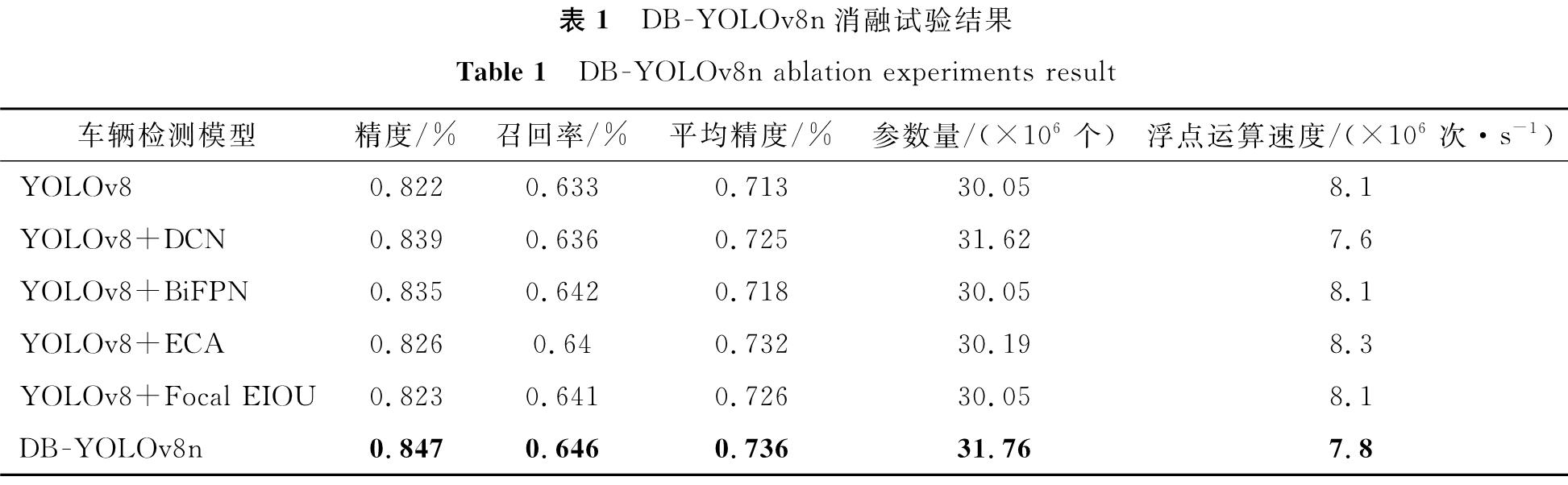
YOLOv8n框架应用DCN进行特征提取,使平均精度均值比YOLOv8模型提高了1.6%,表明DCN在复杂检测环境中能有效提取不规则的车辆特征。通过集成BiFPN,平均精度均值比基线提高了0.7%,能改进模型的特征融合能力,增强特征表示和提供更精确的对象定位和识别。从传统的LEIOU损失函数到LFocal-EIOU损失函数的转换显示出了显著的改善,与初始模型相比,平均精度均值增加了1.8%,这一修改显示了LFocal-EIOU损失函数能优化YOLOv8模型,以改进模型泛化能力。ECA注意机制加入YOLOv8模型后,平均精度均值比基线提高了2.6%,结果表明ECA能促使YOLOv8模型注意更重要的特征信息,从而提升车辆检测的性能。
最后,通过将DCN、BiFPN、ECA和Focal-EIOU集成到YOLOv8n框架中,使平均精度均值比基线模型提高了9.5%。这4种增强功能的结合大幅提高了YOLOv8车辆检测的性能,是一个能高精度检测车辆的模型。
2.6 对比试验为综合验证本研究算法的优越性,将本研究算法与目前主流的车辆检测算法进行对比试验,结果见表2。
表2 DB -YOLOv8n与主流算法对比试验结果
Table 2 Results of comparative test between DB -YOLOv8n and mainstream algorithms
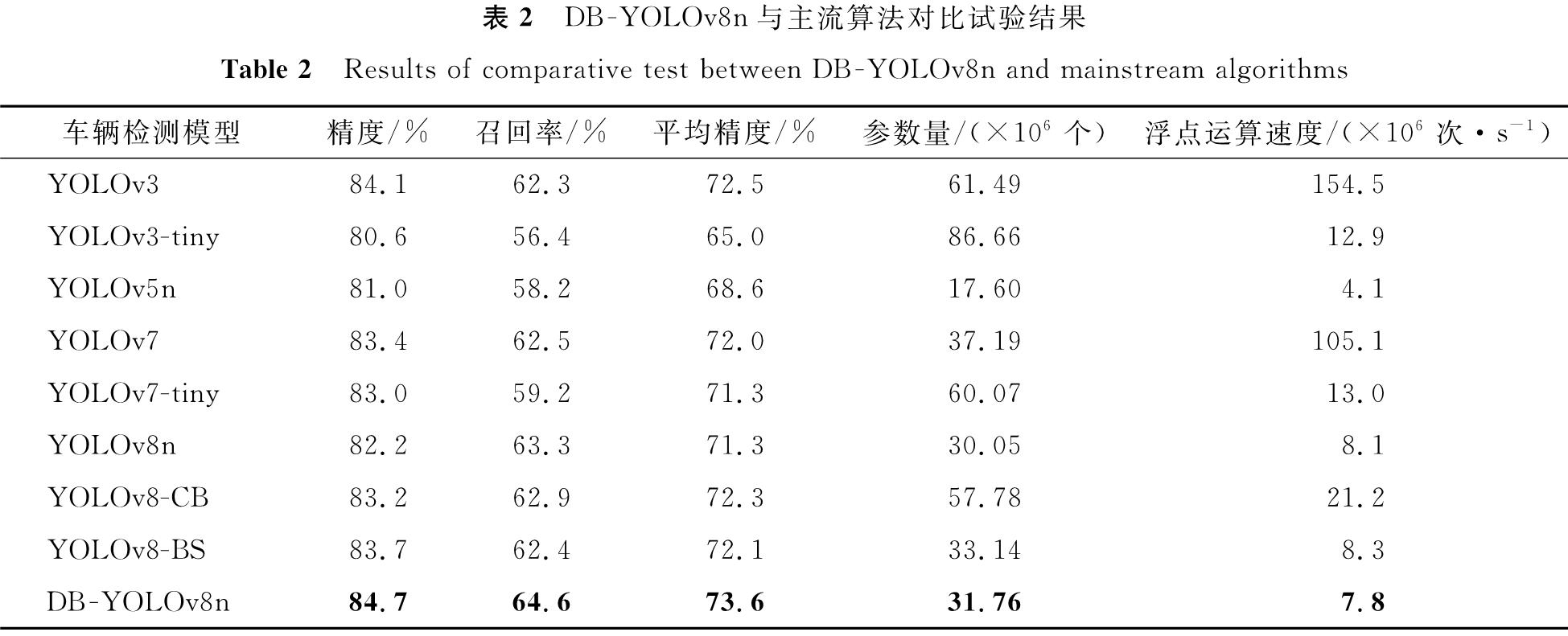
由表2可知,相较于传统YOLOv3,DB -YOLOv8n模型的各项性能显著提升,其中精度和召回率分别提高了0.71%和3.69%,而在平均精度均值指标上提升1.52%,这些数据显示了DB -YOLOv8n在算法精度方面的优势。
与YOLOv5n比较,DB -YOLOv8n在精度上实现了4.57%的提高,召回率增加了11.00%,平均精度提升了7.29%,这一显著的性能提升,特别是在复杂的检测场景中,凸显了DB -YOLOv8n的实用性和适应性,即便模型体积略有增加。
进一步对比YOLOv7及其tiny版本,DB -YOLOv8n在精度上分别提升了1.56%和2.05%,而在平均精度指标上,相较于YOLOv7和YOLOv7-tiny,分别提高了2.22%、3.23%,这一结果显示了DB -YOLOv8n在参数优化和性能提升方面的双重优势。
与YOLOv8模型对比,DB -YOLOv8n在精度上提高了3.04%,召回率提高了2.05%,在平均精度均值指标上分别提升了3.23%。这表明DB -YOLOv8n能在参数稍增加条件下显著提高车辆检测性能,特别是在处理复杂和挑战性的场景中。
与YOLOv8-CB和YOLOv8-BS模型相比,DB -YOLOv8n在精度、召回率及平均精度均值指标上均表现出显著的优势,不仅提供了更高的检测精度,还在处理复杂场景和多样化车辆类型时展现了较强的鲁棒性和较高的准确性。
尽管本研究算法DB -YOLOv8n在多方面表现优秀,但其在特定车辆检测任务中仍存在局限。例如,在远距离车辆检测中,由于车辆在图像中的位置较远,可变形卷积的特征提取能力可能受限,从而影响了识别准确性。在图像模糊、光照强烈或车辆并排导致的重叠区域较大时,尽管ECA注意力机制能改善对关键特征的关注,但在处理重叠场景时的误检风险仍然存在。总体而言,与现有的主流车辆检测算法相比,DB -YOLOv8n算法在损失值、精度、召回率、以及平均精度多项指标上均表现出色。DB -YOLOv8n的各项指标检测结果如图8所示。

图8 DB -YOLOv8n的各项指标检测结果
Fig.8 Test results of various indicators of DB -YOLOv8n
为了进一步验证本研究提出的DB -YOLOv8n模型的性能,将其与KITTI上的主流算法进行了对比试验,结果见表3。
表3 DB -YOLOv8n与KITTI上的主流算法对比试验结果
Table 3 Results of comparative test between DB -YOLOv8n and mainstream algorithms in KITTI
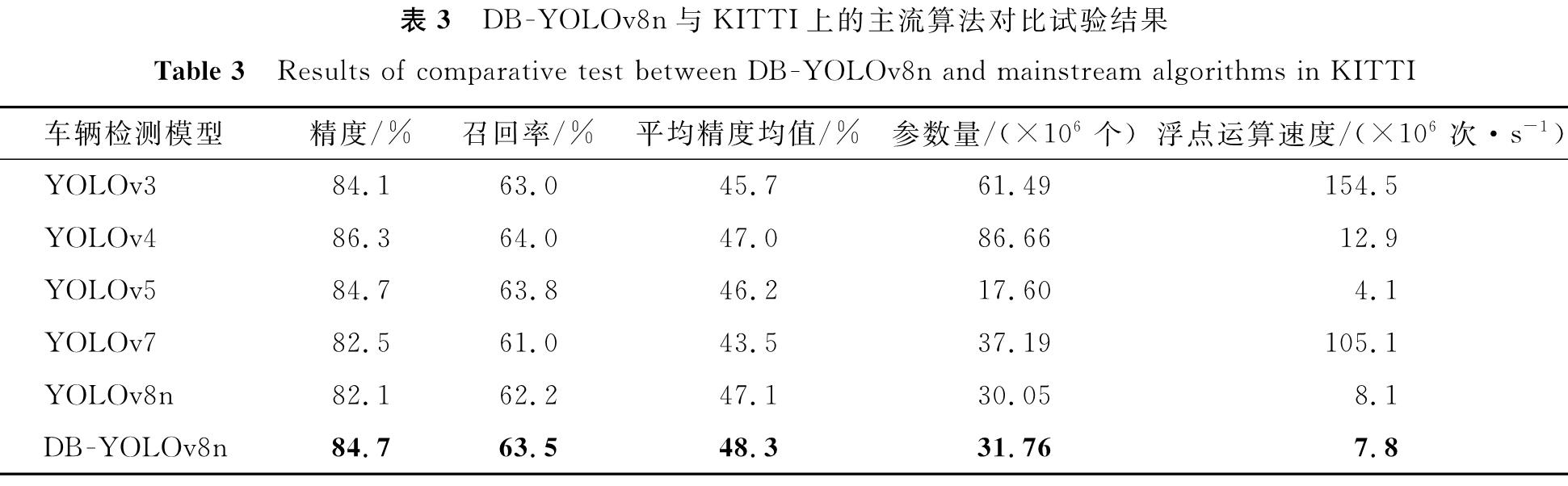
由表3可知,DB -YOLOv8n模型在KITTI数据集的性能表现优于传统的YOLOv3、YOLOv4、YOLOv5和YOLOv8模型,特别在平均精度和召回率方面。同时,DB -YOLOv8n在参数量和计算复杂度方面也展示了更优的性能。这些结果表明,本研究提出的改进方法在不同数据集上的普适性和有效性。然而本研究自制数据集的检测结果与公开数据集相比还存在一定的差距。其主要原因如下:
1)数据集特性差异。公开数据集如KITTI包含了更多的场景和背景变换,而自有数据集侧重于特定的城市环境,场景复杂度不同。
2)数据预处理方法不同。公开数据集通常经过了严格的预处理和标注,而自制数据集在标注一致性和质量上可能存在不足。
2.7 可视化结果对比DB -YOLOv8n模型与其他算法的可视化结果对比如图9所示,其中每行展示了白天街道、雾天、白天复杂路况和夜晚低光照场景识别结果。图9显示了DB -YOLOv8n在车辆检测领域中的显著优势,尤其在复杂场景,如车辆遮挡和重叠的环境下。与YOLOv7、YOLOv7-tiny、YOLOv5n、YOLOv3及YOLOv3-tiny等模型相比,DB -YOLOv8n在识别准确率和稳定性方面具有显著的提升。虽然YOLOv5n、YOLOv7-tiny和YOLOv8n在特定条件下也展现了一定的效果,但它们在处理微妙的车辆遮挡和复杂环境时,检测能力显得有限。而DB -YOLOv8n在处理这些复杂场景时显示出更高的精确度和鲁棒性,能有效地识别和区分重叠或遮挡的车辆。

图9 DB -YOLOv8n模型与其他算法的可视化结果对比
Fig.9 Comparison of visualization results between DB -YOLOv8n model and other algorithms
DB -YOLOv8n与其他算法可视化结果对比如图 10所示,展示了DB -YOLOv8n在复杂环境下的优良识别精度和增强的鲁棒性,尤其在动态背景、光线变化和目标遮挡条件下。

图 10 DB -YOLOv8n与其它算法可视化结果对比
Fig.10 Comparison of visualization results between DB -YOLOv8n and other algorithms
3 结 语
本研究针对复杂多变的环境下车辆检测效果不理想这一问题,设计了一种基于YOLOv8n的改进模型DB -YOLOv8n。该模型通过整合DCN、ECA和改进BiFPN及Focal-EIOU损失函数,提高YOLOv8n的特征提取能力和收敛速率。这一系列改进不仅极大地增强了YOLOv8n在面对多变环境和复杂背景时的稳定性和鲁棒性,而且通过在自制车辆数据集上进行的测试,证实了DB -YOLOv8n在平均精度均值上达到73.6%,较YOLOv8n增加了2.3%,精确度和召回率分别为84.7%、64.6%,分别增长2.5%、1.3%。这些关键指标的提升为极端光照条件下车辆检测的准确高效提供了强有力的保障。但改进后的算法在复杂交通场景中仍然存在一定的漏检现象。接下来将继续对算法结构进行优化,提升检测精度,特别是针对被遮挡和模糊车辆的检测。此外,还将进一步提高模型的检测速度和在移动设备上的部署能力,以实现实际驾驶环境中的实时检测。
- [1] 郑玉珩,黄德启.改进MobileViT与YOLOv4的轻量化车辆检测网络[J].电子测量技术,2023,46(2):175.
- [2] DONG X D, YAN S, DUAN C Q. A lightweight vehicles detection network model based on YOLOv5[J]. Engineering Applications of Artificial Intelligence, 2022, 113:104914.
- [3] 胡伟超,郭宇阳,张奇,等.基于改进YOLOX的轻量化交通监控目标检测算法[J].计算机工程与应用,2024,60(7):167.
- [4] 刘浩翰,樊一鸣,贺怀清,等.改进YOLOv7-tiny的目标检测轻量化模型[J].计算机工程与应用,2023,59(14):166.
- [5] 周飞,郭杜杜,王洋,等.基于改进YOLOv8的交通监控车辆检测算法[J].计算机工程与应用,2024,60(6):110.
- [6] 张利丰,田莹.改进YOLOv8的多尺度轻量型车辆目标检测算法[J].计算机工程与应用,2024,60(3):129.
- [7] ZHENG X, ZOU J, DU S, et al. Small target detection in refractive panorama surveillance based on improved YOLOv8[J]. Sensors, 2024, 24(3):819.
- [8] NIU Y, CHENG W, SHI C, et al. YOLOv8-CGRNet:a lightweight object detection network leveraging context guidance and deep residual learning[J]. Electronics, 2023, 13(1):43.
- [9] LIU Q, YE H, WANG S, et al. YOLOv8-CB:dense pedestrian detection algorithm based on In-Vehicle camera[J]. Electronics, 2024, 13(1):236.
- [10] LI N, YE T, ZHOU Z, et al. Enhanced YOLOv8 with BiFPN-SimAM for percise defect detection in miniature capacitors[J]. Applied Sciences, 2024, 14(1):429.
- [11] ZHU X Z, HU H, LIN S, et al. Deformable convnets v2:more deformable, better results[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE/CVF, 2019:9308.
- [12] WANG Q L, WU B G, ZHU P F, et al. ECA-Net:Efficient channel attention for deep convolutional neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern recognition. Seattle:IEEE/CVF, 2020:11534.
- [13] LIN T Y, DOLLáR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C] // Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu:IEEE, 2017:936.
- [14] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation [C] // Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City:IEEE/CVF, 2018:8759.
- [15] TAN M, PANG R, LE Q V. Efficientdet:scalable and efficient object detection [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle:IEEE/CVF, 2020:10781.